







-
传统的dst分为两类:ontology-based和ontology-free。
-
ontology-based
在工业界可能无法把所有ontology预定义出来,即使所有的ontology存在,遍历所有值计算开销很大。
-
ontology-free
无法解决当值没有出现在对话内容中,或者用户有好几种表达这种情况
-
-
作者提出了DualStrategy Dialog State Tracking model (DS-DST)
- 利用阅读理解方法,寻找span,融合ontology-based(picklist-based)和ontology-free(span-based)
-
DS-DST: a Dual Strategy for DST 一种对偶模型
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cG6YwbUc-1614756389392)(/Users/siyulai/Library/Application Support/typora-user-images/image-20210303102211321.png)]](https://img-blog.csdnimg.cn/20210303152722581.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MTY5NjAxNQ==,size_16,color_FFFFFF,t_70)
-
Slot-Context Encode
用bert与训练模型编码domain-slot和对话内容
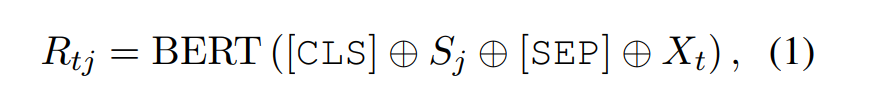
-
Slot-Gate Classification
由于domain-slot对在多领域中有很多,所以正确判断一个domain-slot对是否出现在当前对话中是非常重要的。所以作者设计了一个Slot-Gate分类器,包含三个类别{none,dontcare,prediction}
none: 表示domain-slot在这轮没有提到,或者value就是none
dontcare:表示用户可以接受这个slot的任何值
prediction:表示这个slot应该通过模型给出真实值
用 r t j c l s r^{cls}_{tj} rtjcls位预测第 j t h j_{th} jth domain-slot在 t t h t_{th} tth轮的概率分布
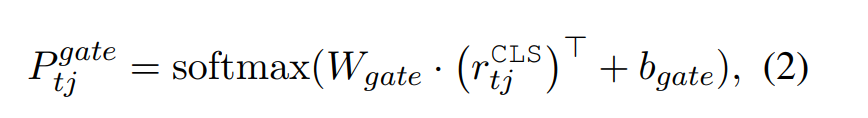
交叉熵函数计算loss值

-
Non-Categorical Slot-Value Prediction
对于未分类的slot,可以通过value在对话开始和结束的位置来确定(span)
用two-way linear mapping得到开始向量和结束向量
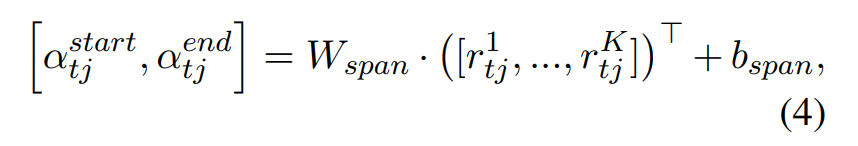
用softmax函数计算 i t h i_{th} ith个词作为开始/结束的概率 p t j s t a r t i p^{start_i}_{tj} ptjstarti
loss函数
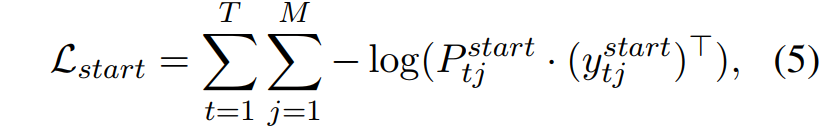
-
Categorical Slot-Value Prediction
每个Categorical Slot都有很多候选值,用bert对每个候选值编码

cosine计算aggregated representations和reference candidate value之间的相似度
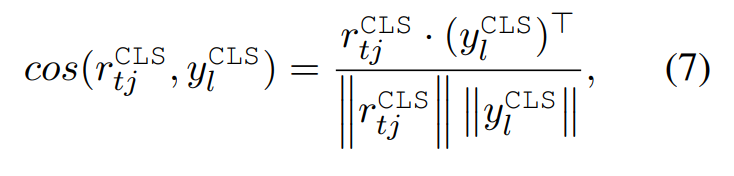
在训练阶段,使用hinge loss去扩大预测值和target之间的差异(可以参考)

-
Training Objective
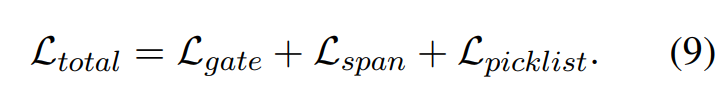
对于没有提到的slots(none)或者用户可以接受任何值(dontcare),在每轮对话设置 L s p a n L_{span} Lspan 和 L p i c k l i s t L_{picklist} Lpicklist为0
-
-
实验结果
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Mf0f2E4e-1614756389393)(/Users/siyulai/Library/Application Support/typora-user-images/image-20210303151148933.png)]](https://img-blog.csdnimg.cn/20210303152916166.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MTY5NjAxNQ==,size_16,color_FFFFFF,t_70)
DS-SPAN:把所有domain-slot对当成noncategorical slots
DS-DST:把time和number相关的slot当成non-categorical slots,剩下的categorical slots
DS-Picklist:把所有当成categorical slots
作者说虽然DS-Picklist比DS-DST准确率高,但是在现实场景,可能没有所有的ontology
作者还解释了为什么他们的模型比其他基于bert的模型效果好,比如BERT-DST,因为本篇模型对dialog context和slots之间做了很强的交互。















 568
568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









