







GitHub链接:https://github.com/ultralytics/yolov3
参考链接:https://blog.csdn.net/qq_44787464/article/details/99736670
1.requirements
pip install -r requirements.txt
Python>=3.7
PyTorch>=1.5
Cython
numpy==1.17
opencv-python
torch>=1.5
matplotlib
pillow
tensorboard
PyYAML>=5.3
torchvision
scipy
tqdm
git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI
2.数据准备(省略标记)
准备自己的数据集(voc)
├── Annotations 进行 detection 任务时的标签文件,xml 形式,文件名与图片名一一对应
├── ImageSets 包含三个子文件夹 Layout(不使用)、Main、Segmentation(不使用),其中 Main 存放的是分类和检测的数据集分割文件
├── JPEGImages 存放 .jpg 格式的图片文件
├── SegmentationClass 存放按照 class 分割的图片(不使用)
└── SegmentationObject 存放按照 object 分割的图片(不使用)
├── Main
│ ├── train.txt 写着用于训练的图片名称
│ ├── val.txt 写着用于验证的图片名称
│ ├── trainval.txt train与val的合集
│ ├── test.txt 写着用于测试的图片名称
数据Annotations和JPEGImages放入data目录下,并新建文件ImageSets,labels,复制JPEGImages,重命名images
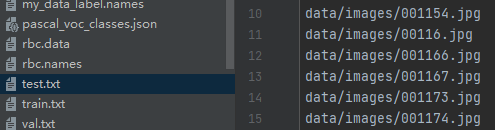
(1)生成train.txt,val.txt,test.txt(无路径)即:

getText.py程序
import os
import random
trainval_percent = 0.1#数据少就1:9
train_percent = 0.9
xmlfilepath = '/data/Annotations'
txtsavepath = '/data/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('/data/ImageSets/trainval.txt', 'w')
ftest = open('/data/ImageSets/test.txt', 'w')
ftrain = open('/data/ImageSets/train.txt', 'w')
fval = open('/data/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
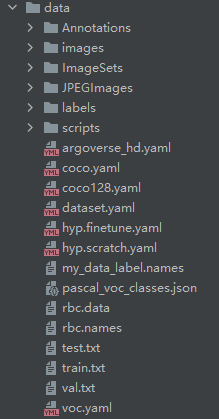
(2)生成标签信息以及带路径的train.txt,val.txt等文件

voc_label.py
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test', 'val']
classes = ["1","2","3","4","5","6"] # 修改类别
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('data/Annotations/%s.xml' % (image_id))
out_file = open('data/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











