







https://zhuanlan.zhihu.com/p/83364904
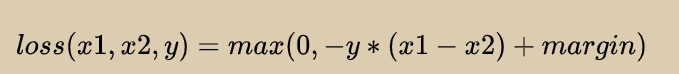
MarginRankingLoss
大家可能对这个损失函数比较陌生。在机器学习领域,了解一个概念最直观的最快速的方式便是从它的名字开始。
MarginRankingLoss也是如此,拆分一下,Margin,Ranking,Loss。
Margin:前端同学对Margin是再熟悉不过了,它表示两个元素之间的间隔。在机器学习中其实Margin也有类似的意思,它可以理解为一个可变的加在loss上的一个偏移量。也就是表明这个方法可以手动调节偏移。当然Margin不是重点。
Ranking:它是该损失函数的重点和核心,也就是排序!如果排序的内容仅仅是两个元素而已,那么对于某一个元素,只有两个结果,那就是在第二个元素之前或者在第二个元素之前。其实这就是该损失函数的核心了。
我们看一下它的loss funcion表达式。
margin我们可以先不管它,其实模型的含义不言而喻。
y只能有两个取值,也就是1或者-1。 1. 当y=1的时候,表示我们预期x1的排名要比x2高,也就是x1-x2>0 2. 当y=-1的时候,表示我们预期x1的排名要比x2高,也就是x1-x2<0
什么时候用?
- GAN
- 排名任务
- 开源实现和实例非常少
HingeEmbeddingLoss
再从名字入手去分析一下。
Hinge:不用多说了,就是大家熟悉的Hinge Loss,跑SVM的同学肯定对它非常熟悉了。
Embedding:同样不需要多说,做深度学习的大家肯定很熟悉了,但问题是在,为什么叫做Embedding呢?我猜测,因为HingeEmbeddingLoss的主要用途是训练非线形的embedding,在机器学习领域,因为用途和图形来命名的例子不在少数。
它输入x和y(1或者-1),margin默认为1。
1. 当y=-1的时候,loss=max(0,1-x),如果x>1(margin),则loss=0;如果x<1,loss=1-x
2. 当y=1,loss=x
什么时候用?
- 非线形Embedding
- 半监督学习
- 监测两个输入的相似性或者不相似性
CosineEmbeddingLoss
余弦损失函数,余弦函数常常用于评估两个向量的相似性,两个向量的余弦值越高,则相似性越高。
1. 当y=1的时候,就是直接用-cos(x1,x2)的平移函数作为损失函数
2. 当y=-1的时候,在cos(x1,x2)=margin处做了分割,用于衡量两个向量的不相似性
什么时候用?
- 非线形Embedding
- 半监督学习
- 监测两个输入的相似性或者不相似性}>}>














 839
839











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









