









 本文介绍了一种应用于零样本学习的通用算法框架,该框架由ICCV2017收录,通过将语义属性映射到视觉特征空间,增强算法效果。算法利用聚类结构优势,确保预测语义表示与视觉特征代表接近,采用多核回归建立联系。
本文介绍了一种应用于零样本学习的通用算法框架,该框架由ICCV2017收录,通过将语义属性映射到视觉特征空间,增强算法效果。算法利用聚类结构优势,确保预测语义表示与视觉特征代表接近,采用多核回归建立联系。
2017-2019年计算机视觉顶会文章收录 AAAI2017-2019 CVPR2017-2019 ECCV2018 ICCV2017-2019 ICLR2017-2019 NIPS2017-2019
转:https://zhuanlan.zhihu.com/p/29215437
论文《Predicting Visual Exemplars of Unseen Classes for Zero-Shot Learning》
论文地址:https://arxiv.org/pdf/1605.08151.pdf
该论文已被ICCV2017收录,针对Zero-Shot Learning(ZSL)问题,提出了一个新的简单的通用算法框架,它的motivation也很有意思:作者认为语义表示可能不需要包含能对样本进行分类的视觉属性。在实现方式上,框架利用了聚类结构的优点,保证预测的语义表示必须与相关的视觉特征代表(visual exemplars)尽量相近,通过多核回归(multiple kernel-based regressors)即可建立两者之间的关系,更简单的解释是:将语义属性映射到视觉特征空间中,并使其能够尽量匹配对应类别视觉特征的聚类中心。该理论框架可以应用到几乎任何现有的ZSL算法中,并使得算法的效果得到提升。
该框架的有效性主要依赖于两个方面:
1、认为语义表示和具有分类能力的低维视觉特征之间并没有非常之间的关系,因此假设了视觉特征的聚类中心作为类别的语义属性表示;
2、利用了聚类结构的优势来更好地处理ZSL问题。
算法内容
对于每一个类别c,我们希望能够将其映射到视觉特征空间中,并且尽量与类别c的视觉特征聚类中心相似,即有
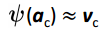
其中  为类别c的语义属性表示, 为需要学习的映射函数, 为c类样本视觉特征的聚类中心。聚类中心的获取方法也非常简单:在所有样本上做PCA,并对每一类取加和平均,这样每一个类别就可以表示为一个样本,被称为视觉特征代表(visual exemplars)。这里需要注意的是PCA是整个数据集上的PCA,而不是每一类分别做PCA。在具体实现函数 时,作者使用的是d个带RBF核的支持向量机,对视觉特征代表的d个维度,分别进行预测,这样就可以实现语义空间到视觉特征空间的映射。注意到这里是对每一维的视觉特征都学习一个SVM,有点像反向的DAP[1]。作者解释称之所以不进行联合学习是因为使用了PCA,去除了各个维度之间的相关性。
为类别c的语义属性表示, 为需要学习的映射函数, 为c类样本视觉特征的聚类中心。聚类中心的获取方法也非常简单:在所有样本上做PCA,并对每一类取加和平均,这样每一个类别就可以表示为一个样本,被称为视觉特征代表(visual exemplars)。这里需要注意的是PCA是整个数据集上的PCA,而不是每一类分别做PCA。在具体实现函数 时,作者使用的是d个带RBF核的支持向量机,对视觉特征代表的d个维度,分别进行预测,这样就可以实现语义空间到视觉特征空间的映射。注意到这里是对每一维的视觉特征都学习一个SVM,有点像反向的DAP[1]。作者解释称之所以不进行联合学习是因为使用了PCA,去除了各个维度之间的相关性。
在预测时,只要将所有的unseen类别通过函数 投影到视觉特征空间,再使用最近邻分类器对测试集的样本进行分类即可。当然也可以将预测得到的视觉特征代表作为新的类别语义表示,这样就可以将该算法嵌入到几乎任何一种现有的ZSL算法中。
算法框架图如图1所示
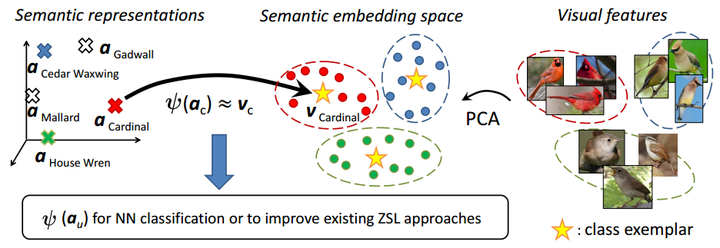
图1 算法框架
该模型的一个重要优势是其计算复杂度只与类别的数量有关,这就大大降低了该算法在实际应用中面对海量数据情况下的效率。
其实到这,整个算法就介绍完了,如此简单的motivation和算法框架,再加上后面充分的实验证明,组成了这篇ICCV,这不得不佩服作者的能力。
一些实验结果
该算法的有效性基于一个这样的假设:预测得到的视觉特征代表相比于语义表示,能够更好地反映类别之间的视觉相似性,从而能够对类别进行更好地划分。由此作者做了一个相关的证明实验。令 表示基于语义属性表示的unseen类别之间的欧氏距离矩阵; 表示unseen类别基于预测的视觉特征代表的距离矩阵; 表示unseen类别基于真实的视觉特征代表的距离矩阵。由表1所示, 与 之间的相关性要高于 与 之间的相关性,这也就说明了视觉特征代表要比语义特征代表有着更好的类别代表性。如图2所示,表示视觉特征代表能够较好地与其对应类别的样本保持一致。
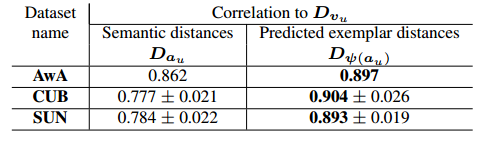
表1 相关性得分

总结
顶会的文章总是会给人带来一些惊喜,这篇文章提出了简单有效的motivation和算法框架,并用大量实验证明了其有效性,读者可以看看文章附录中的实验及其结论,也许能够受到不错的启发。
参考
[1]Learning To Detect Unseen Object Classes by Between-Class Attribute Transfer.

















 1744
1744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









