







论文阅读:《Find or Classify Dual Strategy for Slot-Value Predictions on Multi-Domain Dialog State Tracking》
目录
背景
英文名:《Find or Classify Dual Strategy for Slot-Value Predictions on Multi-Domain Dialog State Tracking》
中文名:《多领域对话状态跟踪上槽值预测的双重策略:寻找或分类》
这篇轮文的DS-DST是今年最好的多领域任务型问答模型之一。
多领域DST大致可以分为fixed-vocabulary与open-vocabulary两大流派,两种方法各有优缺点。
fixed-vocabulary-based DST:(或predefined ontology-based方法、检索式方法),即固定词表/基于预定义本体的方法。这种方法是传统的单领域任务型问答中的传统方法。基本思想是,预定义一个所以可能的槽值的本体(ontology of possible slot values),在这个本体上运行状态跟踪(分类)机制。由于这种方法能够让系统流畅地预测那些未出现在给定对话历史中的槽值,简化任务,所以在DSTC2、WOZ 2等单领域数据集上的测试中取得了杰出的表现,但是,这种方法的缺陷也是很明显的,主要问题是死板,必须在训练阶段为每一个领域定义潜在的槽值大列表,这个是很困难的;其次,计算的复杂性会随着需要跟踪的预定义槽位数量的增加而增加;第三,难以应对unseen slot values问题。
open-vocabulary-based DST:(或open-vocabulary candidate-generation DST,生成式方法)。又名“生成式”方法,最初的思想来自SpanPtr,目的是在缺失预定义本体的情况下实现状态跟踪,并处理未知的槽值。这种方法的基本思想是基于每轮的状态(源序列)派生候选集,相当于序列生成问题。这种方法从对话历史中灵活地抽取或生成槽值,但是要努力预测出对话历史中未出现的槽值。在解决unseen slot values问题上有所成果,但是DST的运行效率低,因为它们要在每一轮对话的一开始预测对话状态。由于open-vocabulary-based DST的槽值生成思想极大解决了对本体的依赖,所以在多领域问答上大受欢迎,目前已经成为重要的研究热点。
总结而言,只要预定义的slot ontology足够好,fixed-vocabulary-based DST无限好。但是如果考虑复杂性和可扩展性,open-vocabulary-based DST更好。
这篇论文的思想是针对open-vocabulary模型的ill-formatted strings问题,想到了一种结合两种DST优势的方法,即把所有slots分成两类,对于picklist-based slots使用predefined ontology-based approach,类似SUMBT ,而对于 span-based slots, 使用span extraction-based method,类似DST Reader。
基于跨度的槽位(span-based slots )与基于选项列表的槽位( picklist-based slots):
-
基于选项列表的槽位( picklist-based slots):这种是把domain-slot pairs 看做是picklist-based slots,为其使用predefined ontology-based DST,就是在预定义的可接入本体的条件下,对每一个槽位在候选槽值的列表(candidate-value list)上运行分类算法。论文的中使用的方法类似SUMBT。
-
基于跨度的槽位(span-based slots):这种是把domain-slot pairs看做是span-based slots,在对话上下文中,对每一个槽位,通过寻找text spans来跟踪槽值(从slot span中寻找value)。slots中的values可以通过对话上下文中的起始和终止位置的span来找到。论文中使用的方法类似DSTreader。
论文中分情况具体地训练了三个模型:
• DST-Span: 类似SpanPtr,把所有domain-slot pairs看做span-based slots,其中每一个slot的对应values 被抽取,通过【带有对话上下文中的起始和结束为止text spans (字符串匹配)】
• DST-Picklist: 把所有domain-slot pairs看做picklist-based slots, 其中每一个slot的对应values在candidate-value list中找到。
• DS-DST:都有。
Related Work
DS-DST
DS-DST模型的结构如下。左侧对于picklist-based slots使用predefined ontology-based approach预测value,右侧对于span-based slots使用span extraction-based method预测value。
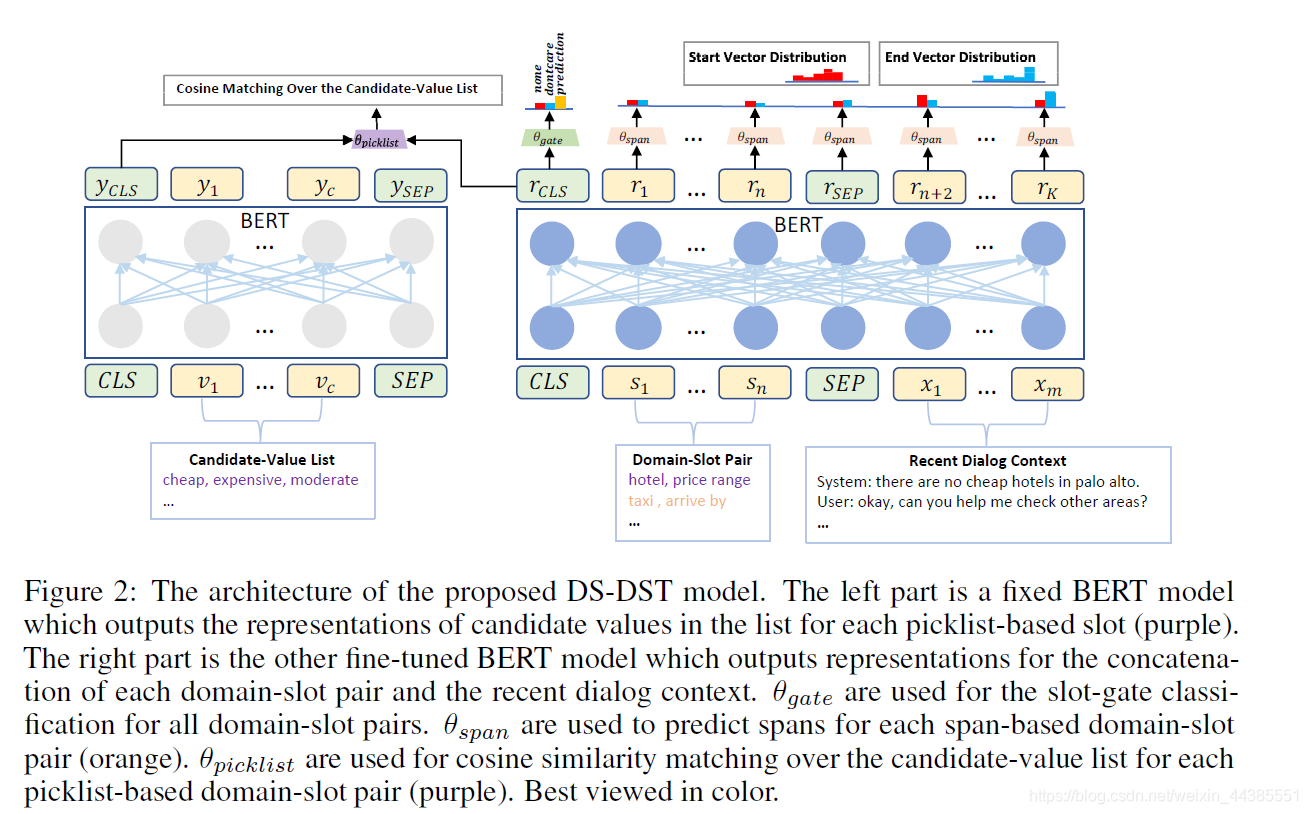
一些符合的规定:
system utterance:
U
t
s
y
s
U^{sys}_t
Utsys
user utterance:
U
t
u
s
r
U^{usr}_t
Utusr.
t表示第t轮,
1
≤
t
≤
T
1≤t≤T
1≤t≤T
one turn:
(
U
t
s
y
s
,
U
t
u
s
r
)
(U^{sys}_t,U^{usr}_t)
(Utsys,Utusr)
dialogue context at
t
t
h
t_{th}
tth turn :
X
t
=
{
(
U
1
s
y
s
,
U
1
u
s
r
)
,
.
.
.
,
(
U
t
s
y
s
,
U
t
u
s
r
)
}
X_t=\left\{ (U^{sys}_1,U^{usr}_1),... ,(U^{sys}_t,U^{usr}_t)\right\}
Xt={(U1sys,U1usr),...,(Utsys,Utusr)}
at each turn:
all the domain-slot pairs:
S
=
{
S
1
,
.
.
.
,
S
N
}
S=\left\{S_1,...,S_N\right\}
S={S1,...,SN}
注意本文domain-slot pair就是slot
共N个全部可能的pairs
y
t
j
g
a
t
e
y^{gate}_{tj}
ytjgate是第
t
t
t轮第
j
j
j个domain-slot pair的one-hot gate label。
其中M个span-based slots,N-M个picklist-based slots,两类slot的区别用人工启发法。
对于S中的N-M个picklist-based slots,每个slot有C个可能的候选value,即
V
1
V_1
V1到
V
C
V_C
VC,C相当于picklist的size,
设每个domain-slot pair有n个tokens,
X
t
X_t
Xt有m个tokens,每个value有c个tokens。
Slot-Context Encoder
对于第t轮,对话上下文
X
t
X_t
Xt,第j个domain-slot pair,它们的词表示是:
R
t
j
=
B
E
R
T
(
[
C
L
S
]
⊕
S
j
⊕
[
S
E
P
]
⊕
X
t
)
R_{tj}=BERT([CLS] \oplus S_j \oplus [SEP] \oplus X_t)
Rtj=BERT([CLS]⊕Sj⊕[SEP]⊕Xt)
上式的输出向量可以分解为:
R
t
j
=
[
r
t
j
C
L
S
,
r
t
j
1
,
.
.
.
,
r
t
j
K
]
R_{tj}=[r^{CLS}_{tj},r^{1}_{tj},...,r^{K}_{tj}]
Rtj=[rtjCLS,rtj1,...,rtjK]
即形如K个序列化的token-level的上下文表示
[
r
t
j
1
,
.
.
.
,
r
t
j
K
]
[r^{1}_{tj},...,r^{K}_{tj}]
[rtj1,...,rtjK],外加它们的聚合表示(aggregate representaion)
r
t
j
C
L
S
r^{CLS}_{tj}
rtjCLS。
Slot-Gate classification
由于多领域对话中存在非常多的domain-slot pairs,试图正确预测一个domain-slot pair是否在对话中的每一轮出现是比较困难(nontrivial)的。所以我们在我们的神经网络中加入一个Slot-Gate classification模块。
本文中,分类器在{none, dontcare, prediction}上做预测,
none:domain-slot pair未被提到;
dontcare:domain-slot pair不重要;
prediciton:domain-slot pair需要经过模型处理,以得到一个真实的value。
我们利用3.1节中得到的聚合表示
r
t
j
C
L
S
r^{CLS}_{tj}
rtjCLS来实行slot gate分类。
P
t
j
g
a
t
e
=
s
o
f
t
m
a
x
(
W
g
a
t
e
⋅
(
r
t
j
C
L
S
)
+
b
g
a
t
e
)
P^{gate}_{tj}=softmax(W_{gate}·(r^{CLS}_{tj})+ b_{gate})
Ptjgate=softmax(Wgate⋅(rtjCLS)+bgate)
其中W和b是可训练参数。
分类器的损失函数定义如下: L g a t e = ∑ t = 1 T ∑ j = 1 N − l o g ( P t j g a t e ⋅ ( y t j g a t e ) T ) L_{gate}=\sum^T_{t=1}\sum^N_{j=1} -log(P^{gate}_{tj}·(y^{gate}_{tj})^T) Lgate=t=1∑Tj=1∑N−log(Ptjgate⋅(ytjgate)T) y t j g a t e y^{gate}_{tj} ytjgate是domain-slot pair的one-hot gate label。
Span-Based Slot-Value Prediction
这一节关注span-based slots的预测。
对于每个slot,它的value可以用对话上下文中的起始和终止位置映射成一个span。
e.g., slot l e a v e _ a t leave\_ at leave_at of the t a x i taxi taxi domain has spans 4 : 30 p m 4 : 30pm 4:30pm in
the context.
将3.1节中得到的对话上下文的token-level表示
[
r
t
j
1
,
.
.
.
,
r
t
j
K
]
[r^{1}_{tj},...,r^{K}_{tj}]
[rtj1,...,rtjK]用作输入,应用一个two-way linear mapping来获取start vector
α
t
j
s
t
a
r
t
\alpha^{start}_{tj}
αtjstart和end vector
α
t
j
e
n
d
\alpha^{end}_{tj}
αtjend。
[
α
t
j
s
t
a
r
t
,
α
t
j
e
n
d
]
=
W
s
p
a
n
⋅
(
[
r
t
j
1
,
.
.
.
,
r
t
j
K
]
)
T
+
b
s
p
a
n
[\alpha^{start}_{tj}, \alpha^{end}_{tj}] = W_{span} · ([r^{1}_{tj},...,r^{K}_{tj}])^{T} + b_{span}
[αtjstart,αtjend]=Wspan⋅([rtj1,...,rtjK])T+bspan
其中W和b还是可训练参数。
损失函数的定义省略。
Picklist-Based Slot-Value Prediction
这一节关注picklist-based slots的预测。
对于每个slot,分类器从几个candidate values中找到最可能的那个
e.g., slot p r i c e _ r a n g e {price\_range} price_range in the h o t e l hotel hotel domain has possible values
{ c h e a p , e x p e n s i v e , m o d e r a t e } \left\{cheap, expensive,moderate\right\} {cheap,expensive,moderate}
首先,对于第
t
t
t轮的第
j
j
j个domain-slot,使用一个开发的预训练BERT获取所有values的聚合表示:
Y
j
=
B
E
R
T
(
[
C
L
S
]
⊕
V
j
⊕
[
S
E
P
]
)
Y_{j}=BERT([CLS]\oplus V_j\oplus [SEP])
Yj=BERT([CLS]⊕Vj⊕[SEP])
同理,输出可以表示为
Y
j
=
{
y
1
C
L
S
,
.
.
.
,
y
L
C
L
S
}
Y_{j}=\left\{y^{CLS}_1,...,y^{CLS}_L\right\}
Yj={y1CLS,...,yLCLS}。L是candidate values的数量。
y
l
C
L
S
y^{CLS}_l
ylCLS就是第
l
l
l个candidate value,
1
≤
l
≤
L
1≤l≤L
1≤l≤L。
损失函数是一个hinge loss,最大化picklist中target value与most similar value(最大的 y l C L S y^{CLS}_l ylCLS)的差异。方式是比较两者与 r t j C L S r^{CLS}_{tj} rtjCLS的余弦相似度
Training Objective
三个模块联合训练,BERT参数共享。
L
t
o
t
a
l
=
L
s
g
+
L
s
p
a
n
+
L
p
i
c
k
l
i
s
t
L_{total} = L_{sg} + L_{span} + L_{picklist}
Ltotal=Lsg+Lspan+Lpicklist
实验设置
数据集:MultiWOZ 2.1
数据预处理:砍掉hospital和police这两个领域,共使用5个领域,30场对话,使用和TRAME一样的预处理方式。不使用原始的不完整的本体,而是通过traverse the dataset来否建candidate value list。
模型:以同样的数据预处理方式,采用了SpanPtr, FJST, HyST, DSTreader, TRADE共5个以前已有的模型,外加本文的三种模型,共8种模型。
- DST-Span: 类似SpanPtr,把所有domain-slot pairs看做span-based slots。
- DST-Picklist: 把所有domain-slot pairs看做picklist-based slots。
- DS-DST:都有。
Experimental Results
整体结论
以上模型在MultiWOZ 2.1下的联合准确率对比如下:

DS-DST模型确实取得了优秀的结果,但是,它的性能反而不如完全把domain-slot pairs都看做picklist-based slots的DST-Picklist好,后者依然应该被看做是predefined ontology-based方法。
总结而言,DST-Picklist性能比DS-DST好,DS-DST又比DST-Span好,说明只要预定义的slot ontology足够好,fixed-vocabulary-based DST就还有利用价值,最起码目前水平的open-vocabulary-based DST模型们还没好到能把predefined ontology-based方法一脚踢开(毕竟用户的话语string千奇百怪,不是总能靠span找到value的)。但是如果考虑复杂性(工业界定义ontology困难)和可扩展性(难以集成新的value和domian),open-vocabulary-based DST大有可为。
其他分析
(1)SpanPtr是open-vocabulary-based DST的经典模型,本文论文团队对其进行重新设计,即一部分slot被看做picklist-based slots用本文的方式来预测,称为SpanPtr-New。如下图所示,再次说明双策略DST比仅依赖生成方法的DST要好。
(2)我们的核心创新点是DST的双策略,而两种策略下的预测模型还是站在了visual question answering(2016)和text reading comprehensions(2018)的肩膀上。
(3)DST中处理domain-slot pairs的三种方式,以
h
o
t
e
l
hotel
hotel领域的
p
r
i
c
e
_
r
a
n
g
e
price\_range
price_range槽位为例:
- concatenation:将领域名称与槽位名称直接拼接
h o t e l p r i c e r a n g e hotel\ price\ range hotel price range - Slot Description:显式描述出槽位部分
p r i c e r a n g e o f t h e h o t e l price\ range\ of\ the\ hotel price range of the hotel - Question Asking:用问答的方式表示
w h a t i s t h e p r i c e r a n g e o f t h e h o t e l ? what\ is\ the\ price\ range\ of\ the\ hotel\ ? what is the price range of the hotel ?
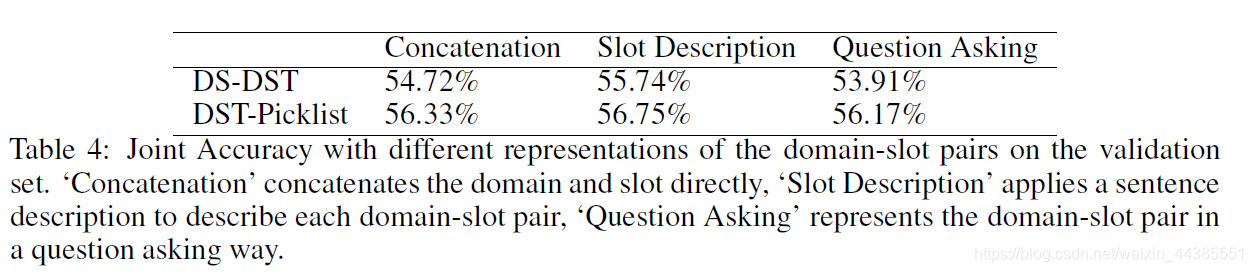
更多细节参考下表:

三种表示方法在验证集上的对比,我们猜测Slot Description是最好的。
(4)我们还讨论对两类slots的区分方式。比如Threshold-10表示candidate-value lists的长度少于10则划入picklist-based slots,否则划入span-based slots。结论是,基于人工启发法进行区分比基于简单门限的区分性能更好。所谓人工启发法,即把time和number这俩种槽位划入span-based slots。


















 9221
9221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









