







【小样本图像分割-4】nnU-Net: Self-adapting Framework for U-Net-Based Medical Image Segmentation

这是一个2018年的文章,其中很多医学图像分割领域的专家都知道的论文,虽然不是完全的小样本学习,我这里也还是放在这里做一个简单的笔记。牛逼的是,这个文章后面是发表在nature上的。
文章的地址:[1809.10486] nnU-Net: Self-adapting Framework for U-Net-Based Medical Image Segmentation (arxiv.org)
代码的地址:github.com
摘要
nnU-Net 中的nn分别表示no和new,这个网络不能算作是小样本的医学图像分割方法,但是可以作为一种自适应的医学图像分割方法。该方法能够根据数据集的内容自动的修改模型的超参数,让你的unet模型更加适配你的数据集,从而可以得到一个比较sota的模型。这里作者实践出真知,在比赛中提供了10个数据集上都拿到了不错的成绩,并且这个模型中使用的一些tricks在后续的比赛中都可以借鉴。
U-Net于2015年推出。凭借其简单而成功的架构,它迅速发展成为医学图像分割中常用的基准。然而,U-Net对新问题的适应包括关于精确架构、预处理、训练和推理的几个自由度。这些选择不是相互独立的,并且会对整体性能产生重大影响。本文介绍了nnU-Net(“nonew-Net”),它是一种基于2D和3D vanilla U-Nets的鲁棒自适应框架。我们认为去掉许多网络设计中多余的花里胡哨,而把重点放在其他方面,使方法的性能和通用性。我们在医学分割十项挑战的背景下评估了nnU-Net,该挑战测量了包含不同实体、图像模式、图像几何形状和数据集大小的10个学科的分割性能,不允许在数据集之间进行手动调整。在稿件提交时,nnU-Net在挑战的在线排行榜上获得了所有类别和七个阶段1任务(脑瘤1类除外)的最高平均骰子分数。
当前的主要问题是很多医学图像分割的方法都是在各自的任务上设计了特殊的结构,才让各自的任务达到了最佳,但是这些方法切换一个任务效果就会下降很多。The Medical Segmentation Decathlon计划通过这种方式解决这个问题:希望参赛者设计一种算法,在10种数据集上进行测试,都能够达到很好的效果,而算法不能够针对某种数据集进行人为的调整,只能自动的去适应。
所以作者这里的方法没有侧重于网络结构,而是更多地侧重于tricks,包括数据增强、预处理和训练策略以及后处理方面。
作者提出的方法
模型方面
首先是模型方面,因为作者后面使用到了模型集成的技术,模型集成也就是使用了多个模型进行投票,按照作者原文的方法,作者通过排列组合的方式两两去组合模型,得到结果之后选择投票分数最高的进行预测,其中选择模型的依据是根据五折交叉验证中选择平均分数来决定。作者这里使用了3个模型,分别是2d-unet、3d-unet和作者提出的cascade-unet。
2d-unet : 直观地说,在3D医学图像分割的背景下使用2D U-Net似乎是次优的,因为沿着z轴的有价值的信息不能被聚合和考虑。然而,有证据表明,如果数据集是各向异性的,传统的3D分割方法的性能会下降
3d-unet: 3D U-Net似乎是选择3D图像数据的合适方法。在一个理想的世界里,我们会在病人的整个图像上训练这样一个架构。然而,在现实中,我们受到可用GPU内存数量的限制,这使得我们只能在图像补丁上训练这种架构。虽然对于由较小图像组成的数据集(按每个患者的体素数计算),如脑肿瘤、海马体和前列腺数据集来说,这不是问题,但对于具有大图像的数据集(如肝脏)来说,基于补丁的训练可能会阻碍训练。这是由于建筑的视野有限,因此无法收集足够的上下文信息,例如,正确区分肝脏的部分和其他器官的部分。
cascade-unet: 为了解决3D U-Net在大图像数据集上的这个实际缺点,我们另外提出了一个级联模型。因此,首先在下采样图像上训练3D U-Net(阶段1)。然后将该U-Net的分割结果上采样到原始体素间隔,并作为额外的(一个热编码)输入通道传递给第二个3D U-Net,后者在全分辨率的补丁上进行训练(阶段2)。
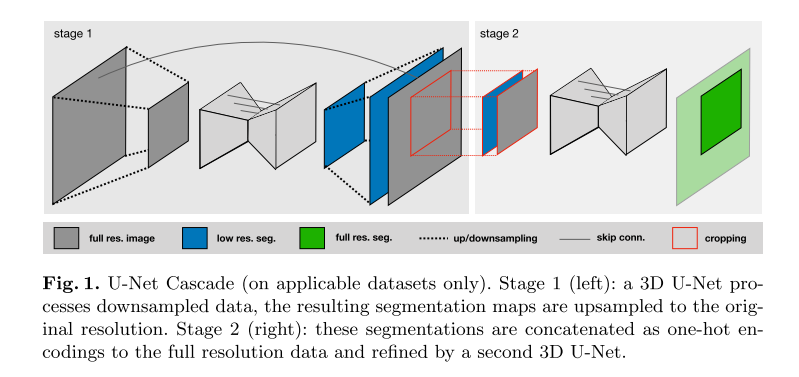
网络自适应的策略是:我们从网络配置开始,我们知道它与我们的硬件设置一起工作。对于2D U-Net,该配置是输入补丁大小为256×256,批处理大小为42,最高层中有30个特征图(每次下采样特征图的数量增加一倍)。我们自动将这些参数调整到每个数据集的中位数平面大小(其中我们使用平面内间距最小的平面,对应于最高分辨率),以便网络有效地在整个切片上进行训练。我们将网络配置为沿着每个轴进行池,直到该轴的特征映射大小小于8(但不超过最多6个池化操作)。就像2D U-Net一样,我们的3D U-Net使用最高分辨率层的30个特征图。这里我们从输入补丁大小为128 × 128 × 128的基本配置开始,批处理大小为2。由于内存限制,我们没有将输入补丁体积增加到1283体素以上,而是将输入补丁大小的纵横比与数据集体素中位数大小的纵横比相匹配。如果数据集的中位数形状小于1283,那么我们使用中位数形状作为输入patch大小并增加批大小(以便处理的体素总数与128 × 128 × 128和批大小为2相同)。就像2D U-Net一样,我们沿着每个轴进行池(最多5次),直到特征地图具有大小8. 对于任何网络,我们将每个优化器步骤处理的体素总数(定义为输入补丁体积乘以批处理大小)限制为最大值数据集的5%。对于过多的情况,我们减少批大小(下界为2)。
通过这样的设计得到的网络结构如下:
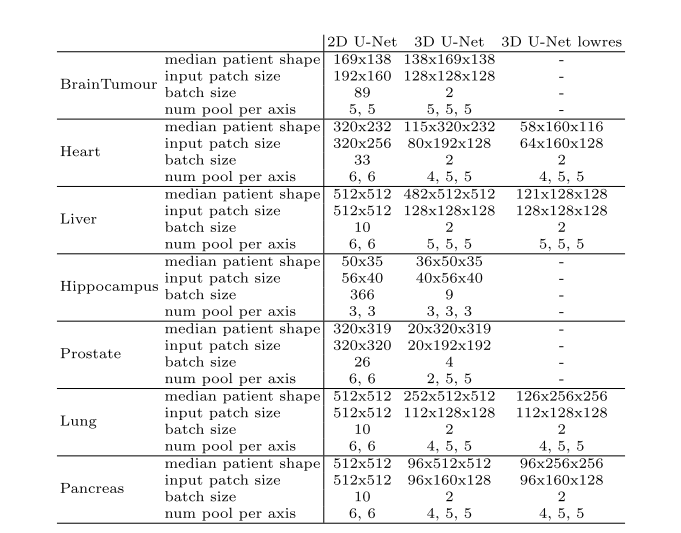
另外作者还采用了切片、重采样、归一化等一系列的技术保证数据的分布尽可能科学。切片之后可能会导致网络中有大量的背景类存在,为此,为了提高网络训练的稳定性,我们强制要求批处理中超过三分之一的样本至少包含一个随机选择的前景类。推理的时候使用五折交叉验证,验证之后的结果通过后处理来进行操作,对训练数据进行所有地面真值分割标签的连通成分分析。如果一个类在所有情况下都位于单个连接的组件中,则此行为将被解释为数据集的一般属性。因此,在相应数据集的预测图像上,除了最大的连接组件外,该类的所有组件都被自动删除。以及最终的结果由多个模型投票得出。
本方法的一些效果
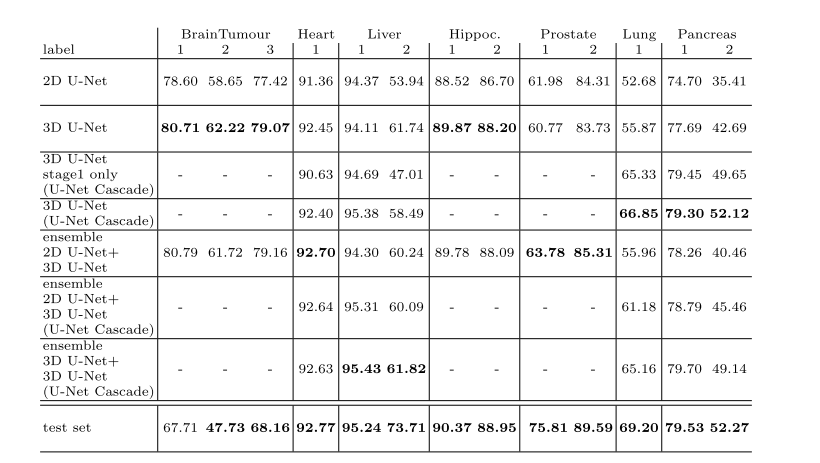
作者给出了在榜单上的效果,可以说是遥遥领先。
结论
总的来说,是一份非常工程化的论文,也可以说是非常实际化的一篇论文,除了论文之外,很多比赛、项目都是要效果的。同样的,在这样的基础上,可以将现在的一系列的sam、transoformer的方法移动到这个二阶段的分割网络上面,从小样本或者单纯网络结构改进的角度出来,应该可以得到不错的效果。
















 1140
1140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











