







一、摘要
- 原始的RNN和LSTM模型是使用前向传播遍历整个序列来计算损失,然后再通过反向传播遍历整个序列来计算梯度,具体过程如下图所示:

但是这种方式对于时间和内存的消耗都是巨大的。
因此,有学者提出了Truncated Backpropagation的概念,思想是将序列分成很多个小块,首先在第一个序列块中前向传播计算损失,然后在第一个序列块中进行反向传播更新梯度。之后将第一个序列块的隐藏层状态传递给第二个序列块,执行前向传播计算损失,再进行反向传播更新梯度(仅在第二个序列块中进行)。依次类推,具体如下图所示:

通过这种方式可以极大地节省开销,但是这种方式可能会失去长距离的依赖。
- 本文提出的模型是基于transformer进行改进的,主要工作是增加了auxiliary losses。
二、介绍
- 字符级别的模型通常会面对三个挑战:
- 模型需要从头开始学习大量词汇。
- 由于是字符级别,这样会导致上下文依赖跨度很大。
- 字符级别会导致时间步变长,需要更多的计算能力。
- 1990年有学者提出将Truncated Backpropagation应用在不同的batch中,也就是当一个batch计算完成之后,将这个batch的隐藏状态传递给下一个batch,这种方式可以建立更长距离的上下文依赖。但是这种方式增加了模型的复杂度,并且最近的工作发现这种方法无法学习到“强壮的”长距离依赖。
3. 本文使用的是transformer self-attention layers和casual(backward-looking) attention mask去处理固定长度的序列,并且在训练时序列顺序是打乱的(random positions),因此没有将信息在batch之间传递。 - 本文添加了auxiliary losses,加速了模型的收敛,使得能够训练更深的网络包括如下:
- at intermediate sequence positions
- from intermediate hidden representations
- at target positions multiple steps in the future
三、字符级别Transformer模型
-
语言模型计算sequences出现的概率,可以转换为如下计算联合概率,L代表序列的长度:
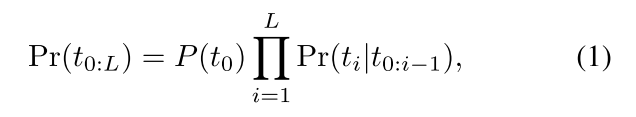
-
为了确保模型在预测的时候,只能看见之前的字符,模型采用了casual attention mask(limit information flow from left to right)。

-
为了加速模型的收敛,模型在训练时添加上了auxiliary loss。而在模型进行预测和推断的时候,只会使用到最后一层最后一个位置的误差。
-
Multiple Positions Losses
-
假设我们现在已经得到了t1、t2、t3的预测字符了,我们接下来需要通过t1、t2、t3来预测下一个字符t4。正常来说,我们只需要计算下一个位置(也就是t4)的预测损失。
-
但是本模型的Multiple Positions loss则是对于最后一层的每一个节点都要计算下一步应该预测的字符,计算每一个位置的损失。
-
并且Multiple Positions loss在整个训练过程都一直存在,不发生衰减。

-
-
Intermediate Layer Losses
-
本文的模型在每一个中间的transformer layer中都加入了预测损失,具体如下图所示。总共两层transformer layer,每一层都会对当前时间步的字符进行预测,计算损失。
-
随着训练的进行,较低层次的损失权重会变得越来越小。
-
如果有n个layers,第L个中间层的损失会在L/2*n次训练之后停止计算,也就是当训练次数过半,所有中间层的损失都不会再计算。

-
-
Multiple Targets Losses
-
在每个位置,都会去尝试预测两个(或更多)将来的字符。
-
对于产生的loss,会乘以权重0.5加到全局损失中。

-
-
Positional Embeddings
- 原始的transformer模型是在第一个transformer layer中加入正弦时间信号来加入相对位置和绝对位置信息。
- 本文的模型担心在深层次的网络中,位置信息丢失,因此在每一个transformer layer都加入positional embedding,并且参数是可学习的。
四、实验设置
- 数据集
- 采用English Wikipedia articles的text 8
- 所有字符转换成小写,数字也转换成英文,如“20” 变成“two zero”,其他字符全部转换成空格。
- 经过上一步的预处理,整个数据集只有27个unique characters
- 训练
- 使用的是momentum optimizer,其中momentum=0.99.
- 评估
- 模型每预测一个字符,都需要重头开始处理上下文,因此十分消耗计算资源和内存。(这个是本模型最大的缺陷)
五、实验结果
实验的模型有12层的和64层,都取得了比较好的效果。

bpb(bitsper-byte)是通过ppl(word perplexity)计算得来的,两者都是越小越好。
六、消融实验
根据上面提到的模型优化方式进行消融实验,对比每种优化对于模型做的贡献。

可以看到,Multiple Positions和Intermediate Layer Losses对于模型性能提升做出的贡献最大。
七、总结
本文的创新点主要就在于提出了三种auxiliary losses,以加速模型的收敛。但是最大的缺陷就是模型训练很慢。















 601
601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









