







 本文提出了无监督对比跨模态哈希(UCCH)方法,解决二值优化和假负对问题。通过动量优化器实现可学习的哈希运算,以及提出跨模态排序学习损失(CRL)以利用所有负对的区分,提高检索性能。这种方法在无标签数据上能更好地进行跨模态哈希学习,减少了对比学习和哈希之间的性能差距。
本文提出了无监督对比跨模态哈希(UCCH)方法,解决二值优化和假负对问题。通过动量优化器实现可学习的哈希运算,以及提出跨模态排序学习损失(CRL)以利用所有负对的区分,提高检索性能。这种方法在无标签数据上能更好地进行跨模态哈希学习,减少了对比学习和哈希之间的性能差距。
Unsupervised Contrastive Cross-Modal Hashing
【IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 45, NO. 3, MARCH 2023】
无监督对比跨模态哈希
Abstract
本文主要研究了如何通过克服两个挑战,使无监督跨模态哈希(CMH)从对比学习(CL)中受益。
确切来说,
1)为了解决哈希二值优化导致的性能下降问题,我们提出了一种新的动量优化器momentum optimizer,该优化器在CL中执行可学习的哈希运算,从而使现有的深度跨模态哈希成为可能。换句话说,我们的方法不像现有的大多数方法那样涉及二值连续松弛,因此具有更好的检索性能。
2)为了减轻假负对(FNP)带来的影响【FNP指的是被错误地视为负对的类内对】,提出了一种 跨模态排序学习损失(Corss-modal Ranking Learning Loss,CRL) ,它利用了所有对而不是仅对困难负对的区分。由于这样的全局策略,CRL赋予了我们的方法更好的性能,因为CRL不会过度使用FNP而忽略真正的负对。
Introduction
跨模态哈希cross-modal hashing
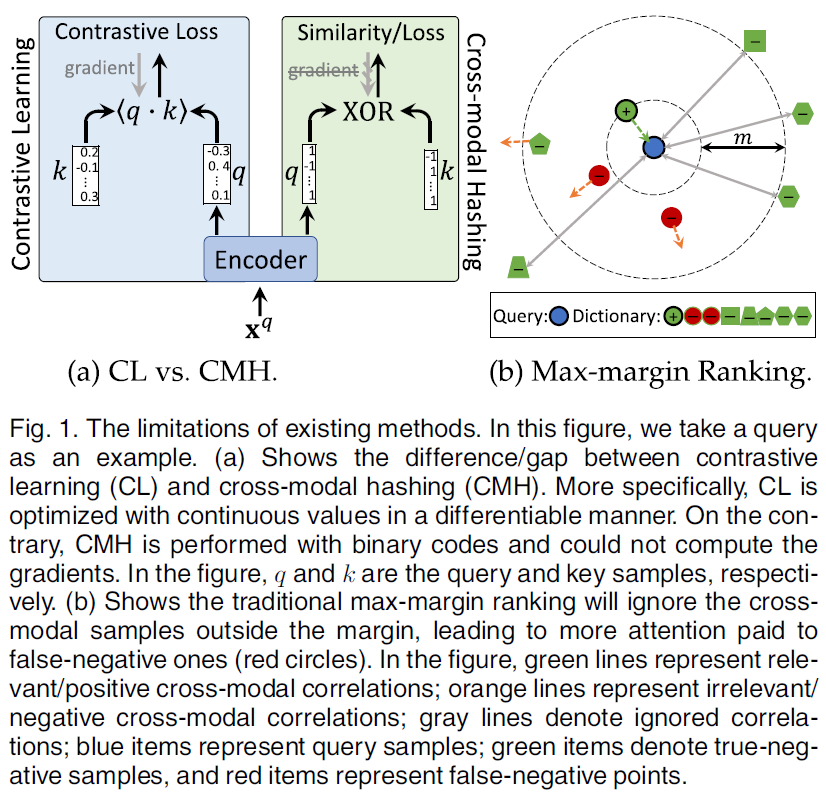
跨模态哈希的基本思想是将高维多模态数据投影到紧凑的二进制位中,得益于逐位相似性测量(XOR),在存储和计算方面,哈希处理将比连续值方法更有效。
大多数现有的跨模态哈希方法可以大致分为有监督和无监督两类。更具体地说,监督方法经常通过使用标记的语义信息从多模态数据中学习哈希码,并取得了良好的性能。然而,他们需要大量的标记数据,并且数据注释是劳动密集型的。与有监督方法不同,无监督跨模态哈希方法可以避免密集的数据注释,在本文中,我们主要关注无监督学习范式。
现有的无监督跨模态哈希方法都是基于浅层或深层模型的。简而言之,浅层方法学习一层线性或非线性变换,将不同的模态投影到公共汉明空间。然而,这些浅层模型不能很好地捕捉高层非线性信息,因此它们将获得次优性能。为了解决这个问题, 深度神经网络(DNN) 被用于学习哈希函数,因为它们在建模非线性方面具有优势。
跨模态哈希的无监督对比学习面临的挑战
跨模态哈希的无监督对比学习面临以下两个挑战:
- 对比学习一直被视为预训练步骤,与下游的跨模态哈希检索存在差距。事实上,对比学习通常采用连续值优化策略,这与跨模态哈希的二进制输出不一致(图1a),因此可能导致性能下降。
- 其次,为了桥接哈希学习和跨模态检索,大多数现有的跨模态哈希方法都采用了max-margin ranking loss最大间隔排序损失,其性能在很大程度上取决于建立的正负对(图1b)。然而,在无监督的环境中,由于标签的不可用性,很难很好地确定正样本和负样本。因此,无监督跨模态哈希通常将同时出现的样本视为正样本,而将其他样本视为负样本。显然这种方法将导致新的噪声,即,许多类内样本被错误地视为负样本。
解决方案——无监督对比跨模态哈希UCCH
为了解决上述两个问题,提出了一种深度无监督跨模态哈希方法——无监督对比跨模态哈希UCCH。
1、 UCCH采用了一种新的基于动量的二值化优化器来赋予哈希运算可学习性,从而使现有的深度跨模态哈希成为可能。
2、为了克服FNP的挑战,提出了一种跨模态排序学习损失CRL,它利用了对所有负对的区分,而不是困难的负对(图4)。提出这种补救措施是为了避免由max-margin loss的性质引起的性能退化,【即具有最大间隔的传统三元组损失倾向于在FNP上过拟合,而忽略真正的负对(TNP),因为FNP通常比TNP更具吸引力,更难进行DNN优化】。
与之前的对比学习模型不同,UCCH是一种特定任务的对比学习方法(task-specified contrastive learning method)。更具体地说,几乎所有现有的对比学习方法都旨在以自监督的方式学习模型,然后对模型进行微调以适应下游任务。受这种两阶段策略的限制,对比学习模型与下游任务之间存在性能差距。为了弥补性能差距,UCCH专门设计用一阶段的方式实现跨模态哈希。
此外与最大间隔损失不同,CRL可以利用来自所有负对比困难对更多的区分,因为前者包含更多的TNP,从而具有更好的性能。
贡献Contributions
- 据我们所知,所提出的UCCH可能是第一个赋予无监督跨模态哈希对比学习的方法
- 提出了一种新的动量优化器,使二进制存储库可学习,从而缩小了对比学习和哈希之间的差距
- 为了克服FNP的挑战,提出了一种跨模态排序学习损失算法CRL,该算法利用了所有对的判别而不是困难负对。由于CRL,我们的方法具有更好的性能和对FNP的鲁棒性
- 大量的实验验证了我们的方法在五个广泛使用的基准多模态数据集上与13种最先进的方法相比的有效性
Related Work
Supervised Cross-Modal Hashing Methods
Unsupervised Cross-Modal Hashing Methods
Unsupervised Contrastive Hashing
The Proposed Method
在现实世界的应用中,一个实例可以用不同的模态来描述,例如图像、文本、音频等。在不失一般性的前提下,本文主要研究双模态(即图像和文本)哈希问题。
如图2所示,我们的UCCH由特征提取和哈希学习两个模块组成。
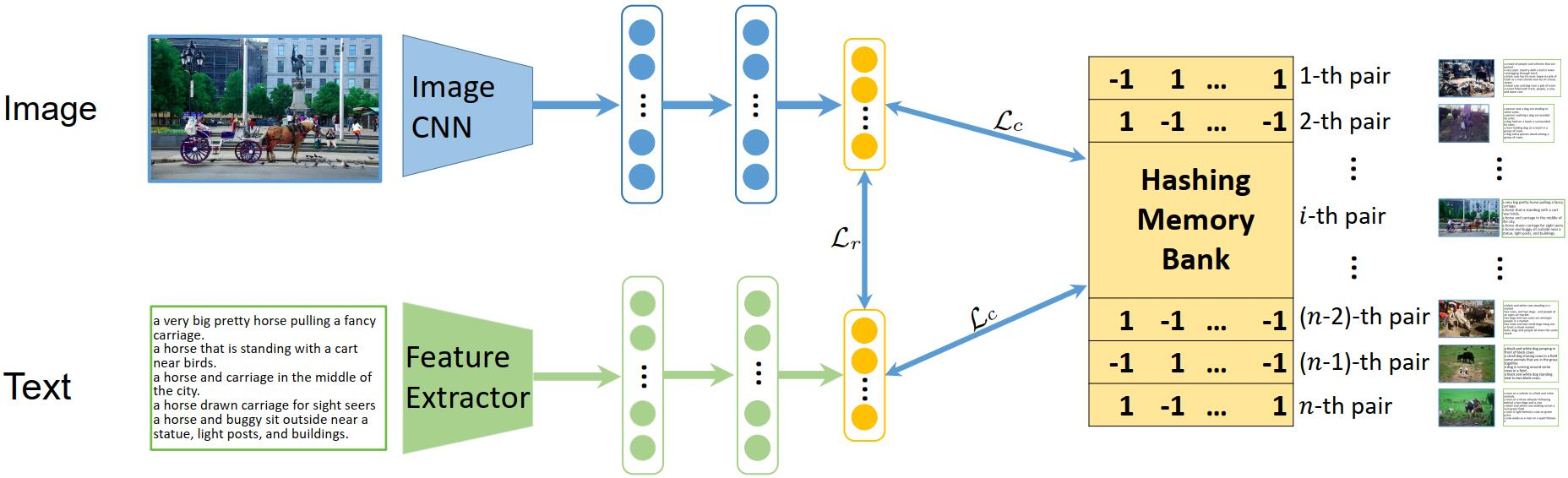
具体来说,特征提取模块旨在使用给定的提取器从原始多媒体输入中提取特征,以表示相应的图像/文本样本。该模块的详细实现将在第4节中解释。
我们的哈希学习模块试图将不同的模态投影到潜在的公共汉明空间中,其中相关的样本被压缩拉近,不相关的样本被分散。
Problem Formulation
- 黑色大写字母(e.g. X X X)和黑色小写字母(e.g. x)分别表示矩阵和向量
-
D
=
{
x
i
,
y
i
}
i
=
1
n
D=\{x_i, y_i\}_{i=1}^n
D={xi,yi}i=1n表示具有
n
n
n个图像-文本对/实例的跨模态数据集
- x i ∈ R d x × 1 x_i \in \mathbb R^{d_x \times 1} xi∈Rdx×1是图像模态的第 i i i个样本
- y i ∈ R d y × 1 y_i \in \mathbb R^{d_y \times 1} yi∈Rdy×1是与 x i x_i xi相关的文本模态
- d x , d y d_x, d_y dx,dy是图像和文本特征的维度
跨模态哈希的目标是将不同的模态投影到一个公共的汉明空间中。在该空间中,图像和文本的统一编码表示为:
- 图像模态: B x = { b i x } i = 1 n B^x = \{b_i^x\}_{i=1}^n Bx={bix}i=1n
- 文本模态:
B
y
=
{
b
i
y
}
i
=
1
n
B^y = \{b_i^y\}_{i=1}^n
By={biy}i=1n
- b i ∗ ∈ { − 1 , + 1 } L , ∗ ∈ { x , y } b_i^* \in \{-1,+1\}^L, * \in \{x,y\} bi∗∈{−1,+1}L,∗∈{x,y}
- L L L是哈希码的长度
汉明距离用于评价图像和文本之间的相似性。更具体地说,如果第 i i i个图像和第 j j j个文本相似,则 b x b^x bx和 b y b^y by之间的汉明距离应该很小。否则,不同样本之间的汉明距离应该很大。
为了方便汉明距离的计算,我们可以使用内积
<
b
x
,
b
y
>
<b^x, b^y>
<bx,by>计算汉明距离:
d
(
b
x
,
b
y
)
=
1
2
(
L
−
<
b
x
,
b
y
>
)
d(b^x,b^y) = \frac{1}{2}(L - <b^x, b^y>)
d(bx,by)=21(L−<bx,by>)。
因此,第
i
i
i张图片与第
j
j
j个文本在汉明空间中的相似度可以用内积
<
b
x
,
b
y
>
<b^x, b^y>
<bx,by>来量化。
为了将不同的模态转换为统一的二值码,我们学习了跨模态输入的两个特定于模态的哈希函数。
具体来说,两个哈希函数分别表示为:
- 图像模态: f x ( x , Θ x ) f^x(x, \Theta^x) fx(x,Θx)
- 文本模态:
f
y
(
y
,
Θ
y
)
f^y(y, \Theta^y)
fy(y,Θy)
- Θ x \Theta^x Θx和 Θ y \Theta^y Θy是需要学习的相应的特定模态的网络参数
在UCCH中,对于第 i i i个图像和第 j j j个文本,哈希函数的输出分别定义为:
- h i x = f x ( x i ) h_i^x = f^x(x_i) hix=fx(xi)
- h i y = f y ( y i ) h_i^y = f^y(y_i) hiy=fy(yi)
使用学习到的哈希函数,通过对
h
i
∗
h_i^*
hi∗应用
s
i
g
n
sign
sign函数来计算样本的二值表示:
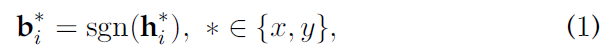
- s g n ( x ) sgn(x) sgn(x)是符号函数,如果 x ≥ 0 x≥0 x≥0其值为1,否则为0.
为了学习哈希函数,提出了一种新的无监督目标函数来强制网络消除跨模态差异。与有监督方法不同,UCCH采用对比学习来挖掘图像-文本对之间的表现相似性,而不是标签。
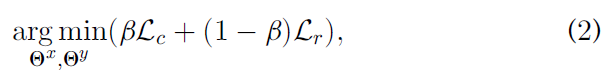
β ( 0 < β < 1 ) \beta (0<\beta<1) β(0<β<1)是一个权衡超参数,用于平衡对比哈希损失 L c L_c Lc 和跨模态排序损失 L r L_r Lr 。
Contrastive Cross-Modal Hashing Learning
对比学习的目的是利用query-key pairs的相似和不相似关系来学习判别表示。这也可以被认为是一个查字典问题。
与现有的对比学习方法不同,我们提出了一种特定任务的对比跨模态哈希学习方法(CCH),利用所有模态的统一二值字典。
在没有连续松弛的情况下,对于给定的查询 h i ∗ ( ∗ ∈ { x , y } ) h_i^*(* \in \{x,y\}) hi∗(∗∈{x,y}),其目的是直接从字典中的哈希点 { k 1 , k 2 , … , k n } \{k_1,k_2,\dots,k_n\} {k1,k2,…,kn}直接检索相关/正键值(correlated/positive keys)。
此外,字典的第 i i i 个key k i k_i ki 对应于第 i i i个图像-文本对。
在无监督跨模态情况下,字典中有一个单一的正key(表示为 k i + k_i^+ ki+),它与查询 h i ∗ ( ∗ ∈ { x , y } ) h_i^*(* \in \{x,y\}) hi∗(∗∈{x,y}) 相匹配。
对比损失用来评价查询 h i ∗ ( ∗ ∈ { x , y } ) h_i^*(* \in \{x,y\}) hi∗(∗∈{x,y})与检索结果 { k i } i = 1 n \{k_i\}_{i=1}^n {ki}i=1n之间的相似性,其值在 h i ∗ ( ∗ ∈ { x , y } ) h_i^*(* \in \{x,y\}) hi∗(∗∈{x,y})与其正key k i + k_i^+ ki+相似,而与其他所有keys(在查询中被视为负keys)不相似时较低。
问题一:大规模学习问题
在实践中,对于大型数据集,在大型字典上检索是不可行的。
为了解决大规模学习问题,我们随机抽取整个字典的一部分(被认为是hashing memory bank)作为一个新的小字典进行检索(图3)。
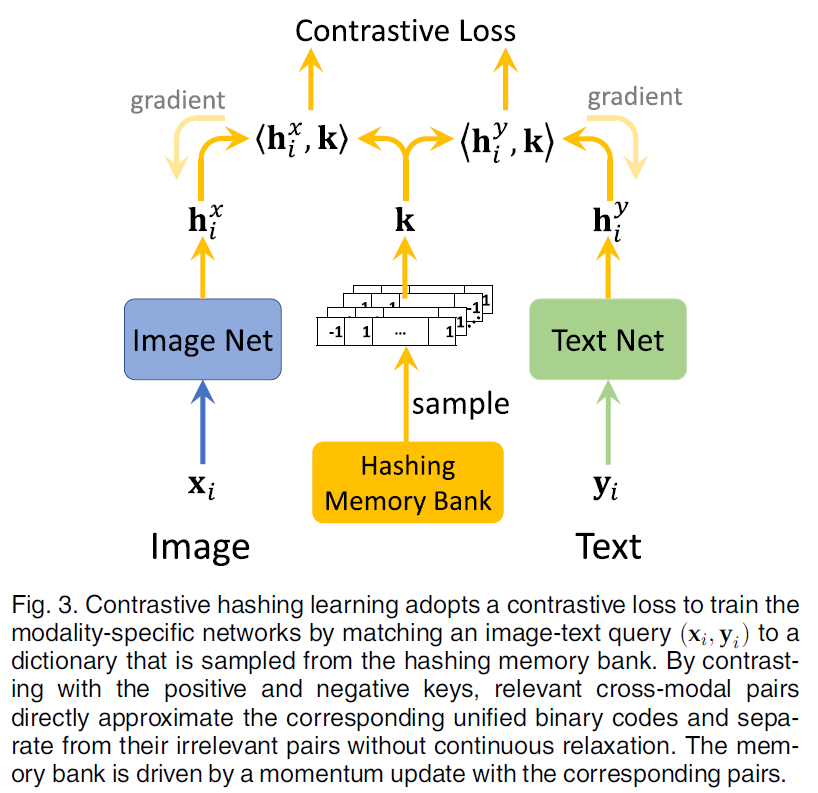
具体来说,与正key相反,我们从hashing memory bank中随机抽取 K K K个点来构建一个负例集 { k j − } j = 1 K \{k_j^-\}_{j=1}^K {kj−}j=1K,其中:
- k j − = s g n ( v r ) k_j^- = sgn(v_r) kj−=sgn(vr)
- v r v_r vr是 k j − k_j^- kj−对应的连续值源键continuous-valued source key
- r r r为对应的随机索引
通过 l 2 l_2 l2-normalization归一化使得
- ∥ h ∗ ∥ = 1 ( ∗ ∈ { x , y } ) \parallel h^* \parallel = 1(* \in \{x,y\}) ∥h∗∥=1(∗∈{x,y})
- ∥ k ⋇ ∥ = 1 ( ⋇ ∈ { + , − } ) \parallel k^\divideontimes \parallel = 1(\divideontimes \in \{+,-\}) ∥k⋇∥=1(⋇∈{+,−})
正如前面讨论的,不同哈希点之间的相似性是通过点积来衡量的。对于点积相似度,采用了一种有效的对比损失函数InfoNCE来最大化实例级区别,最小化跨模态差异:
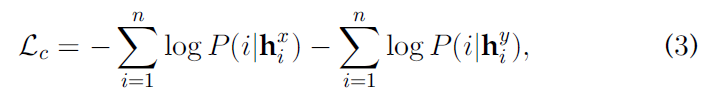
- P ( i ∣ h i x ) P(i|h_i^x) P(i∣hix) 和 P ( i ∣ h i y ) P(i|h_i^y) P(i∣hiy)分别是 h i x h_i^x hix 和 h i y h_i^y hiy被识别为第 i i i个点的概率。
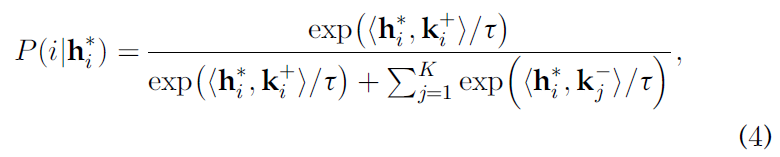
- ∗ ∈ { x , y } * \in \{x,y\} ∗∈{x,y}
- τ \tau τ 是温度超参数
直观的说,这个损失函数也可以被看作是一个基于( K + 1 K+1 K+1)-way 非参数softmax分类器的负对数似然。
与传统的基于softmax的分类器不同,上述公式旨在将第 i i i个图像-文本对(即 h i x h_i^x hix 和 h i y h_i^y hiy)分类为memory bank中对应的正key(即第 i i i个哈希点 k i + k_i^+ ki+)。
问题二:二值优化问题
字典的另一个挑战就是二值优化。
因此,eq. (3)中的哈希对比损失强制样本近似其正key的哈希码,并区分其负key的离散表示。
与现有的跨模态哈希方法不同,我们的UCCH直接学习离散表示,不需要连续松弛。
然而,直接优化离散存储是一个NP难问题。
为了使hashing memory bank是可学习的,我们将其符号幅度定义为
{
v
i
}
i
=
1
n
\{v_i\}_{i=1}^n
{vi}i=1n。相应的哈希keys可以通过
k
i
=
s
g
n
(
v
i
)
k_i=sgn(v_i)
ki=sgn(vi)获得。
然后使用动量机制来更新memory bank
{
v
i
}
i
=
1
n
\{v_i\}_{i=1}^n
{vi}i=1n:
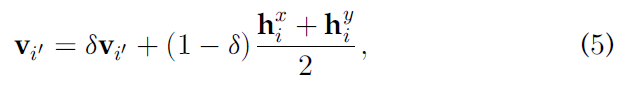
- δ ∈ [ 0 , 1 ) \delta \in [0,1) δ∈[0,1) 是动量系数
-
v
i
′
v_{i'}
vi′ 是在batch
{
x
i
,
y
j
}
j
=
1
N
b
\{x_i, y_j\}_{j=1}^{N_b}
{xi,yj}j=1Nb中采样的多模态对
{
x
i
,
y
i
}
\{x_i, y_i\}
{xi,yi} 中导出的正key
k
i
+
k_i^+
ki+ 的 memory bank 中第
i
i
i 个位置的值
- N b N_b Nb 是batch size
- i ′ i' i′ 是mini-batch的第 i i i对在memory bank中的对应位置。
Cross-Modal Ranking Learning
除了从统一的哈希字典中检索外,还需要将模型训练与下游任务的性能(即跨模态检索)连接起来。
为了实现这个目标,相关对的相似性被强制大于不相关对的跨模态样本的相似性。
具体来说,首先使用图像查询
h
i
x
h_i^x
hix 从文本字典中检索共现样本co-occurred sample
h
i
y
h_i^y
hiy。直观来看,查询
h
i
x
h_i^x
hix 与相关点
h
i
y
h_i^y
hiy 之间的相似度应该大于
h
i
x
h_i^x
hix 与不相关样本
{
h
j
y
}
j
≠
i
n
\{h_j^y\}_{j≠i}^n
{hjy}j=in 之间的相似度。
这同样适用于文本查询
h
i
y
h_i^y
hiy 和相关图像
h
i
x
h_i^x
hix。
为了实现这个目标,在多模态学习中广泛采用 双向最大间隔排序损失(bidirectional max-margin ranking loss) 来强制执行这一约束。
max-margin ranking loss:
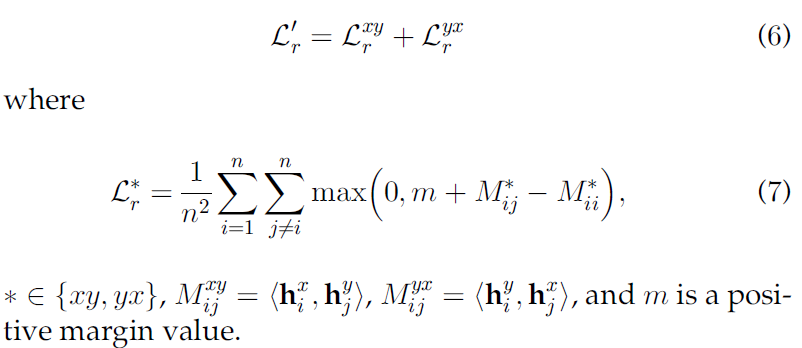
由Eq. (6)可知,最大间隔损失旨在优化相似度不小于正对(positive pairs) m m m 的困难负对(hard negative pairs)上(即 M i i ∗ − M i j ∗ < m M_{ii}^* - M_{ij}^* <m Mii∗−Mij∗<m,从而忽略了比较容易的对。
换句话说,vanilla triplet loss主要集中在较难得负对上,其性能在很大程度上取决于已经建立的负样本。
然而,在无监督环境下,由于成对/共现样本总是被当作正对,而其他样本被视为负对,因此很难保证负对的正确性。
显然,这种对构建策略会错误地将一些类内样本视为负的,这些FNP会导致vanilla triplet loss错误的优化方向。
更具体地说,max-margin loss强调分离FNPs而会忽略真负对TNPs,因为前者由于FNP之间的语义相关性而比后者更难分离。
为了克服FNP的挑战,我们提出了一种新的学习范式,称为跨模态排序学习CRL,它使用所有的负对进行优化。
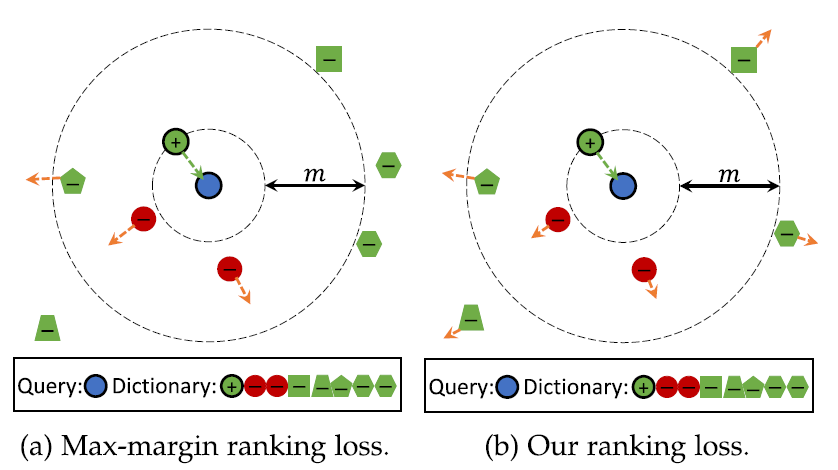
图4直观的说明了最大间隔损失和CRL之间的区别。
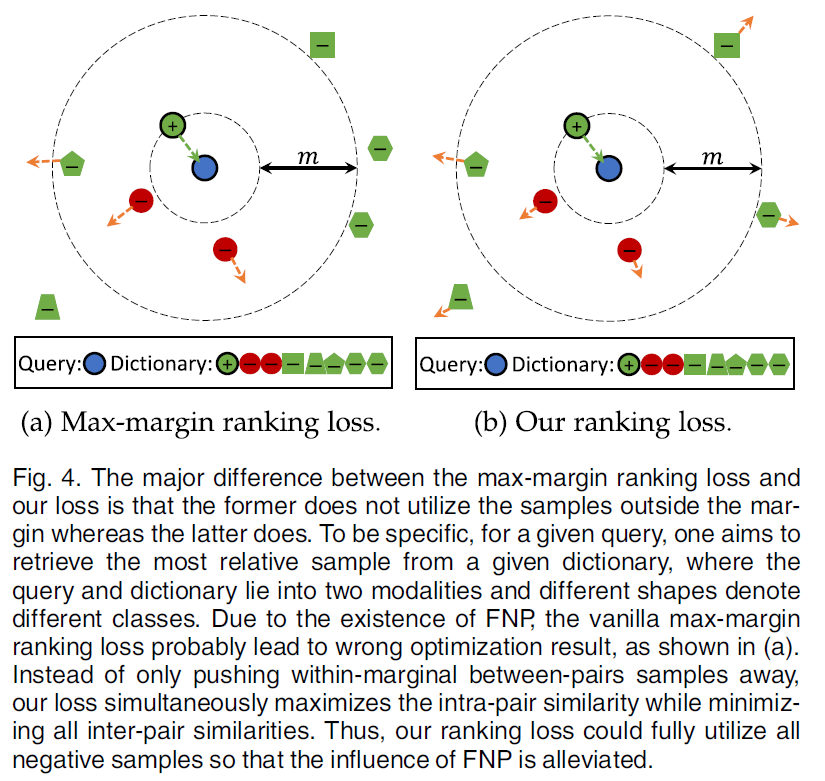
如图所示,可以看到max-margin ranking loss只关注间隔内的对间样本(inter-pair sample),而忽略了间隔外的对间样本。
如果没有语义标签,它可能会关注FNP,忽略TNP,如图4(a)所示。
与max-margin loss不同,提出的CRL方法可以充分利用所有的负样本,缓解FNP的影响,如图4(b)所示。
为了利用所有的负对,包括忽略的负对,我们同时考虑边界内外的负样本,构造了最大边界的上界。
首先,令:
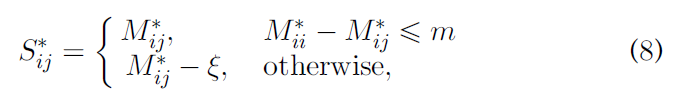
- ξ > 0 \xi>0 ξ>0
因此, S i j ∗ S_{ij}^* Sij∗ 永远不大于 M i j ∗ M_{ij}^* Mij∗ .
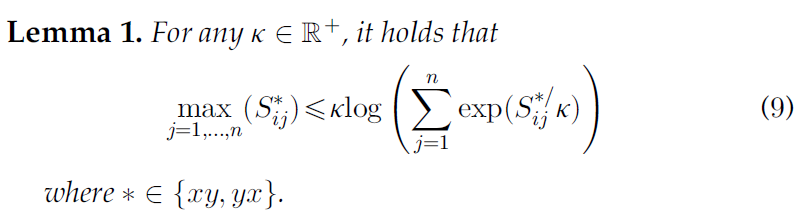
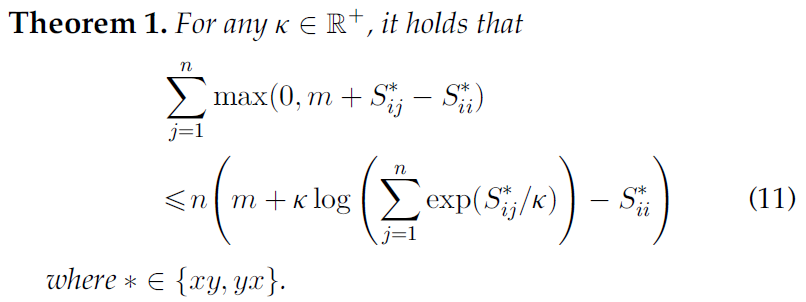
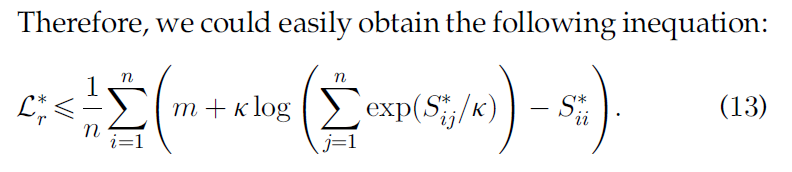
那么,我们可以将Eq. (6) 的最小化转化为最小化其上界:
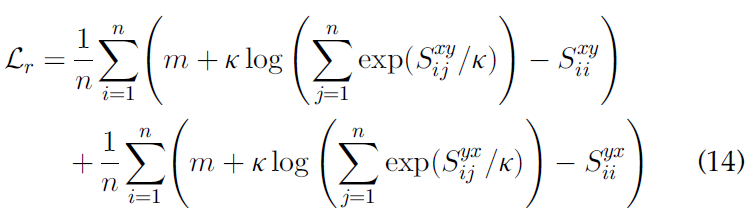
- m m m 是一个如图4所示的边界约束margin constraint
通过最小化Eq. (14) ,训练跨模态网络分散所有的对间样本(inter-pair samples)。
与传统的max-margin ranking loss L r ′ ′ L'_{r'} Lr′′ 不同,我们的跨模态排序损失 L r L_r Lr 可以同时将从上到下的排序无关样本分散开来,而不是只关注最上面的样本。
此外,我们的方法更关注顶部不相关的样本(被认为是更难的点),而不是底部的样本,因此顶部的样本可以与查询充分的分离开。
同时,loss还会压缩正样本(即相关的图像-文本对)以消除跨模态差异。
Optimization
学习最优哈希函数的过程是 通过联合最小化对比哈希损失
L
c
L_c
Lc 和跨模态排序损失
L
r
L_r
Lr 。联合损失如下:
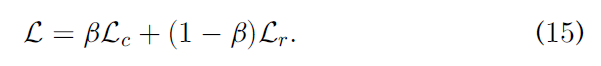
我们的UCCH可以逐批次(batch-by-batch)迭代优化。
通过最小化 L c ′ L_{c'} Lc′,UCCH通过实例级判别学习来学习捕获明显的相似性,并在没有连续松弛的情况下将多模态数据编码为二值码。
此外,跨模态检索度量被直接添加到学习过程中,以弥合跨模态差距。
UCCH的整个模型可以通过使用任何一种随机梯度下降优化算法进行优化,例如Adam。
算法1总结了UCCH的优化过程。



















 1478
1478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









