






目录
Class-specific multi-class token attention
Class-specific attention refinement
本文记录弱监督语义分割领域论文笔记《Multi-class Token Transformer for Weakly Supervised Semantic Segmentation》
官方pytorch代码 https://github.com/xulianuwa/MCTformer
伪标签使用Vision Transformer分类架构来生成,使用image-level的标注信息
理解本文需要了解传统卷积网络生成CAM的过程,并且要懂ViT的自注意力模块
作者把他们的模型分为了 V1 和 更丰富的V2两个版本
MCTformer-V1
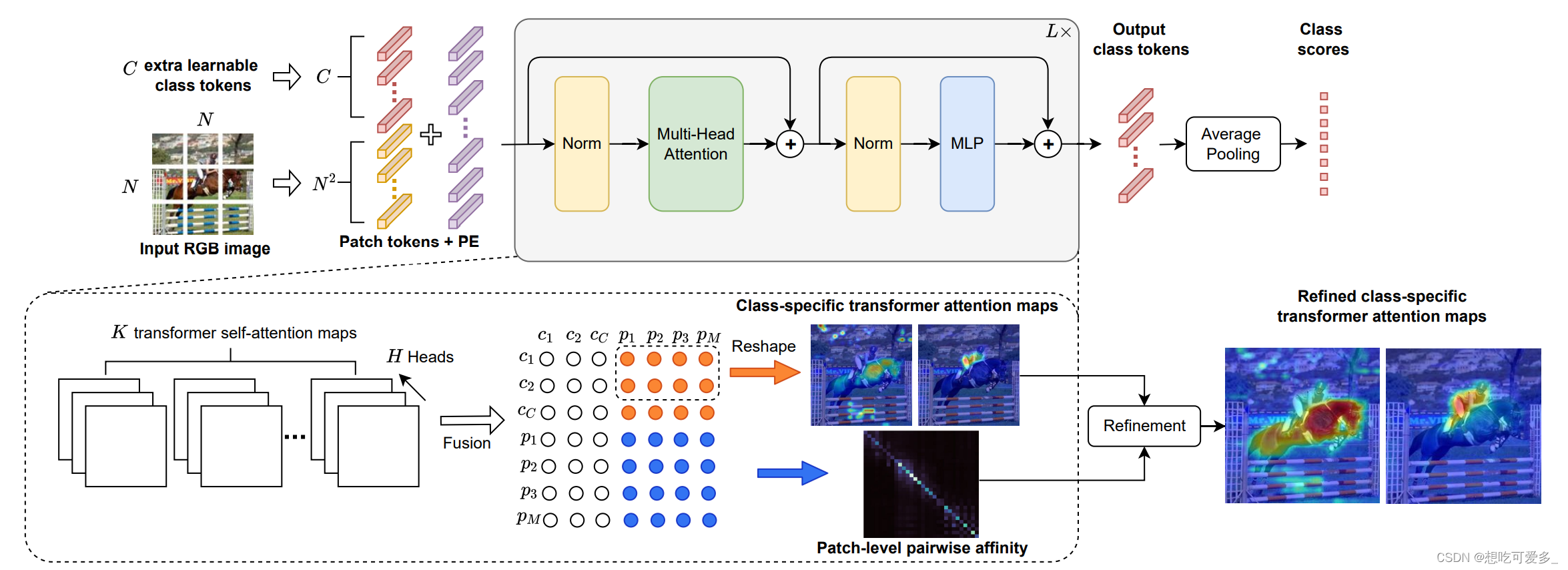
上面就是整体的网络结构图
首先按照ViT的做法,把图片切成N*N个patch,每个patch拉成一个向量,embedding之后每个patch向量维度为D,本文把这些patch向量称为patch tokens,共有N*N个patch tokens
传统的ViT会在这些patch tokens前加上一个class token,维度也是D,因为最后要像图中那样和patch tokens拼接,最后把他提取出来做分类器。本文创新的加上C个class tokens,C是多分类的类别数,作者管这个操作叫multi-class token -> MCTformer
现在我们的输入就是(C+N*N)*D,共有C+N*N个token,维度为D,D代表了每个token的特征数量
PE代表融入了位置编码信息
之后把我们这些tokens送到ViT的encoder中,连续执行L次
Class-specific multi-class token attention
下面看他是怎么从自注意力中提取了目标的位置信息,作者展示在了上图虚线框内
ViT采用的是多头注意力,因为最后多头会融合回单头,输出维度不变,所以我们这里直接忽略多头这个操作
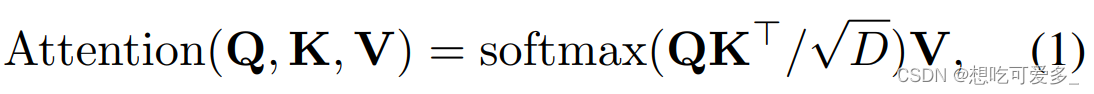
上面是自注意力的公式,但是本文我们获取的注意力不乘V这个矩阵
![]()
有什么区别呢,的输出形状是(C+N+N)*(C+N+N)方阵,对应图中由小圆圈组成的方阵。它的含义是token之间的关联性,值越大,两个token之间的相关性越大,相关性越大给予的注意力就越同步
如果乘上V矩阵,则相当于把输入的特征经过注意力加权后再输出,我们需要的只是第一个步骤
为什么使用C个class token?
传统的ViT使用一个class token线性变换后输出多分类器,也就是一个class token负责多个类别的分类,这样就会导致多个类别的特征被搅和到了一起,让我们无法很好的一个类一个类的去激活他们的位置。
而使用C个class token,每一个class token只负责一个类别的激活,分离类别之间的特征
看图中那些橙色的小圆圈,它代表了class token和patch token的关联性,class token代表某个类别,patch token代表某个位置,这不正好体现了某个类别很有可能在哪个位置吗。 一行小圆圈是一个类别,我们把一个类别对应的N*N个patch按照原来在图片中的位置排列,该类的激活图呼之欲出,对应橙色箭头
由于ViT会经过多个encoder,每个encoder都能做一次这种操作,靠前的encoder提取的特征更具一般性,,靠后的encoder更能提取高阶的特征。所以作者会把后几层的激活图融合,直接相加求平均就好了。
Class-specific attention refinement
那些蓝色小圆圈有什么用呢?
蓝色小圆圈代表了patch token之间的关联,是一个N*N*N*N方阵,称它为affinity map。看蓝色箭头指的图片,对角线附近值最大,因为一个位置和它自己或是周围的相关性肯定是最大的。
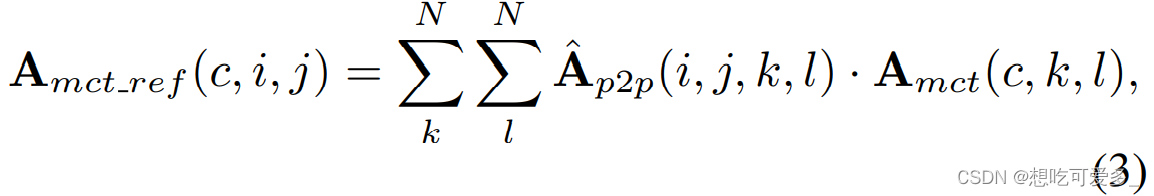
假设p1位置对应的token和p2位置对应的token关联性很大,那么,如果p1位置很强的激活了某类,那么p2位置也要给予很强的激活。上面的公式说明,作者通过遍历patch token对来完成这个操作,(i, j)和(k, l)是patch的位置,c是第c类,Amct是上一步得到的激活图
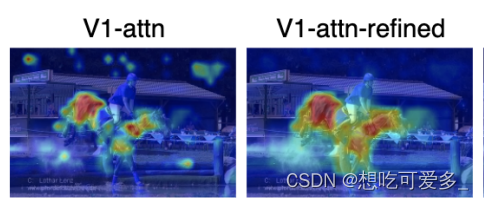
这一步作者管他叫Class-specific attention refinement,是一种对激活图进一步细化的操作。结合上图示例,这个操作是丰富了激活图的细节,激活了更多的区域
Class-aware training
训练方式如网络右上角,每个class token代表了某一类别,对token池化后直接和标注求损失即可,然后反向传播。因为是多标签任务,并且encoder也有Norm操作,不需要在进行BN什么的,直接池化就好了。作者讲,这种一个类一个token训练起来激活能力更强
MCTformer-V2
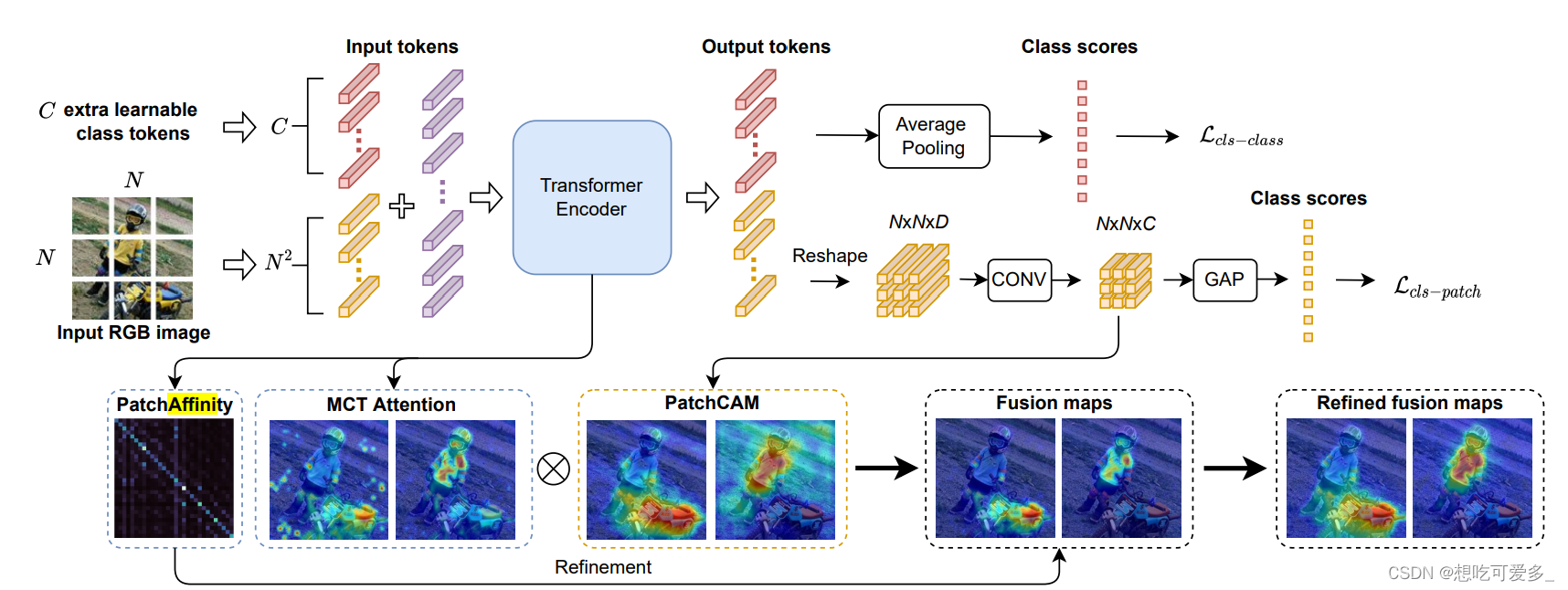
观察这个结构,主干还是V1那样,但是把encoder输出中patch token那一部分拿出来再做一次传统的卷积网络,细节如下
1、像传统的卷积网络那样最后产生分类器,和标注文件产生损失,把这个损失和V1中的那个损失求和,一起反向传播
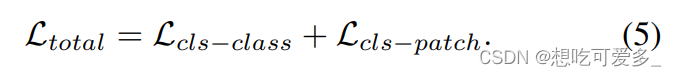
2、为什么要在过一次卷积网络呢,估计是作者舍不得放弃利用传统的卷积网络生成CAM激活图。看图中的最下方,作者把卷积网络生成的CAM和V1中生成的激活图做element-wise的乘积,融合两者激活区域
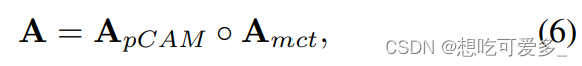
3、作者把利用affinity map细化激活图的步骤,放到了融合过两种激活图之后

















 691
691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









