







论文链接:https://arxiv.org/abs/2304.01184
代码链接:https://github.com/hustvl/weaktr
这篇文章有两部分内容,一部分是CAM Generation,另一部分是Segmentation。但由于Segmentation部分也是基于Transformer,那部分就暂时忽略了。
方法
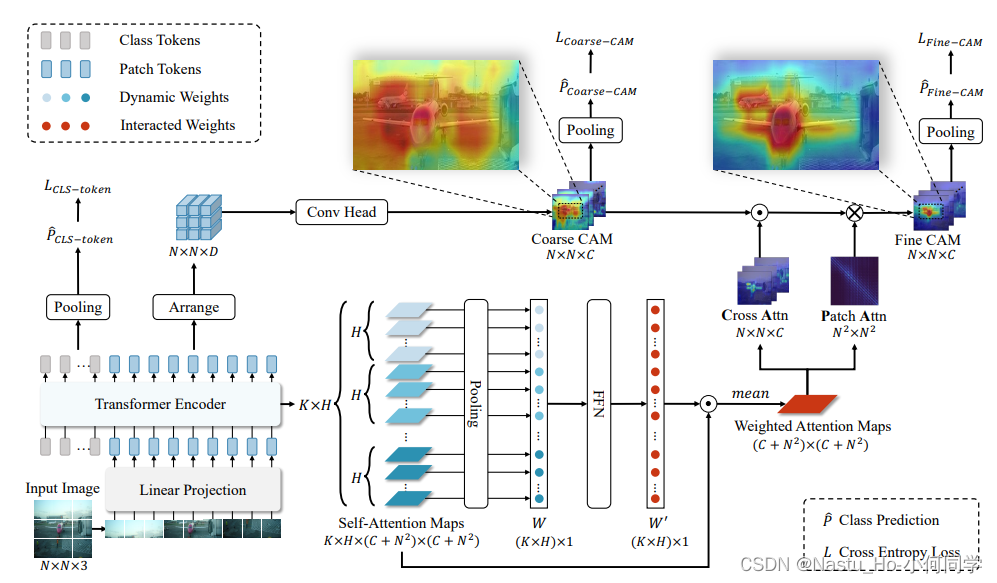
CAM Generation部分整体大框架还是MCTFormer。关于MCTFormer,可以看我之前的文章,这里就只说不一样的地方。
motivation:不同的head会关注不同不用区域、类别,过去的方法直接对attn weights的head求mean来融合不同head的attn map,难免存在一些冗余信息。
solution:得到一组自适应权重,不同的head给予不同的关注程度,来降低冗余
- 对于K层transformer layer, 可以得到K层的attn weights(K, h N+C, N+C)—暂时忽略batch维。(C是类别数)
- 经过GAP,得到一组权重W(K, h, 1)
- 经过全连接层学习得到 W’(K, h, 1)。这样,对于每一层的每一个head,都得到一个可学习的、自适应的权重。
- 将这组权重乘回原来的attn weights, 对K, h 求mean后得到Weighted attn weights(N+C, N + C),然后分离出attn maps(C, N) 和 patch affinity(N, N)
- 在线耦合+refine— 将attn map与patchCAM点乘耦合,再将patch affinity通过矩阵乘法对耦合后的CAM进行refine。refine后的CAM也拿去做分类。
实验
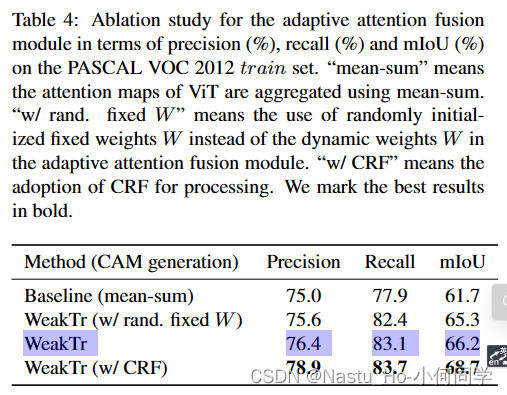
消融
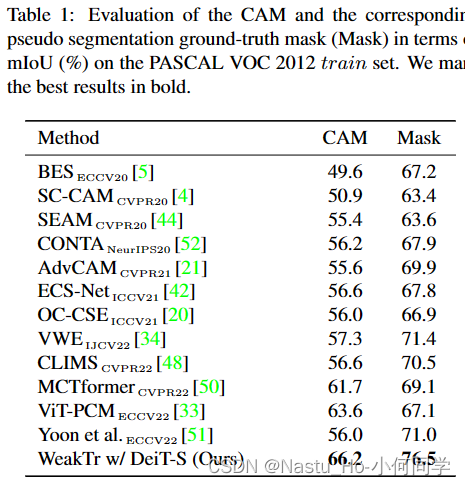
CAM的质量评估














 403
403











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









