







本次为各位同学准备的是spark高频八股–spark的shuffle过程~
创作不易!多多支持!
文章目录
面筋
当Spark执行partitionBy、groupByKey、reduceByKey、sortByKey等操作时,会发生shuffle,说白了就是让数据重新洗牌一次,让某些数据放到同一分区。执行示意图如下:
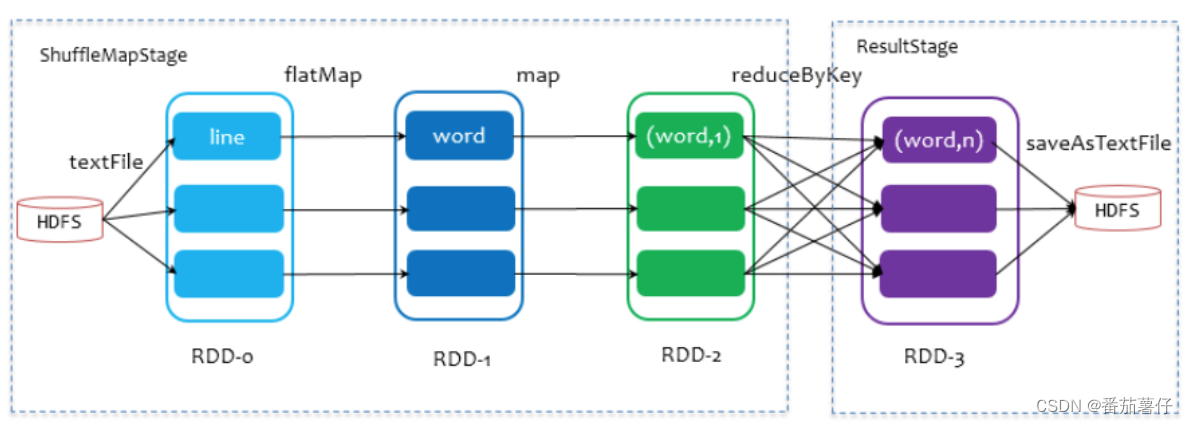
那同样要执行shuffle操作的RDD算子列表如下:
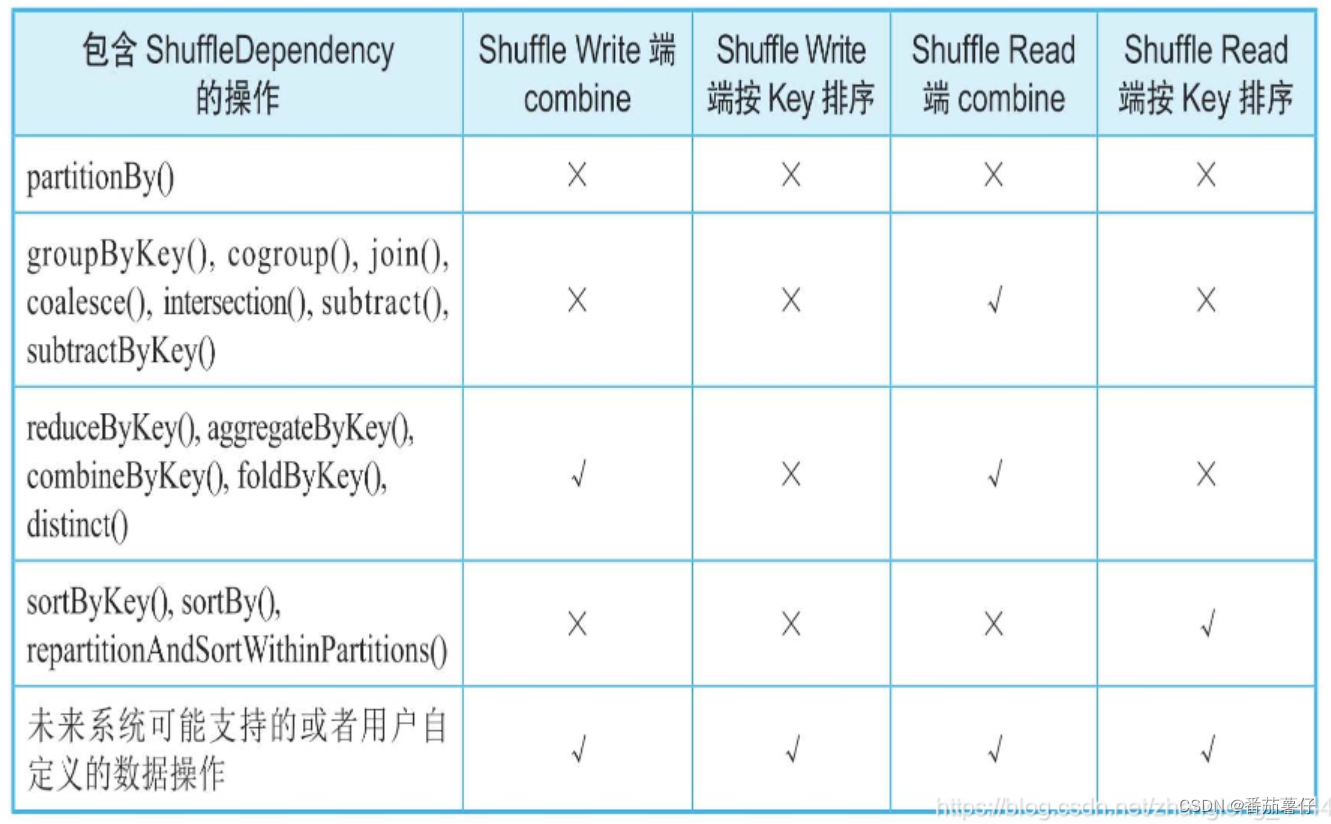
可以观察到有的算子需要combine,有的算子需要按key排序,这些包含的步骤也会在下面的代码中体现出来。
shuffle包含三种实现方式:
SortShuffleWriter这种是默认的shuffle方式,支持map端聚合,也支持按key排序BypassMergeSortShuffleWriter当reduce小于默认的spark.shuffle.sort.bypassMergeThreshold(默认为 200),且不是聚合类的RDD的时候,才可以使用。UnsafeShuffleWriter
默认的sort shuffle
数据先写入一个数据结构,reduceByKey写入Map,一边通过Map局部聚合,一边写入内存,写的过程中判断是否到达阈值,如果达到了阈值就会把内存中的数据溢写到磁盘文件,然后清空内存,并且继续写。
在溢写磁盘文件前,会根据key进行排序,排序后再按10000条数据批次写入磁盘,每次溢写都会产生一次临时文件。
将所有数据写出完成后, 就会通过merge方法合并临时文件,写入到一个最终文件,这表明了一个task的所有shuffle写的数据都在这个文件中。此外,还有一份索引文件,标示着下游各个task的数据在文件中的start offset与end offset。
默认的SortShuffle方式通过合并磁盘文件的方式,减少了文件数量,提高性能。如第一个stage有50个task,总共有10个Executor,每个Executor执行5个task,而第二个stage有100个task。由于每个task最终只有一个磁盘文件,因此此时每个Executor上只有5个磁盘文件,所有Executor只有50个磁盘文件。图片来源
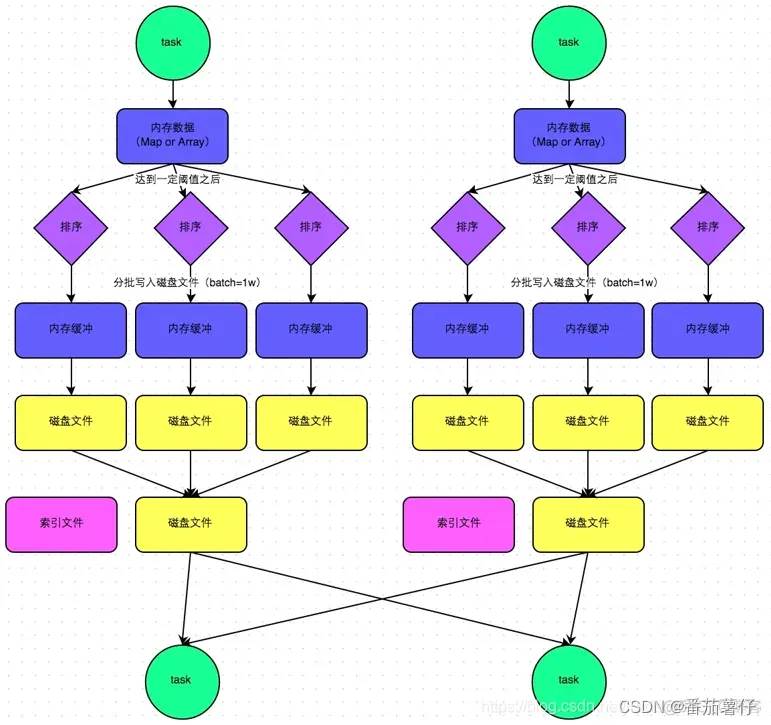
bypass sort shuffle
bypass运行机制的触发机制如下:
- shuffle reduce task数量小于spark.shuffle.sort.bypassMergeThreshold参数的值,默认为200
- 不是聚合类的shuffle算子(比如reduceByKey)
使用这种shuffle的时候,task会为每个reudce端的task都创建也给临时磁盘文件,并且将数据按key进行hash然后根据key的值,将key写入到对应的磁盘文件中(先缓冲,再溢出)。
该过程会创建数量巨大的磁盘文件,只是在最后做一个磁盘文件的合并。
该机制与普通sortshuffle的机制不同在于,bypassshuffle不会进行排序,这样在reduce task少量的情况下减少数据的排序操作,因此可以额节省这部分的性能开销。图片来源
tungen sort shuffle
map端和reduce端数据交接
经过上述说的sort shuffle的处理,它的计算结果会写到BlockMnager之中,最终会通过MapStatus的封装返回给DAGScheduler,这个MapStatus保存了ShuffleMapTask的相关存储信息。后续的Reduce的task想要获取map端输出的数据的时候,使用mapOutputTracker.getMapSizesByExecutorId获取driver端的存储的存储信息,定位到去哪来fetch数据。
在reduce端读取数据时,每个shuffle read task只要从上游stage的所有task所在节点上,拉取属于自己的那一个磁盘文件即可。这个过程中,会根据数据的本地行原则进行数据获取shuffle read,优先获取本地数据,如果本地数据不存在存储的block,才使用netty通信获取远处节点的block。
shuffle read的拉取过程是一边拉取一边聚合的。每个shuffle read task都有自己的buffer缓冲,每次都智能拉取与buffer 缓冲相同大小的数据,然后再进行聚合等操作。聚合完一批数据后,再拉取下一批数据,并放到buffer缓冲中进行聚合操作,直至把数据拉取完成。
好了,面筋已经讲完,接下来就是令人心烦的阅读源码时刻!
什么时候触发shuffle
当Spark执行partitionBy、groupByKey、reduceByKey、sortByKey等操作时,会发生shuffle。
比如当我使用reduceByKey的时候,对着这个方法一直点点点,最后会进入到PairRDDFunctions.combineByKeyWithClassTag中,可以看到这里执行了如下代码:
// 创建了shuffledRDD
new ShuffledRDD[K, V, C](self, partitioner)
.setSerializer(serializer)
.setAggregator(aggregator)
.setMapSideCombine(mapSideCombine)
}
顾名思义,这就是创建了ShuffledRDD,表明要执行shuffle,其中aggrgator、mapsidecombine的操作在后续shuffle的过程中也会出现,需要注意一下。
stage由RDD的宽窄依赖切分,shuffle过程只有在stage与stage之间才会运行。
shuffle write的详细过程
如何选择writer
当ShuffleMapTask.runTask反序列化任务的RDD、依赖和mapId之后,调用了
// 用来将结果写入Shuffle管理器
dep.shuffleWriterProcessor.write(rdd, dep, mapId, context, partition)
这个方法是特定分区的写进程,它控制从 ShuffleManager 获取的 ShuffleWriter 的生命周期,并触发 RDD 计算,最后返回该任务的 MapStatus。
def write(
rdd: RDD[_],
dep: ShuffleDependency[_, _, _],
mapId: Long,
context: TaskContext,
partition: Partition): MapStatus = {
var writer: ShuffleWriter[Any, Any] = null
try {
// 实例化shuffleManager
val manager = SparkEnv.get.shuffleManager
// 然后从shuffleDependency中获取注册到ShuffleManager时得到的shufflehandle
// 根据shufflehandle和当前Task对应的分区ID,获取ShuffleWriter
writer = manager.getWriter[Any, Any](
dep.shuffleHandle,
mapId,
context,
createMetricsReporter(context))
// 将计算结果通过writer对象的write方法写入shuffle过程
writer.write(
// 会调用RDD的iterator,然后针对partition进行计算
rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
writer.stop(success = true).get
} catch {
case e: Exception =>
try {
if (writer != null) {
writer.stop(success = false)
}
} catch {
case e: Exception =>
log.debug("Could not stop writer", e)
}
throw e
}
可以从上述方法中看到了ShuffleManager调用的这个方法
writer = manager.getWriter[Any, Any](
dep.shuffleHandle,
mapId,
context,
createMetricsReporter(context))
就是这里通过dep.shuffleHandle来选取UnsafeShuffleWriter/UnsafeShuffleWriter/SortShuffleWriter。而这个dep.shuffleHandle怎么定义的,在面筋也已经详细写出。
随后下一步就是调用RDD的iterator,将计算结果通过write方法写出
// 将计算结果通过writer对象的write方法写出
writer.write(
// 会调用RDD的iterator,然后针对partition进行计算
rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
这里的writer.write有三个实现,分别是UnsafeShuffleWriter/UnsafeShuffleWriter/SortShuffleWriter的write实现。这里将分别讲述其中的过程。
SortShuffleWriter.write过程解析
Write a bunch of records to this task’s output 然后在计算具体的Partition之后,通过shuffleManager获得的shuffleWriter把当前Task计算的结果根据具体的shuffleManager实现写入到 具体的文件中,操作完成后会把MapStatus发送给Driver端的DAGScheduler的MapOutputTracker。
这个过程中需要考虑如下情况:
- 在insertAll之前有判断,在Mapper端是否要进行聚合,如果没有进行聚合, 将按照Partition写入到不同的文件中,最后按照Partition顺序合并到同样一个文件中。 在这种情况下,适合Partition的数据比较少的情况;那我们将很多的bucket合并到一个文件, 减少了Mapper端输出文件的数量,减少了磁盘I/O,提升了性能。
- 除了既不想排序,又不想聚合的情况,也可能在Mapper端不进行聚合,但可能进行排序, 这在缓存区中根据PartitionID进行排序,也可能根据Key进行排序。最后需要根据PartitionID进行排序, 比较适合Partition比较多的情况。如果内存不够用,就会溢写到磁盘中 。
- 第三种情况,既需要聚合,也需要排序,这时肯定先进行聚合,后进行排序。 实现时,根据Key值进行聚合,在缓存中根据PartitionID进行排序,也可能根据Key进行排序, 默认情况不需要根据Key进行排序。最后需要根据PartitionID进行合并,如果内存不够用, 就会溢写到磁盘中。
override def write(records: Iterator[Product2[K, V]]): Unit = {
// 当需要在Map端进行聚合操作时,此时将会指定聚合器(Aggregator)
// 将key值的Ordering传入到外部排序器ExternalSorter中
sorter = if (dep.mapSideCombine) {
new ExternalSorter[K, V, C](
context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer)
} else {
// In this case we pass neither an aggregator nor an ordering to the sorter, because we don't
// care whether the keys get sorted in each partition; that will be done on the reduce side
// if the operation being run is sortByKey.
// 没有指定Map端使用聚合时,传入ExternalSorter的聚合器与key值的ordering都设为None,即不需要传入,对应在Reduce端读取数据时
// 才根据聚合器分区数据进行聚合,并根据是否设置Ordering而选择是否对分区数据进行排序
new ExternalSorter[K, V, V](
context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer)
}
// 将写入的记录的记录集全部放入外部排序器
// 基于sorter具体排序的实现方式,将数据写入缓冲区中。如果records数据特别多,可能会导致内存溢出,Spark现在的实现方式是Spill溢出写到磁盘中
// 外部排序器的insertAll方法内部在处理完每条记录时,都会检查是否需要Spill,具体看Spilabel中的maybeSpill
sorter.insertAll(records)
// Don't bother including the time to open the merged output file in the shuffle write time,
// because it just opens a single file, so is typically too fast to measure accurately
// (see SPARK-3570).
// 不要费心在Shuffle写时间中,包括打开合并输出文件的时间,因为它只打开一个文件,所以通常太快,无法精确测量
// 和BypassMergeSortShuffleWriter一样,获取输出文件名和BlockId
val mapOutputWriter = shuffleExecutorComponents.createMapOutputWriter(
dep.shuffleId, mapId, dep.partitioner.numPartitions)
sorter.writePartitionedMapOutput(dep.shuffleId, mapId, mapOutputWriter)
// 将分区数据写入文件,返回各个分区对应的数据量
val partitionLengths = mapOutputWriter.commitAllPartitions().getPartitionLengths
// map在最后地时候我们将元数据写入到MapStatus,MapStatus返回给Driver,
// 这里是元数据信息,Driver根据这个信息告诉下一个Stage,你的上一个Mapper的数据写在什么地方。下一个Stage就根据MapStatus得到上一个Stage的处理结果。
mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths, mapId)
}
这里重点关注sorter.insertAll(records),这里将写入的记录全部放入外部排序其,基于sorter具体排序的实现方式,将数据写入缓冲区。如果records数据特别多,可能会导致内存溢出,所以Spark通过spill方法溢出将数据写到磁盘中,在这过程中没处理完一条数据,都会检查是否需要spill。
def insertAll(records: Iterator[Product2[K, V]]):Unit = {
// TODO: stop combining if we find that the reduction factor isn't high
val shouldCombine = aggregator.isDefined
// shouldCombine判断是否需要聚合。一个基本的问题:
// 怎么知道是否需要聚合?算子和算子的配置参数决定了是否需要聚合。如果为true,
// 使用AppendOnlyMap首先在内存对值进行组合。
if (shouldCombine) {
// Combine values in-memory first using our AppendOnlyMap
// 使用AppendOnlyMap,首先在内存中组合值
val mergeValue = aggregator.get.mergeValue
val createCombiner = aggregator.get.createCombiner
var kv: Product2[K, V] = null
// update是偏函数。如果有值,就将新的value和旧的value进行合并;如果hadValue是false,则新建combiner,
// 相当于没有旧的值。从Hadoop的角度讲,Merge相当于hadoop的combiner,相同Key的Value进行聚合
val update = (hadValue: Boolean, oldValue: C) => {
if (hadValue) mergeValue(oldValue, kv._2) else createCombiner(kv._2)
}
while (records.hasNext) {
addElementsRead()
kv = records.next()
// 调用了偏函数update,又更新了Value值
// map是AppendOnlyMap,是一个HashMap
map.changeValue((getPartition(kv._1), kv._1), update)
// 是否需要Splii
maybeSpillCollection(usingMap = true)
}
} else {
// 如果没有聚合,就直接在Buffer数据结构中插入一条记录
// Stick values into our buffer
// 将值插入缓冲区
while (records.hasNext) {
addElementsRead()
val kv = records.next()
buffer.insert(getPartition(kv._1), kv._1, kv._2.asInstanceOf[C])
maybeSpillCollection(usingMap = false)
}
}
}
关注到map.changeValue((getPartition(kv._1), kv._1), update),以及buffer.insert(getPartition(kv._1), kv._1, kv._2.asInstanceOf[C]),这里的map其实就是PartitionedAppendOnlyMap,这里的buffer其实就是PartitionedAppendOnlyMap,这两个数据结构就是在溢出前存储内存中的对象,根据是否有聚合器聚合,要么将对象放入到AppendOnlyMap中进行组合,要么将其存储到buffer中。
- spark没有使用jdk自带的map结构,而是使用一个数组实现map功能
- 计算key的hash值的位置pos,2pos,如果2pos位置没有数据,则在2pos的位置放入key,2pos +1 的位置放入value,如果2*pos上有值,计算key是否等于,如果等于,则用传入的函数更新,如wordcount中的reduceByKey(_ + _), 计算出新的value后更新,如果不等于,则通过(pos + delta) & mask 的方法重新计算hash值得位置,delta 从1开始,遇到key存在每次递增1
- 每次插入后,会判断当前大约容量,通过估算得方式计算占用的内存,每32次估算一次,如果大于当前的内存,就会向taskMemoryManager.acquireExecutionMemory申请内存,如果申请成功,则继续写入,如果写入不成功,则spill磁盘,所以,第一个优化点,理论上executor内存越大,在内存可存储的数据越多,spill磁盘的次数越少,速度越快。 spill的过程,调用collection.destructiveSortedWritablePartitionedIterator(comparator),首先会将数据往前移动,填满中间空缺的位置,然后将内存中的数据进行排序,用的排序算法是TimSort,最后按照分区且排序的形式写入文件中。
- spark没有使用jdk自带的list结构,而是使用一个数组实现list功能
- 功能比较简单,不需要mapCombine,只需要将数据按照kv追加到数组后面,spill溢写磁盘与PartitionedAppendOnlyMap一样,将数据排序后(分区且排序,不需要移动数据,填充空缺的位置,数据本身就是紧凑的)写入磁盘文件。
知晓了map和buffer的概念之后,接下来调用maybeSpillCollection来判断是否进行Spill,在其中继续执行maybeSpill。
在maybeSpill方法中,判断当前使用的内存,如果大于阈值myMemoryThreshold,就要申请内存空间acquireMemory。 一种情况,如果分配的内存太小,就返回0;另外一种情况,如果超过了阈值, 就导致当前需要的内存大小需要Spill。但在Spill之前会先扩容一次
protected def maybeSpill(collection: C, currentMemory: Long): Boolean = {
var shouldSpill = false
// 1.检查当前记录数是否是32的倍数--即对小批量的记录集进行Spill
// 2.同时,当前需要的内存大小是否达到或超过了当前分配的内存阈值
if (elementsRead % 32 == 0 && currentMemory >= myMemoryThreshold) {
// Claim up to double our current memory from the shuffle memory pool
// 从Shuffle内存池中获取当前内存的两倍
val amountToRequest = 2 * currentMemory - myMemoryThreshold
// 实际上会先申请内存,然后再次判断,最后决定是否Spill
val granted = acquireMemory(amountToRequest)
myMemoryThreshold += granted
// If we were granted too little memory to grow further (either tryToAcquire returned 0,
// or we already had more memory than myMemoryThreshold), spill the current collection
// 内存很少时,如果准许内存进一步增长(trayToAcquire返回0,或者myMemoryThreshold更多的内存),当前的collection将会溢出
shouldSpill = currentMemory >= myMemoryThreshold
}
// 当满足下列条件之一时,需要Spill,条件如下
// 1.当前判断是否为true
// 2.从上次Spill之后所读取的记录数超过配置的阈值时
shouldSpill = shouldSpill || _elementsRead > numElementsForceSpillThreshold
// Actually spill
if (shouldSpill) {
_spillCount += 1
logSpillage(currentMemory)
// 溢出
spill(collection)
_elementsRead = 0
_memoryBytesSpilled += currentMemory
releaseMemory()
}
shouldSpill
}
当最终还是决定需要shouldSpill的时候,执行了spill操作,在这里将内存中的集合溢出到一个排序文件中,以便稍后进行合并。我们将该文件添加到 spilledFiles 中,以便稍后查找。
override protected[this] def spill(collection: WritablePartitionedPairCollection[K, C]): Unit = {
// 据指定的比较器comparator进行排序,返回排序结果的迭代器
// 按照分区排序、分区相同则按键对排序
val inMemoryIterator = collection.destructiveSortedWritablePartitionedIterator(comparator)
// 生成一个溢写文件
val spillFile = spillMemoryIteratorToDisk(inMemoryIterator)
spills += spillFile
}
至此,所有的shuffle文件输出已经写出,接下来回到SortShuffleWriter.write中的sorter.insertAll(records),稍后执行sorter.writePartitionedMapOutput(dep.shuffleId, mapId, mapOutputWriter).
点击进入writePartitionedMapOutput方法,可以看到按照spills.isEmpty判断有没有溢出的文件:
-
如果没有,则对内存中的文件直接进行排序,然后写入到后备存储中;
-
如果有溢出文件,则对spill出来的文件归并排序,然后按照不同的reduceId写输出文件。
-
具体来说调用this.partitionedIterator来遍历归并spill出来的文件,即将这些数据按分区分组,并按请求的聚合器聚合。
-
def partitionedIterator: Iterator[(Int, Iterator[Product2[K, C]])] = { val usingMap = aggregator.isDefined val collection: WritablePartitionedPairCollection[K, C] = if (usingMap) map else buffer if (spills.isEmpty) { // Special case: if we have only in-memory data, we don't need to merge streams, and perhaps // we don't even need to sort by anything other than partition ID // 特殊情况:如果我们只有内存数据,我们不需要合并流,也许我们甚至不需要按分区ID以外的任何东西进行排序 if (ordering.isEmpty) { // The user hasn't requested sorted keys, so only sort by partition ID, not key // 用户没有请求排序的键,因此只按分区ID排序,而不按键排序 groupByPartition(destructiveIterator(collection.partitionedDestructiveSortedIterator(None))) } else { // We do need to sort by both partition ID and key // 我们确实需要按分区ID和键进行排序 groupByPartition(destructiveIterator( collection.partitionedDestructiveSortedIterator(Some(keyComparator)))) } } else { // Merge spilled and in-memory data // 合并溢出和内存数据 merge(spills.toSeq, destructiveIterator( collection.partitionedDestructiveSortedIterator(comparator))) } } -
最后按照不同的reduceId写输出文件
-
for (elem <- elements) { // 按照不同的reduceId写输出文件 partitionPairsWriter.write(elem._1, elem._2) }
-
最后创建MapStatus对象,这个信息将返回至Driver,Driver将根据接受到的元数据信息告诉给下一个Stage的shufflereader,上一个stage中的map数据输出在哪里。
BypassMergeSortShuffleWriter.write过程解析
要召唤出BypassMergeSortShuffleWriter的方法,需要shuffle没有聚合操作,以及分区少于默认200个以下。
这里的操作为没有什么combine和sort,所以减少了部分性能损耗。
public void write(Iterator<Product2<K, V>> records) throws IOException {
// 为每个Reduce端的分区打开的DiskBlockObjectWriter存放于partitionWriters,需要根据具体的Reduce端的分区个数进行构建
assert (partitionWriters == null);
ShuffleMapOutputWriter mapOutputWriter = shuffleExecutorComponents
.createMapOutputWriter(shuffleId, mapId, numPartitions);
try {
if (!records.hasNext()) {
partitionLengths = mapOutputWriter.commitAllPartitions().getPartitionLengths();
// 下面代码的调用形式是对应在Java类中调用Scala提供的object中的apply方法的形式,是由编译器编译Scala中的object得到的结果来决定的
mapStatus = MapStatus$.MODULE$.apply(
blockManager.shuffleServerId(), partitionLengths, mapId);
return;
}
final SerializerInstance serInstance = serializer.newInstance();
final long openStartTime = System.nanoTime();
// 对应每个分区各配置一个磁盘写入器DisBLockObjectWriter
partitionWriters = new DiskBlockObjectWriter[numPartitions];
partitionWriterSegments = new FileSegment[numPartitions];
// 注意,在该写入方式下,会同时打开numPartitions个DiskBlockObjectWriter,
// 因此对应的分区数不应设置过大,避免带来过大的内存开销目前对应的DisBlockObjectWriter的缓存默认大小
// 配置为32KB,比早先的100KB降低了很多,但也说明不适合同时打开太多的DiskBlockObjectWriter实例
for (int i = 0; i < numPartitions; i++) {
final Tuple2<TempShuffleBlockId, File> tempShuffleBlockIdPlusFile =
// 其中调用的createTempShuffleBlock方法描述了各个分区生成的中间临时文件的 格式与对应的BlockId
blockManager.diskBlockManager().createTempShuffleBlock();
final File file = tempShuffleBlockIdPlusFile._2();
final BlockId blockId = tempShuffleBlockIdPlusFile._1();
partitionWriters[i] =
blockManager.getDiskWriter(blockId, file, serInstance, fileBufferSize, writeMetrics);
}
// Creating the file to write to and creating a disk writer both involve interacting with
// the disk, and can take a long time in aggregate when we open many files, so should be
// included in the shuffle write time.
// 创建文件写入和创建磁盘写入器都涉及与磁盘的交互,当打开许多文件时,磁盘写会花费很长时间,所以磁盘写入时间应包含在Shuffle写入时间内
writeMetrics.incWriteTime(System.nanoTime() - openStartTime);
// 读取每条记录,并根据分区器将该记录交由分区对应的DiskBlockObjectWriter写入各自对应的临时文件
while (records.hasNext()) {
final Product2<K, V> record = records.next();
final K key = record._1();
// 根据分区器写文件
partitionWriters[partitioner.getPartition(key)].write(key, record._2());
}
for (int i = 0; i < numPartitions; i++) {
try (DiskBlockObjectWriter writer = partitionWriters[i]) {
partitionWriterSegments[i] = writer.commitAndGet();
}
}
// 将所有按分区的文件连接到一个单独的组合文件中,返回:文件的每个分区的长度数组(以字节为单位)(由map output tracker使用)
partitionLengths = writePartitionedData(mapOutputWriter);
// 封装并返回任务结果
mapStatus = MapStatus$.MODULE$.apply(
blockManager.shuffleServerId(), partitionLengths, mapId);
} catch (Exception e) {
try {
mapOutputWriter.abort(e);
} catch (Exception e2) {
logger.error("Failed to abort the writer after failing to write map output.", e2);
e.addSuppressed(e2);
}
throw e;
}
}
值得注意的是partitionLengths = writePartitionedData(mapOutputWriter);,表明了将每个分区的所有文件合并为一个综合文件。
UnsafeShuffleWriter.write过程解析
Unsafe Shuffle Writer开启条件是对象序列化方式支持Relocation(即序列化的数据不需要反序列化,对其元数据进行排序后,在指定位置能读取该数据,目前只有Kryo序列化支持)、 任务中没有聚合、Reduce分区小于2^24个(24位存储分区ID)。
该Writer通过ShuffleExternalSorter将序列化数据存到MemoryBlock里面,同时将记录的Reduce分区ID、数据地址存储到ShuffleInMemorySorter的指针数组中,当ShuffleIn-MemorySorter存储条数达到阈值或者申请不到内存page时,对Shuffle InMemorySorter里面的数据按照分区ID进行排序然后根据地址按顺序拿到数据进行spill,最后将多个spill文件按分区ID进行全局排序,并根据排序后的指针地址顺序获取数据进行spill。
public void write(scala.collection.Iterator<Product2<K, V>> records) throws IOException {
// Keep track of success so we know if we encountered an exception
// We do this rather than a standard try/catch/re-throw to handle
// generic throwables.
boolean success = false;
try {
// 对输入的记录集records,循环将每条记录插入到外部排序器
while (records.hasNext()) {
insertRecordIntoSorter(records.next());
}
// closeAndWriteOutput方法写数据文件与索引文件,在写的过程中,会先合并外部排序器在插入过程中生成的Spill中间文件
closeAndWriteOutput();
// 生成最终的两个结果文件,和Sorted Based Shuffle的实现机制一样,每个Map端的任务对应生成一个数据(Data)文件
// 和对应的索引(Index)文件
success = true;
} finally {
if (sorter != null) {
try {
// sorter.cleanupResources()最后释放外部排序器的资源
sorter.cleanupResources();
} catch (Exception e) {
// Only throw this error if we won't be masking another
// error.
if (success) {
throw e;
} else {
logger.error("In addition to a failure during writing, we failed during " +
"cleanup.", e);
}
}
}
}
}
UnsafeShuffleWriter 里面维护着一个 ShuffleExternalSorter, 用来做外部排序, 外部排序就是要先部分排序数据并把数据输出到磁盘,然后最后再进行merge 全局排序, 既然这里也是外部排序,跟 SortShuffleWriter 有什么区别呢, 这里只根据 record 的 partition id 先在内存 ShuffleInMemorySorter 中进行排序, 排好序的数据经过序列化压缩输出到换一个临时文件的一段,并且记录每个分区段的seek位置,方便后续可以单独读取每个分区的数据,读取流经过解压反序列化,就可以正常读取了。
整个过程就是不断地在 ShuffleInMemorySorter 插入数据,如果没有内存就申请内存,如果申请不到内存就 spill 到文件中,最终合并成一个 依据 partition id 全局有序 的大文件。
参考链接:彻底搞懂spark的shuffle过程(shuffle write) - 大葱拌豆腐 - 博客园 (cnblogs.com)
将存储信息告诉DAGScheduler
在上文提到经过ShuffleWriter的处理之后会返回MapStatus,记录着BlockManagerId、BlockManagerId、BlockManagerId。这个MapStatus将由Executor.run中先序列化,然后将状态信息返回至DAGScheduler
/**
* Task执行完毕,执行的结果会反馈给TaskSetManager,由TaskSetManager通知DAGScheduler,
* DAGScheduler根据是否还存在待执行的Stage,继续迭代提交对应的TaskSet给TaskScheduler去执行,
* 或者输出Job的结果
*/
execBackend.statusUpdate(taskId, TaskState.FINISHED, serializedResult)
最后交由DAGScheduler.handleTaskCompletion来处理这里的map分区信息。
// 这行代码的作用是将当前任务处理的 Shuffle Map 分区的信息注册到 MapOutputTrackerMaster 中以便后续任务可以知道数据的位置,从而能够更高效地执行后续的 Shuffle 操作。
mapOutputTracker.registerMapOutput(
shuffleStage.shuffleDep.shuffleId, smt.partitionId, status)
shuffle read的详细过程
怎么知道shuffle map端的输出?
在SortShuffleManager.getReader中具有
val blocksByAddress = SparkEnv.get.mapOutputTracker.getMapSizesByExecutorId(
handle.shuffleId, startMapIndex, endMapIndex, startPartition, endPartition)
这里表明了从mapOutputTracker获取输出信息,如果MapOutTrackerWorker.getMapSizesByExecutorId.getStatuses在本地获取到数据,就直接返回,如果获取不到,则问发送GetMapOutputStatuses向**MapOutputTrackerMasterEndpoint(在DAGScheduler)**获取map输出的信息,直至把所有信息获取成功。
这里的参数将作为ShuffleBlockFetcherIterator的入参,之后执行shuffle read的过程将据这里的address读取数据。
怎么执行shuffle read的过程
接下来shuffle reader将开始读取上一个stage的信息,代码如下:
/** Read the combined key-values for this reduce task
* 为该Readuce任务合并key-values值
* */
override def read(): Iterator[Product2[K, C]] = {
// 真正的数据Iterator读取是通过ShuffleBlockFetcherIterator来完成的
//
// 创建ShuffleBlockFetcherIterator的时候,迭代器调用在其initialize()方法
val wrappedStreams = new ShuffleBlockFetcherIterator(
context,
blockManager.blockStoreClient,
blockManager,
blocksByAddress,
serializerManager.wrapStream,
// Note: we use getSizeAsMb when no suffix is provided for backwards compatibility
// 传输中的最大大小,调整这个值即表示提高增大reduce缓冲区,减少拉取次数
SparkEnv.get.conf.get(config.REDUCER_MAX_SIZE_IN_FLIGHT) * 1024 * 1024,
SparkEnv.get.conf.get(config.REDUCER_MAX_REQS_IN_FLIGHT),
SparkEnv.get.conf.get(config.REDUCER_MAX_BLOCKS_IN_FLIGHT_PER_ADDRESS),
SparkEnv.get.conf.get(config.MAX_REMOTE_BLOCK_SIZE_FETCH_TO_MEM),
SparkEnv.get.conf.get(config.SHUFFLE_DETECT_CORRUPT),
SparkEnv.get.conf.get(config.SHUFFLE_DETECT_CORRUPT_MEMORY),
readMetrics,
fetchContinuousBlocksInBatch).toCompletionIterator
val serializerInstance = dep.serializer.newInstance()
// Create a key/value iterator for each stream
// 将shuffle 块反序列化为record迭代器
val recordIter = wrappedStreams.flatMap { case (blockId, wrappedStream) =>
// Note: the asKeyValueIterator below wraps a key/value iterator inside of a
// NextIterator. The NextIterator makes sure that close() is called on the
// underlying InputStream when all records have been read.
serializerInstance.deserializeStream(wrappedStream).asKeyValueIterator
}
// Update the context task metrics for each record read.
val metricIter = CompletionIterator[(Any, Any), Iterator[(Any, Any)]](
recordIter.map { record =>
readMetrics.incRecordsRead(1)
record
},
context.taskMetrics().mergeShuffleReadMetrics())
// An interruptible iterator must be used here in order to support task cancellation
// 为了支持任务取消,这里必须使用可中断迭代器
val interruptibleIter = new InterruptibleIterator[(Any, Any)](context, metricIter)
// aggregatedIter判断在Mapper端进行聚合怎么做;不在Mapper端聚合怎么做。首先判断aggregator是否被定义,
// 如果已经定义aggregator,再判断map端是否需聚合,我们谈的是Reducer端,为什么这里需在Mapper端进行聚合呢?
// 原因很简单:Reducer可能还有下一个Stage,如果还有下一个Stage,那这个Reducer对于下一个Stage而言,
// 其实就是Mapper,是Mapper就须考虑在本地是否进行聚合。迭代是一个DAG图,假设如果有100个Stage,
// 这里是第10个Stage,作为第9个Stage的Reducer端,但是作为第11个Stage是Mapper端,作为Shuffle而言,
// 现在的Reducer端相对于Mapper端。Mapper端需要聚合,则进行combineCombinersByKey。Mapper端也可能不需要聚合,
// 只需要进行Reducer端的操作。如果aggregator.isDefined没定义,则出错提示。
val aggregatedIter: Iterator[Product2[K, C]] = if (dep.aggregator.isDefined) {
// reduce端聚合数据:如果map端已经聚合过了,则对读取到的聚合结果进行聚合。如果map端没有聚合,则针对未合并的<k,v>进行聚合。
if (dep.mapSideCombine) {
// We are reading values that are already combined
/// 如果在map端已经做了聚合的优化操作,则对读取到的聚合结果进行聚合
// 注意此时聚合操作与数据类型和map端未做优化时是不同的
val combinedKeyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, C)]]
// map端个分区针对key进行和并后的结果再次聚合
// map的合并可以大大减少网络传输的数据量
dep.aggregator.get.combineCombinersByKey(combinedKeyValuesIterator, context)
} else {
// We don't know the value type, but also don't care -- the dependency *should*
// have made sure its compatible w/ this aggregator, which will convert the value
// type to the combined type C
// 无需关心值的类型,但确保聚合是兼容的,其将把值的类型转化成聚合以后的C类型
val keyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, Nothing)]]
dep.aggregator.get.combineValuesByKey(keyValuesIterator, context)
}
} else {
interruptibleIter.asInstanceOf[Iterator[Product2[K, C]]]
}
// 在基于Sort的Shuffle 实现过程中,默认基于PartitionId进行排序
// 在分区的内部,数据是没有排序的,因此添加了 keyOrdering变量,提供
// 是否需要针对分区内的数据进行排序的标识信息
//如果定义了排序,则对输出结果进行排序
// Sort the output if there is a sort ordering defined.
val resultIter = dep.keyOrdering match {
case Some(keyOrd: Ordering[K]) =>
// Create an ExternalSorter to sort the data.
// 创建一个外部排序器来对数据进行排序
// 为了减少内存的压力,避免GC 开销,引入了外部排序器对数据进行排序,当内存不足
// 以容纳排序的数据量时,会根据配置的spark.shufflespill属性来决定是否需要
// 溢出到磁盘中,默认情况下会打开spill开关,若不打开spill开关,数据量比
// 较大时会引发内存溢出问题(OutofMemory,OOM)
val sorter =
new ExternalSorter[K, C, C](context, ordering = Some(keyOrd), serializer = dep.serializer)
sorter.insertAll(aggregatedIter)
context.taskMetrics().incMemoryBytesSpilled(sorter.memoryBytesSpilled)
context.taskMetrics().incDiskBytesSpilled(sorter.diskBytesSpilled)
context.taskMetrics().incPeakExecutionMemory(sorter.peakMemoryUsedBytes)
// Use completion callback to stop sorter if task was finished/cancelled.
context.addTaskCompletionListener[Unit](_ => {
sorter.stop()
})
CompletionIterator[Product2[K, C], Iterator[Product2[K, C]]](sorter.iterator, sorter.stop())
case None =>
// 不需要排序分区内部数据时直接返回
aggregatedIter
}
// 如果任务已完成或取消,使用回调停止排序
// 返回结果集迭代器
resultIter match {
case _: InterruptibleIterator[Product2[K, C]] => resultIter
case _ =>
// Use another interruptible iterator here to support task cancellation as aggregator
// or(and) sorter may have consumed previous interruptible iterator.
// 这里使用另一个可终端迭代器来支持任务取消,因为聚合器排序器可能已经使用了以前的可中断迭代器
new InterruptibleIterator[Product2[K, C]](context, resultIter)
}
}
需要关注的是创建wrappedStreams的过程
// 真正的数据Iterator读取是通过ShuffleBlockFetcherIterator来完成的
//
// 创建ShuffleBlockFetcherIterator的时候,迭代器调用在其initialize()方法
val wrappedStreams = new ShuffleBlockFetcherIterator(
context,
blockManager.blockStoreClient,
blockManager,
blocksByAddress,
serializerManager.wrapStream,
// Note: we use getSizeAsMb when no suffix is provided for backwards compatibility
// 传输中的最大大小,调整这个值即表示提高增大reduce缓冲区,减少拉取次数
SparkEnv.get.conf.get(config.REDUCER_MAX_SIZE_IN_FLIGHT) * 1024 * 1024,
SparkEnv.get.conf.get(config.REDUCER_MAX_REQS_IN_FLIGHT),
SparkEnv.get.conf.get(config.REDUCER_MAX_BLOCKS_IN_FLIGHT_PER_ADDRESS),
SparkEnv.get.conf.get(config.MAX_REMOTE_BLOCK_SIZE_FETCH_TO_MEM),
SparkEnv.get.conf.get(config.SHUFFLE_DETECT_CORRUPT),
SparkEnv.get.conf.get(config.SHUFFLE_DETECT_CORRUPT_MEMORY),
readMetrics,
fetchContinuousBlocksInBatch).toCompletionIterator
很明显可以看到还调用了config.REDUCER_MAX_SIZE_IN_FLIGHT等参数进行,这些参数都是在创建spark程序的时候可以调优的。
此外在new ShuffleBlockFetcherIterator的过程中,调用了其**initialize()**方法,执行过程如下:
- 首先区分是本地还是远程 blocks,返回远程请求 FetchRequest 加入到fetchRequests 队列中。
从 fetchRequests 取出远程请求,并使用 sendRequest 方法发送请求,获取远程数据。 - 获取本地 blocks。
- splitLocalRemoteBlocks, 根据executorId区分出在本地的的block和远程的block,然后构建FetchRequest(每一个request可能包含多个block,但是block都是属于一个executor)。
- fetchUpToMaxBytes和fetchLocalBlocks,从本地或者远程datablock,数据放在buffer中,包装好buffer放到其成员results(一个阻塞队列)中。
原文链接:https://blog.csdn.net/zp17834994071/article/details/107887292
然后再执行**wrappedStreams.flatMap **的时候
// Create a key/value iterator for each stream
// 将shuffle 块反序列化为record迭代器
val recordIter = wrappedStreams.flatMap { case (blockId, wrappedStream) =>
// Note: the asKeyValueIterator below wraps a key/value iterator inside of a
// NextIterator. The NextIterator makes sure that close() is called on the
// underlying InputStream when all records have been read.
serializerInstance.deserializeStream(wrappedStream).asKeyValueIterator
}
wrappedStreams通过flatMap遍历的每一个(blockId, wrappedStream),都反序列化对象,然后调用调用asKeyValueIterator转换成NextIterator,其next方法就反序列化后的流中读出(key,value)。
后面将recodIter先后包装成metricIter以及InterruptibleIterator。随后执行这里的程序判断:
val aggregatedIter: Iterator[Product2[K, C]] = if (dep.aggregator.isDefined) {
// reduce端聚合数据:如果map端已经聚合过了,则对读取到的聚合结果进行聚合。如果map端没有聚合,则针对未合并的<k,v>进行聚合。
if (dep.mapSideCombine) {
// We are reading values that are already combined
/// 如果在map端已经做了聚合的优化操作,则对读取到的聚合结果进行聚合
// 注意此时聚合操作与数据类型和map端未做优化时是不同的
val combinedKeyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, C)]]
// map端个分区针对key进行和并后的结果再次聚合
// map的合并可以大大减少网络传输的数据量
dep.aggregator.get.combineCombinersByKey(combinedKeyValuesIterator, context)
} else {
// We don't know the value type, but also don't care -- the dependency *should*
// have made sure its compatible w/ this aggregator, which will convert the value
// type to the combined type C
// 无需关心值的类型,但确保聚合是兼容的,其将把值的类型转化成聚合以后的C类型
val keyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, Nothing)]]
dep.aggregator.get.combineValuesByKey(keyValuesIterator, context)
}
从前面的shuffle write的过程可以知道,即使每个分区任务写出时做了value的聚合,在reduce端的任务中,由于有多个分区的数据,因此依然需要对每个分区的相同的key做value的聚合。这个iterator就可以完成这个功能。
从InterruptibleIterator遍历读取数据,缓存在内存中(map缓存,因为要做聚合),并且在必要时spill到磁盘(spill之前会按key排序)。这个过程和shuffle write中在map端聚合时操作差不多。
然后, 假设上一步产生了多个spill文件,那么每一个spill文件必然时按key排序的,再对这个spill文件做归并,归并时key相同的进行聚合。最后, 迭代器的next返回key以及聚合后的value。
由于这一步是相同key的所有value都按照聚合方法聚合在一起,但是iterator输出是按key的hash值排序输出的,用户可能自定义了自己的排序方法。因此产生了这一步骤:
val resultIter = dep.keyOrdering match {
case Some(keyOrd: Ordering[K]) =>
// Create an ExternalSorter to sort the data.
// 创建一个外部排序器来对数据进行排序
// 为了减少内存的压力,避免GC 开销,引入了外部排序器对数据进行排序,当内存不足
// 以容纳排序的数据量时,会根据配置的spark.shufflespill属性来决定是否需要
// 溢出到磁盘中,默认情况下会打开spill开关,若不打开spill开关,数据量比
// 较大时会引发内存溢出问题(OutofMemory,OOM)
val sorter =
new ExternalSorter[K, C, C](context, ordering = Some(keyOrd), serializer = dep.serializer)
sorter.insertAll(aggregatedIter)
context.taskMetrics().incMemoryBytesSpilled(sorter.memoryBytesSpilled)
context.taskMetrics().incDiskBytesSpilled(sorter.diskBytesSpilled)
context.taskMetrics().incPeakExecutionMemory(sorter.peakMemoryUsedBytes)
// Use completion callback to stop sorter if task was finished/cancelled.
context.addTaskCompletionListener[Unit](_ => {
sorter.stop()
})
CompletionIterator[Product2[K, C], Iterator[Product2[K, C]]](sorter.iterator, sorter.stop())
这里又使用了ExternalSorter,按照自定义排序方式排序(根据前面External介绍,可能又会有spill磁盘的操作),返回的iterator按照用户自定义排序返回聚合后的key。
作为iterator,它的next方法每次从results中取出一个,从数据buffer中使用wrapStream包装InputStream返回。
至此shuffle read完成。
原文链接:https://blog.csdn.net/zp17834994071/article/details/107887292
小结
本篇讲述了SPARK 3.1.3版本执行shuffle中的面筋和源码解析,由于篇幅和理解能力,有些位置讲可能不是很清楚,或者直接从大佬的文章复制出来,还望多多包涵。
未来将持续更新SPARK面筋和源码解析,希望各位观众多多支持,谢谢!!!
- 我的SPARK 3.1.3的源码中文注释也持续同步(大多是直接复制的,挺多错误的,但好在注释字数够多,能够辅助你一定的理解),如果对源码注释有需要的观众朋友,可以直接从这里获取~~~如果有帮助的话点个赞,谢谢!!!















 2159
2159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









