







1 新闻的特征向量
我们在新闻页面中浏览新闻的时候,通常会有很多模块,在这些模块里面的新闻都是具有一定相关性的。如果单纯依靠人工对大量的新闻进行分类显然是不可能的,因此需要让计算机能够“算”新闻,从而将新闻进行分类。
我们知道,同一类新闻用的词是比较相似的,不同类的新闻用词会存在较大的不同。并且一篇文章中,不同的词重要性程度也不相同。
因此我们可以利用之前学习的TF-IDF算法,计算它们的TF-IDF值。
现在假设词汇表中有64000个词,如下图所示。

然后我们选择一篇新闻,计算这64000个词的TF-IDF值,如下图所示。
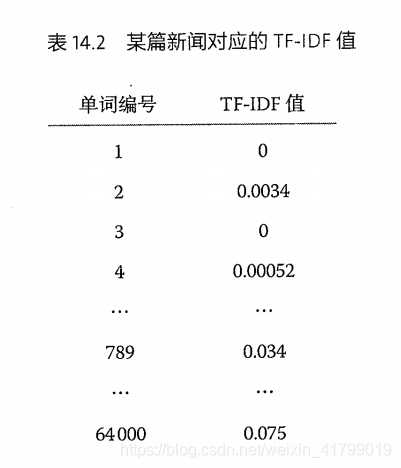
因此我们可以将这些TF-IDF值看成是一个具有64000维的向量。然后我们就可以使用一个特征向量去代表一篇新闻。
2 向量距离的度量
对于不同的新闻,如果这两个新闻相似度比较高,那么出现相同词汇的频率就越高。因此对于相似的新闻,那么它们的特征向量会在某几个维度的值都比较大,而在其他维度的值都比较小。反之如果两个新闻不相似,那么在值较大的维度就不会有什么交集。
因此这里就引入余弦定理。通过余弦定理可以来衡量两个向量的相近程度。
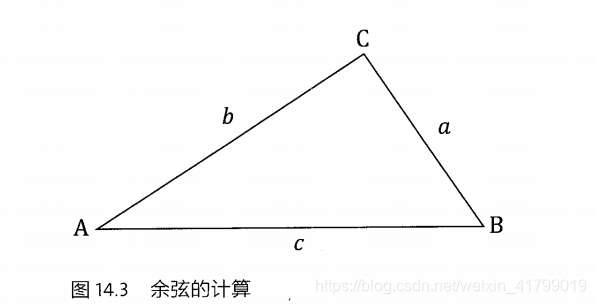
通过基本的数学知识,我们应该知道余弦的公式如下:

假设新闻X和新闻Y对应的向量分别是:
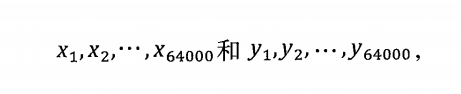
那么它们夹角的余弦等于
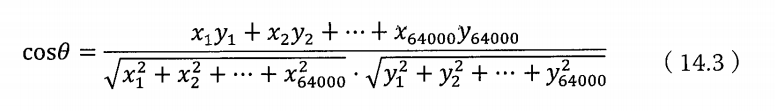
由于向量中的每个变量都是正数,所以余弦值必定在0和1之间,也就是夹角都是在0到90之间。当计算结果等于1时,那么说明两个向量夹角为0,即两篇新闻完全相同。当计算结果等于0时,那么说明两个新闻完全无关。
现在已经有了计算两个新闻相似性的公式了,下面就具体讨论新闻分类的算法。第一种情况是已经有了某一类新闻的特征向量,这样就直接计算就可以进行分类了。第二种情况是如果没有已经分好类的特征向量怎么办。
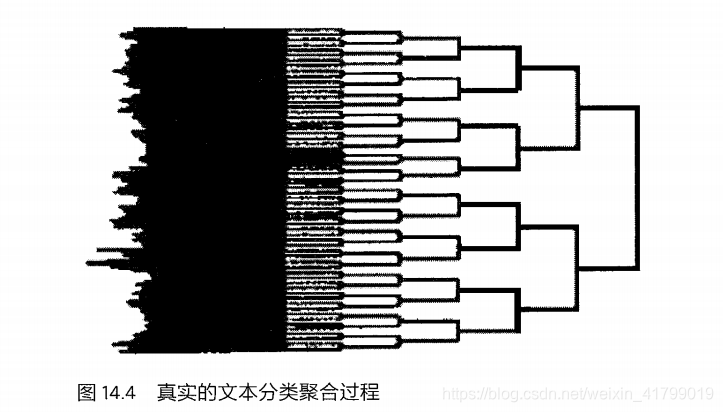
对于第二种情况,国外大学的教授提出了一个自底向上不断合并的办法,具体思想如下:
- 计算新闻两两之间的余弦相似性,把相似性大于一个阈值的新闻合并成一个小类,这样N篇新闻就被合并成N1个小类,且N1<N。
- 把每个小类中所有的新闻作为一个整体,计算小类的特征向量,再计算小类间两两的余弦相似性,然后合并成大一点的小类,假如有N2个,当然N2<N1。
这样不断迭代下去,类别越来越少。到一定的类别数就可以停止了,不然同一类中的相似性就会不断降低。最后得到如下结果。
3 延伸阅读:计算向量余弦的技巧
对于利用上述方法进行计算,会发现时间复杂度还是比较高的,因此这里考虑了几个方法进行优化。
- 每个向量的模计算后可以保留下来,避免重复计算
- 计算向量内积的时候,只考虑向量的非零元素,这样可以大大节省时间
- 删除新闻中的虚词
此外,我们在实际应用中,还需要考虑到不同位置出现的词重要性是不同的。例如标题会比正文重要,开头会比结尾重要等等,可以通过加权实现重要性程度。

















 1063
1063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









