







1. 论文信息
Federated Learning with Buffered Asynchronous Aggregation,International Conference on Artificial Intelligence and Statistics,2022,ccfc
2. introduction
2.1.1. 背景:
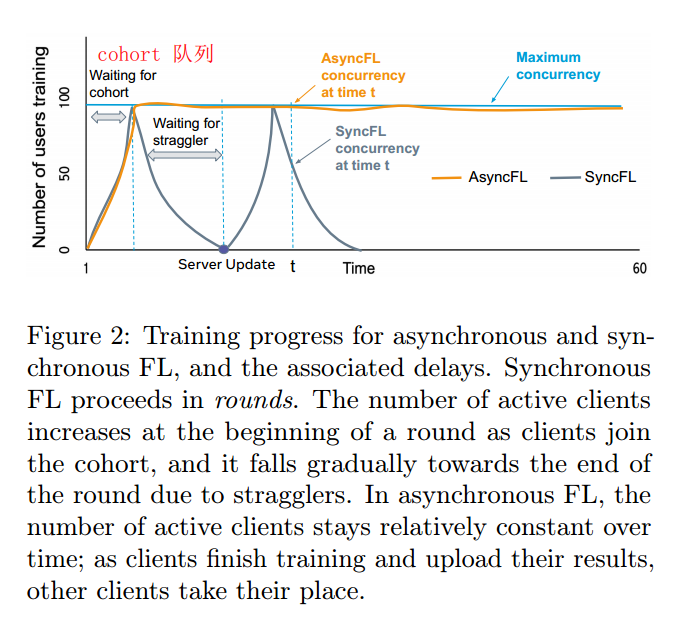
同步 FL ,随训练过程中的客户端数量的增多,模型性能 和 训练速度 的收益 会下降,类似于大批量训练;异步 FL 缓解了 Scalability (可扩展性),但是异步 FL 来一个聚合一个,与安全聚合不兼容,会导致 Privacy 问题。
2.1.2. 挑战:Scalability、Privacy
2.1.3. 解决的问题:
- Scalability:加缓冲机制优化异步聚合,具体:服务器在执行服务器更新之前将K个客户端更新聚合到安全缓冲区中
- Privacy:SecAgg 使得诚实但好奇的服务器无法看到单个客户机的更新;在服务器上执行DP裁剪和噪声添加,保护客户机的数据免受基于计算的输入和输出的观察,从而提供更好的隐私-效用权衡。
2.1.4. 贡献点:
- 提出一种新的异步联邦优化框架FedBuff,具有 缓冲 异步聚合,通过 安全聚合 和 差分隐私 实现对诚实但好奇的威胁模型的 可扩展性 和 隐私性
- 给出了FedBuff在光滑非凸环境下的收敛性分析。当客户端采取Q个本地SGD步骤时,FedBuff需要的服务器迭代,以达到的准确度
- 实验验证 即使没有惩罚掉队者,FedBuff 也比同步FL算法效率高3.8。FedBuff 比文献中最接近的异步FL算法 FedAsync (Xie et al, 2019) 效率高2.5倍。K = 10是跨基准测试的良好设置,不需要调优
- 第一个提出与 SecAgg 和全局用户级 DP 兼容的异步联邦优化框架
3. Background
3.1.1. 同步FL
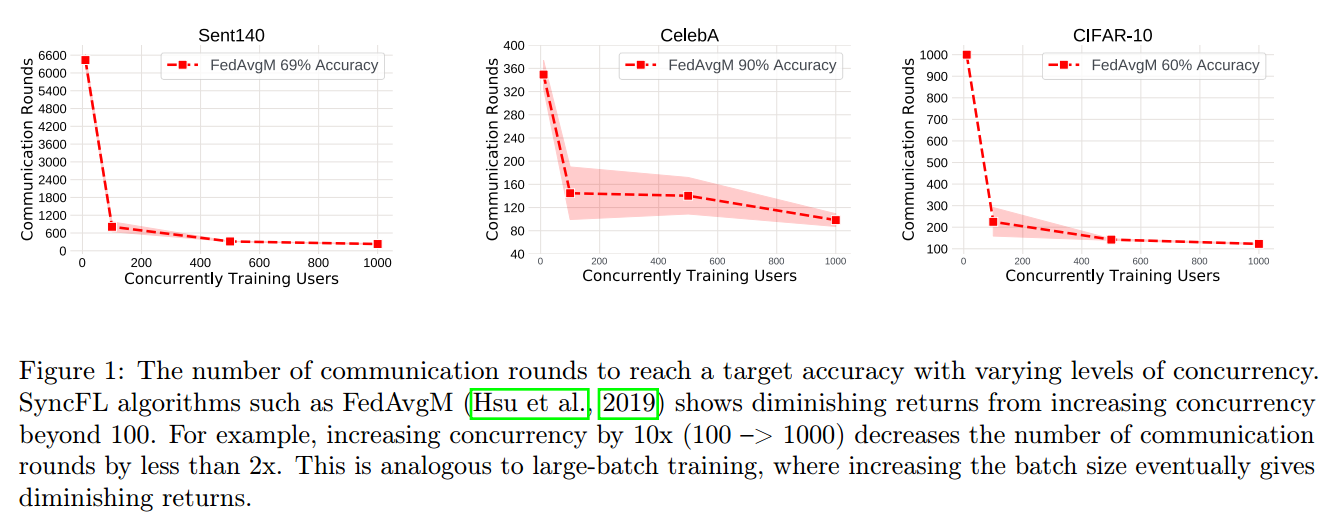
如图:当并发训练的用户数超过 100 时收益递减。例如,将并发性增加10倍(100 - > 1000)将使通信轮数减少不到2倍。类似于大批训练,增加批大小最终会带来递减的回报
最优的服务器学习率随着并发性的增加而增加,高并发性意味着对更多用户进行聚合,这样能够减少方差,使服务器“迈出”更大的步,减少达到目标精度所需的轮数。然而,为了获得稳定、收敛的训练结果,服务器学习率不能无限增加,并发聚合的用户数也不能无限增加;最终会饱和。
3.1.2. 异步FL
每次客户端更新完成都强制服务器更新,这样的聚合方式不满足安全聚合的条件,此外,在AsyncFL中提供用户级DP仅适用于本地差分隐私(LDP),其中客户端剪辑模型更新并在将其发送到 Server 之前在本地添加噪声
3.1.3. SecAgg :将单个客户端 i 的更新放在一组客户端更新的集合中,通过混淆客户端 i 和其他客户端的更新增强隐私
3.1.4. DP:先求偏导,对偏导进行裁剪得到相邻数据集,再添加噪声

DP的实现依赖于 服务器使用 SecAgg
4. 问题描述:System model/架构/对问题的形式化描述
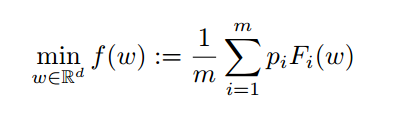
找到一个在(加权)平均值上很好地拟合所有客户数据的模型
5. 解决方法
5.1. 执行流程:


5.2. 挑战问题怎么解决:
添加缓冲机制提高可扩展性,在缓冲机制的前提下,用差分隐私实现安全聚合,提高隐私
5.3. 性能保证(performance guarantee):理论分析,使用什么理论,怎么分析/解决
暂时先跳过
5.4. Practical Improvements
5.4.1. Staleness scaling.
![]()
控制过时度 Ti(t) 对 客户端 i 更新服务器 t 的贡献影响
5.4.2. Learning rate normalization
同步与异步 FL ,两种方式对客户端来讲 round 的定义不同,但服务器规定的批处理大小 B 对所有客户端都相同。
![]()
其中
![]()
是用于该步骤的实际批处理大小
6. 效果:重点是实验设计,每一部分实验在验证论文中的什么结论
6.1. 实验设置
6.1.1. 数据集、模型、任务
Sent140是文本分类数据集(二元情感分析)
CelebA和CIFAR-10是图像分类数据集(多类分类)
- 对于Sent140,在660,120个客户端上训练LSTM分类器,其中每个Twitter帐户对应一个客户端。
- 对于CelebA,在9,343个客户端上训练与LEAF相同的卷积神经网络分类器,按照(Hsieh et al .(2020))的建议,将批处理归一化层替换为组归一化层(Wu and He(2018))
- 对于CIFAR-10,使用参数为0.1的Dirichlet分布生成5000个非id客户端,方法与(Hsu等)中相同
对比实验
6.1.2. 实验设置
用三种不同的种子重复每个实验,并取平均值。对于异步FL,假设客户端以恒定的速率到达,从半正态分布中采样延迟分布,即客户端下载和上传操作之间的时间延迟。选择这个分布是因为它最符合在生产FL系统中观察到的延迟分布
6.2. 对比实验(实验部分暂时没有深入去看,想的是用到的话再回来仔细看)

频繁更新服务器模型的好处超过了客户端模型更新过时的成本

超参数确定实验


7. (备选)自己的思考
论文对你的启发,包括但不限于解决某个问题的技术、该论文方法的优缺点、实验设计、源码积累等。
背景:
挑战:
问题:
相关工作:
算法:
实验

















 9345
9345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











