






 医学分割十项全能挑战要求参与者创建分割算法,用于概括10个数据集对应的不同实体人体数据。算法需动态适应特定数据集细节,且只能以全自动方式进行。
医学分割十项全能挑战要求参与者创建分割算法,用于概括10个数据集对应的不同实体人体数据。算法需动态适应特定数据集细节,且只能以全自动方式进行。
Fabian Isensee, Jens Petersen, Andre Klein, David Zimmerer, Paul F. Jaeger,
Simon Kohl, Jakob Wasserthal, Gregor K¨ohler, Tobias Norajitra, Sebastian
Wirkert, and Klaus H. Maier-Hein
Division of Medical Image Computing, German Cancer Research Center (DKFZ),
Heidelberg, Germany
基于U-net的医学图像分割的自适应框架
Abstract:
摘要
The present paper introduces the nnU-Net (”no -new-Net”), which refers to a robust and self-adapting framework on the basis of 2D and 3D vanilla U-Nets
一种基于二维和三维普通u-net的鲁棒自适应框架
Introduction:
介绍
The Medical Segmentation Decathlon is intended to specifically address this issue: participants in this challenge are asked to create a segmentation algorithm that generalizes across 10 datasets corresponding to different entities of the human body. These algorithms may dynamically adapt to the specifics of a particular dataset, but are only allowed to do so in a fully automatic manner.
医学分割十项全能旨在专门解决这个问题:这个挑战的参与者被要求创建一个分割算法,概括10个数据集对应于不同的实体的人体数据。这些算法可以动态地适应特定数据集的细节,但只允许以一种全自动的方式这样做。
In this paper, we present the nnU-Net (”no-new-Net”) framework. It resides on a set of three comparatively simple U-Net models that contain only minor modifications to the original U-Net [
6
]. We omit recently proposed extensions such as for example the use of residual connections [
7
,
8
], dense connections [
5
] or attention mechanisms [
4
]. The nnU-Net automatically adapts its architectures to the given image geometry. More importantly though, the nnU-Net framework
thoroughly defines all the other steps around them. These are steps where much of the nets’ performance can be gained or respectively lost: preprocessing (e.g. resampling and normalization), training (e.g. loss, optimizer setting and data augmentation), inference (e.g. patch-based strategy and ensembling across test time augmentations and models) and a potential post-processing (e.g. enforcing single connected components if applicable).
在本文中,我们提出了nnU-Net(“no -new-Net”)框架。它驻留在一组三个相对简单的U-Net模型上,它们只包含对原始的U-Net [6]的微小修改。我们省略了最近提出的扩展,例如使用残差连接[7,8]、密集连接[5]或注意机制[4]。nnU-Net会自动调整其架构以适应给定的图像几何结构。更重要的是,nnU-Net框架彻底地定义了围绕它们的所有其他步骤。在这些步骤中,网络的性能可以获得或分别丢失:预处理(例如重采样和标准化)、训练(例如损失、优化器设置和数据增强)、推理(例如基于补丁的策略和跨测试时间增强和模型的集成)和潜在的后处理(例如,如果适用,强制执行单个连接组件)。
Method
s
方式
Network architectures
网络结构
Just like the original U-Net, we use two plain convolutional layers between poolings in the encoder and transposed convolution operations in the decoder. We deviate from the original architecture in that we replace ReLU activation functions with leaky ReLUs (neg. slope 1
e
−
2
) and use instance normalization [
11
] instead of the more popular batch normalization
就像最初的U-Net一样,我们在编码器中的池化层和解码器中的转置卷积操作之间使用了两个普通的卷积层。我们偏离了原来的架构,因为我们用泄漏的ReLU替换了ReLU激活函数。斜率1e−2),并使用实例规范化[11],而不是更流行的批处理规范化
U-Net Cascade To address this practical shortcoming of a 3D U-Net on datasets with large image sizes, we additionally propose a cascaded model. Therefore, a 3D U-Net is first trained on downsampled images (stage 1). The segmentation results of this U-Net are then upsampled to the original voxel spacing and passed as additional (one hot encoded) input channels to a second 3D U-Net, which is trained on patches at full resolution (stage 2). See Figure
1
.
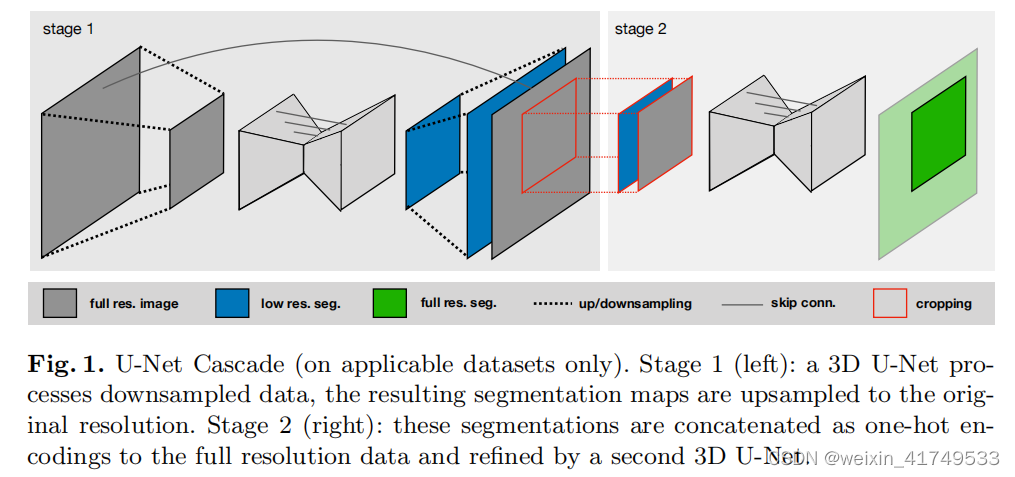
U-Net级联(仅适用在适用的数据集上)。阶段1(左):一个3D U-Net处理下采样的数据,所得到的分割图被上采样到原始分辨率。阶段2(右):这些分割被作为一个热编码连接到全分辨率数据,并通过第二个3D U-Net进行细化
Dynamic adaptation of network topologies
网络拓扑结构的动态自适应
Due to the large differences
in image size (median shape 482
×
512 × 512 for Liver vs. 36 × 50 × 35 for Hippocampus) the input patch size and number of pooling operations per axis (and thus implicitly the number of convolutional layers) must be automatically adapted for each dataset to allow for adequate aggregation of spatial information. Apart from adapting to the image geometries, there are technical constraints like the available memory to account for. Our guiding principle in this respect is to dynamically trade off the batch-size versus the network capacity
由于图像大小的巨大差异(平均形状482×512×512肝脏与36×50×35海马)输入补丁大小和池操作每个轴(因此隐式卷积层的数量)必须自动适应每个数据集允许足够的聚合空间信息。除了适应图像几何形状,还有技术上的限制,比如可用内存。在这方面,我们的指导原则是动态地权衡批量大小和网络容量
We train our networks with a combination of dice and cross-entropy loss:
L
total
=
L
dice
+
L
CE
我们结合DICE损失和交叉熵损失来训练我们的网络:
Dice-loss
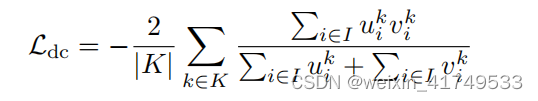
where
u
is the softmax output of the network and
v is a one hot encoding of the ground truth segmentation map. Both
u
and
v
have shape
I
×
K with i
∈
I
being the number of pixels in the training patch/batch and
k
∈
K being the classes
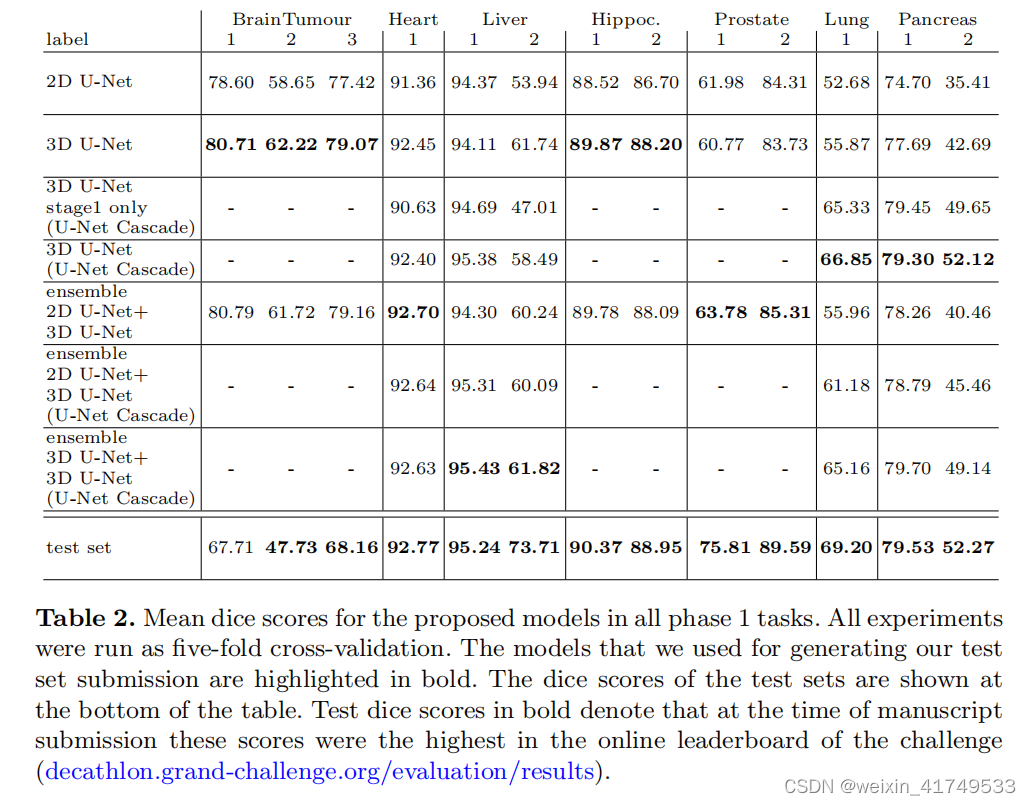
Result:

















 71
71

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









