







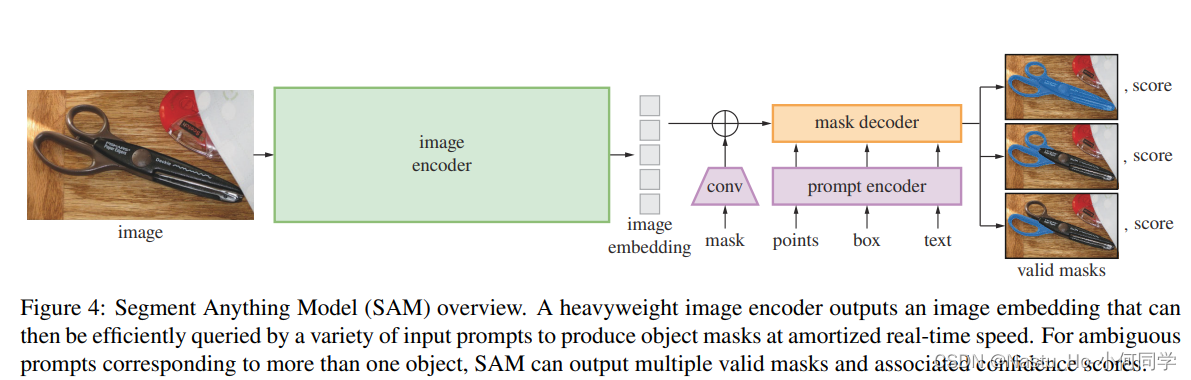
prompt具体如何起作用
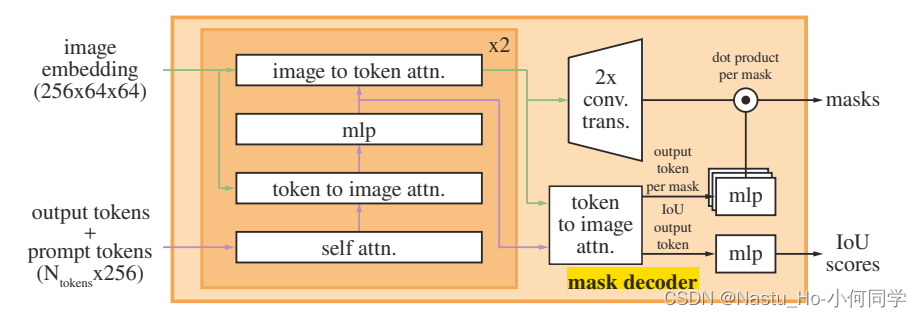
class TwoWayAttentionBlock(nn.Module):
def __init__(
self,
embedding_dim: int,
num_heads: int,
mlp_dim: int = 2048,
activation: Type[nn.Module] = nn.ReLU,
attention_downsample_rate: int = 2,
skip_first_layer_pe: bool = False,
) -> None:
"""
A transformer block with four layers: (1) self-attention of sparse
inputs, (2) cross attention of sparse inputs to dense inputs, (3) mlp
block on sparse inputs, and (4) cross attention of dense inputs to sparse
inputs.
Arguments:
embedding_dim (int): the channel dimension of the embeddings
num_heads (int): the number of heads in the attention layers
mlp_dim (int): the hidden dimension of the mlp block
activation (nn.Module): the activation of the mlp block
skip_first_layer_pe (bool): skip the PE on the first layer
"""
super().__init__()
self.self_attn = Attention(embedding_dim, num_heads)
self.norm1 = nn.LayerNorm(embedding_dim)
self.cross_attn_token_to_image = Attention(
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
)
self.norm2 = nn.LayerNorm(embedding_dim)
self.mlp = MLPBlock(embedding_dim, mlp_dim, activation)
self.norm3 = nn.LayerNorm(embedding_dim)
self.norm4 = nn.LayerNorm(embedding_dim)
self.cross_attn_image_to_token = Attention(
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
)
self.skip_first_layer_pe = skip_first_layer_pe
def forward(
self, queries: Tensor, keys: Tensor, query_pe: Tensor, key_pe: Tensor
) -> Tuple[Tensor, Tensor]:
# Self attention block
if self.skip_first_layer_pe:
queries = self.self_attn(q=queries, k=queries, v=queries)
else:
q = queries + query_pe
attn_out = self.self_attn(q=q, k=q, v=queries)
queries = queries + attn_out
queries = self.norm1(queries)
# Cross attention block, tokens attending to image embedding
q = queries + query_pe
k = keys + key_pe
attn_out = self.cross_attn_token_to_image(q=q, k=k, v=keys)
queries = queries + attn_out
queries = self.norm2(queries)
# MLP block
mlp_out = self.mlp(queries)
queries = queries + mlp_out
queries = self.norm3(queries)
# Cross attention block, image embedding attending to tokens
q = queries + query_pe
k = keys + key_pe
attn_out = self.cross_attn_image_to_token(q=k, k=q, v=queries)
keys = keys + attn_out
keys = self.norm4(keys)
return queries, keys
4 steps:
(1) self-attention on the tokens (prompt tokens)
(2) cross-attention from tokens (as queries) to the image embedding
(3) a point-wise MLP updates each token (prompt token)
(4) cross-attention from the image embedding (as queries) to tokens (prompt tokens)
This last step updates the image embedding with prompt information
To ensure the decoder has access to critical geometric information,the positional encodings are added to the image embedding whenever they participate in an attention layer.
Additionally, the entire original prompt tokens (including their positional encodings) are re-added to the updated tokens whenever they participate in an attention layer. This allows for a strong dependence on both the prompt token’s geometric location and type














 1394
1394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









