







-
探究是什么让跨语言预训练模型有跨语言的能力 Dissecting mBERT/XLM models
-
领域相似性 domain similarity
-
锚点 shared vocabulary (or anchor points)
锚点是在两个语言训练语料中共同出现的相同字符串(identical strings),作为跨语言共享编码器在不同语言中的纽带。
用code-switch的方法做实验,增加锚点
但是最近的研究发现,锚点在训练跨语言表示中起到非常小的作用
-
共享参数 shared parameters
甚至softmax层的参数对模型都有影响,但是和锚点参数(embedding)一样影响不大
-
语言相似性 language similarity
改变上述因素对不相似的语言影响更大
-

-
训练两个单语的bert模型去学习跨语言表达的相似性 Similarity of BERT Models
-
Aligning Monolingual BERTs
测量相似性的方法Procrustes
-
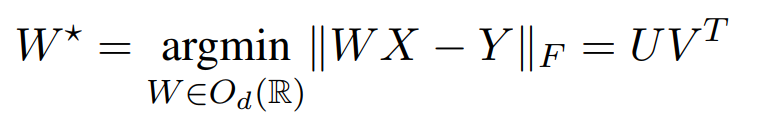
-
单语词对齐 Word-level alignment
把每个子词当作独立的输入,把所有embedding相加然后平均,每一层得到一个embedding。用muse词表进行监督学习。最后align结果比fasttext好。而且高层的representations比底层好。
-
双语词对齐 Contextual word-level alignment
we can align contextual representations of monolingual BERT models with a simple
linear mapping and use this approach for crosslingual transfer.中间层比高层representation alignment更好
-
Sentence-level alignment
pooling subword representation of sentences at each layer of monolingual BERT.
-
结论
bert在词级别和句子级别都可以通过简单的orthogonal mapping来align。
与word embedding相似,bert模型在不同语言是相似的,所以为什么仅通过共享权重就足够。
-
Neural network similarity(没怎么看)
-
CKA entered kernel alignment; CCA canonical correlation analysis
- 结论
当语言相近时,用相同的模型增加representation的相似性
相反,语言不相近时,相同模型不能增加representation相似性















 3116
3116











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









