






之前学习了一些BP神经网络的基础,今天突然有了点时间,想起来自己很久就想看看LSTM的相关东西,所以今天就集中搞了一下,算是入门吧。
这里主要是一个自己的理解汇总,主要内容从下面文章中摘录:
https://blog.csdn.net/zhaojc1995/article/details/80572098
RNN,循环神经网络
RNN同样包含神经网络共有的输入层、隐藏层和输出层,通过激活函数控制输出,层与层之间通过权值连接。
RNN和基础神经网络不同之处在于“隐藏层里面的神经元之间也需要建立权连接”
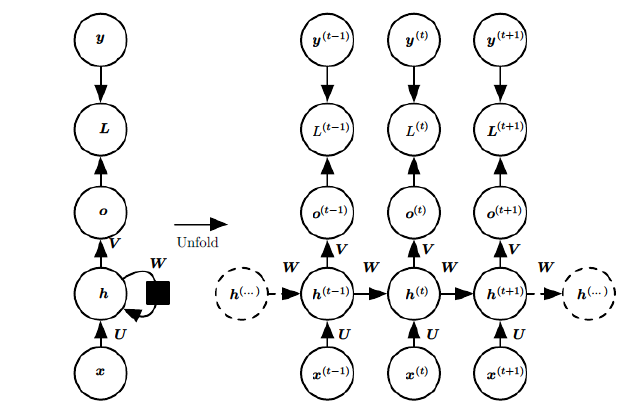
箭头连接带有权值。左侧是折叠起来的样子,右侧是展开的样子,左侧中h旁边的箭头代表此结构中的“循环“体现在隐层。
在展开结构中我们可以观察到,在标准的RNN结构中,隐层的神经元之间也是带有权值的。也就是说,随着序列的不断推进,前面的隐层将会影响后面的隐层。图中O代表输出,y代表样本给出的确定值,L代表损失函数,我们可以看到,“损失“也是随着序列的推荐而不断积累的。
除上述特点之外,标准RNN的还有以下特点:
1、权值共享,图中的W全是相同的,U和V也一样。
2、每一个输入值都只与它本身的那条路线建立权连接,不会和别的神经元连接。(没有交叉相乘)
第二个特点带来一个问题:如果我们不希望输入等于输出呢?这里就用到了Encoder-Decoder模型,也叫做Seq2Seq模型。如下图所示。
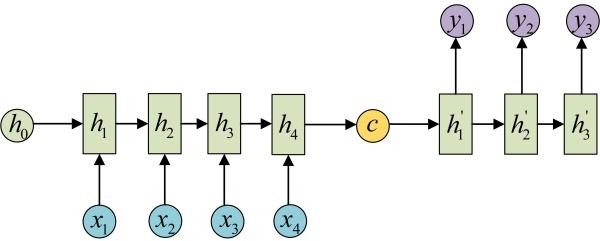
左侧的RNN用来编码得到c,拿到c后再用右侧的RNN进行解码。得到c有多种方式,最简单的方法就是把Encoder的最后一个隐状态赋值给c,还可以对最后的隐状态做一个变换得到c,也可以对所有的隐状态做变换。
RNN的前向传播过程
这里用到了第一个图。可以得到下面的几个求解过程:
(1)h(t)=ϕ(Ux(t)+Wh(t−1)+b) ϕ()为激活函数,一般来说会选择tanh函数,b为偏置。
(2)输出:o(t)=Vh(t)+c
(3)预测输出:yˆ(t)=σ(o(t)) σ()为激活函数,通常RNN用于分类,故这里一般用softmax函数。
RNN的训练方法BPTT
BPTT,back-propagation through time,实际上它就是BP算法,思想都是沿着需要优化的参数的负梯度方向不断寻找更优的点直至收敛,只不过它需要基于时间反向传播。
寻优的参数有三个,分别是U、V、W。其中W、U需要追溯之前的历史数据,但V只关注目前。
求V的偏导数:
RNN的损失会随着时间累加,所以不能只求t时刻的偏导:

W和U相同,都需要考虑历史数据,现在我们假设有三个时刻,那么在第三个时刻L对W的偏导数:

同理,得到L对U的偏导数:

可以观察到,在某个时刻的对W或是U的偏导数,需要追溯这个时刻之前所有时刻的信息,这还仅仅是一个时刻的偏导数,上面说过损失也是会累加的,那么整个损失函数对W和U的偏导数将会非常繁琐。虽然如此但好在规律还是有迹可循,我们根据上面两个式子可以写出L在t时刻对W和U偏导数的通式:

实际上,这些公式中都嵌套着激活函数,如果我们替换激活函数,中间累乘的部分:

或

可以看出,当激活函数不同的时候,偏导数也就不一样,求梯度的时候也不会不同。通过对上面两个不同激活函数的分析发现,这里容易出现两个问题,分别是“梯度消失”和“梯度爆炸”。"梯度消失"是指梯度越来越小到接近0。“梯度爆炸”是指恒为1的导数容易导致,可以通过设定合适的阈值解决。
正如下图所示,sigmoid函数的导数区间为(0,0.25):

而tanh函数的导数区间为(0,1):

随着累乘的进行,sigmoid作为激活韩式的时候,梯度就是一堆小数的累成,很快就会趋紧0。虽然tanh函数也是小数,但它毕竟比sigmoid大,这种趋势会减缓很多。(得出两个结论,1.深层的神经网络往往不用sigmoid函数做激活函数 2.深层神经网络中,有时候多加神经元数量可能会比多加深度好)
除此之外,sigmoid函数还有一个缺点,它不是零中心对称。sigmoid的输出均大于0,这就使得输出不是0均值,称为偏移现象,这将导致后一层的神经元将上一层输出的非0均值的信号作为输入。关于原点对称的输入和中心对称的输出,网络会收敛地更好。
总结一下,sigmoid函数的缺点:
1、导数值范围为(0,0.25],反向传播时会导致“梯度消失“。tanh函数导数值范围更大,相对好一点。
2、sigmoid函数不是0中心对称,tanh函数是,可以使网络收敛的更好。
RNN本来就是为了利用历史数据,结果因为“梯度消失”导致可用的历史数据很少(假设我们试着去预测“I grew up in France… I speak fluent French”最后的词。当前的信息建议下一个词可能是一种语言的名字,但是如果我们需要弄清楚是什么语言,我们是需要先前提到的离当前位置很远的 France 的上下文的。这说明相关信息和当前预测位置之间的间隔就肯定变得相当的大,当这个间隔变大的时候,RNN会丧失学习到信息的能力)。所以RNN的解决“梯度消失“是非常必要的。解决“梯度消失“的方法主要有:
1、选取更好的激活函数
2、改变传播结构
LSTM可以有效地解决第二个问题。
LSTM,长短期记忆
LSTM 由Hochreiter & Schmidhuber (1997)提出,并在近期被Alex Graves进行了改良和推广。所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh 层。

LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于 单一神经网络层,整体上除了h在随时间流动,细胞状态c也在随时间流动,细胞状态c就代表着长期记忆。


- 黄色的矩形是学习得到的神经网络层
- 粉色的圆形表示一些运算操作,诸如加法乘法
- 黑色的单箭头表示向量的传输
- 两个箭头合成一个表示向量的连接
- 一个箭头分开表示向量的复制
LSTM的核心思想
LSTM中有“细胞状态”的概念,在神经元的上方贯穿进行,只有少量的线性交互。

LSTM还有一个“门”的概念,它用来去除或增加信息到细胞状态的能力。门是一种让信息选择式通过的方法,包含一个sigmoid神经网络层和一个pointwise乘法操作。一共有三种门:遗忘门、输入门、输出门。

Sigmoid 层输出 0 到 1 之间的数值,描述每个部分有多少量可以通过。0 代表“不许任何量通过”,1 就指“允许任意量通过”!
LSTM的工作流程
sigmoid函数选择更新内容,tanh函数创建更新候选。
“遗忘门”:语言模型的例子中,来基于已经看到内容来预测下一个词。在这个问题中,细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语。其精髓在于只能输出(0,1)小数的sigmoid函数和粉色圆圈的乘法,LSTM网络经过学习决定让网络记住以前百分之多少的内容。决定记住什么遗忘什么,其中新的输入肯定要产生影响。

“输入门”:下一步是确定什么样的新信息被存放在细胞状态中。这里包含两个部分。第一,sigmoid 层称 “输入门层” 决定什么值我们将要更新。然后,一个 tanh 层创建一个新的候选值向量,C~tC~t,会被加入到状态中。下一步,我们会讲这两个信息来产生对状态的更新。
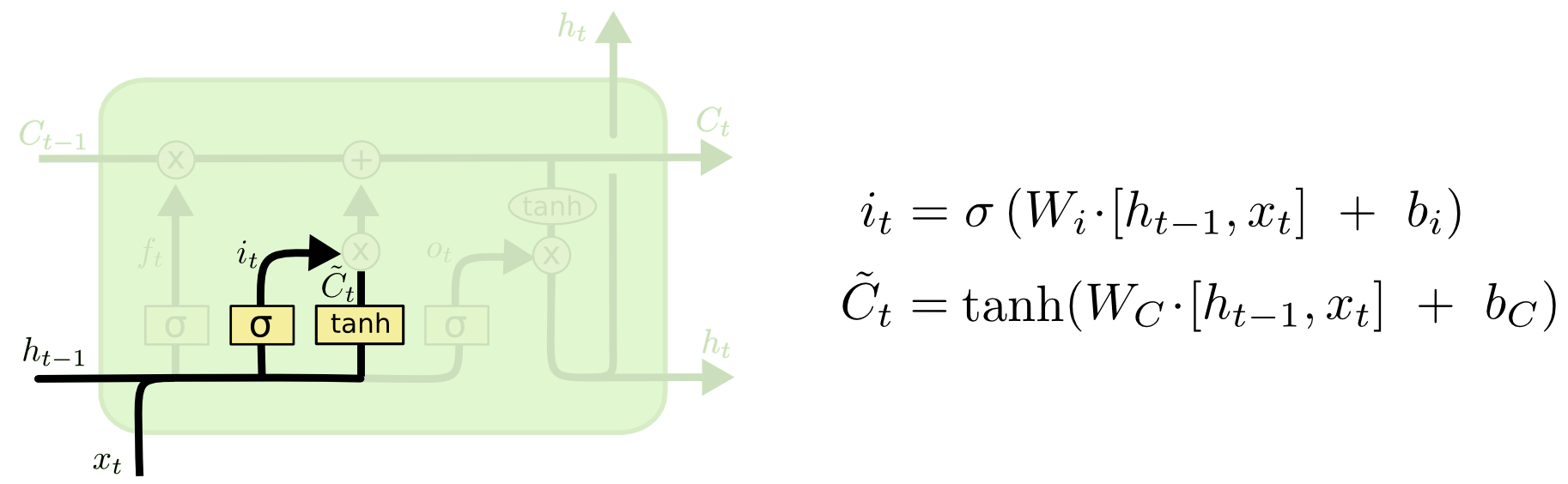
更新“细胞状态”:把旧状态与ft相乘,丢弃掉我们确定需要丢弃的信息。接着加上it∗C~ti。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。
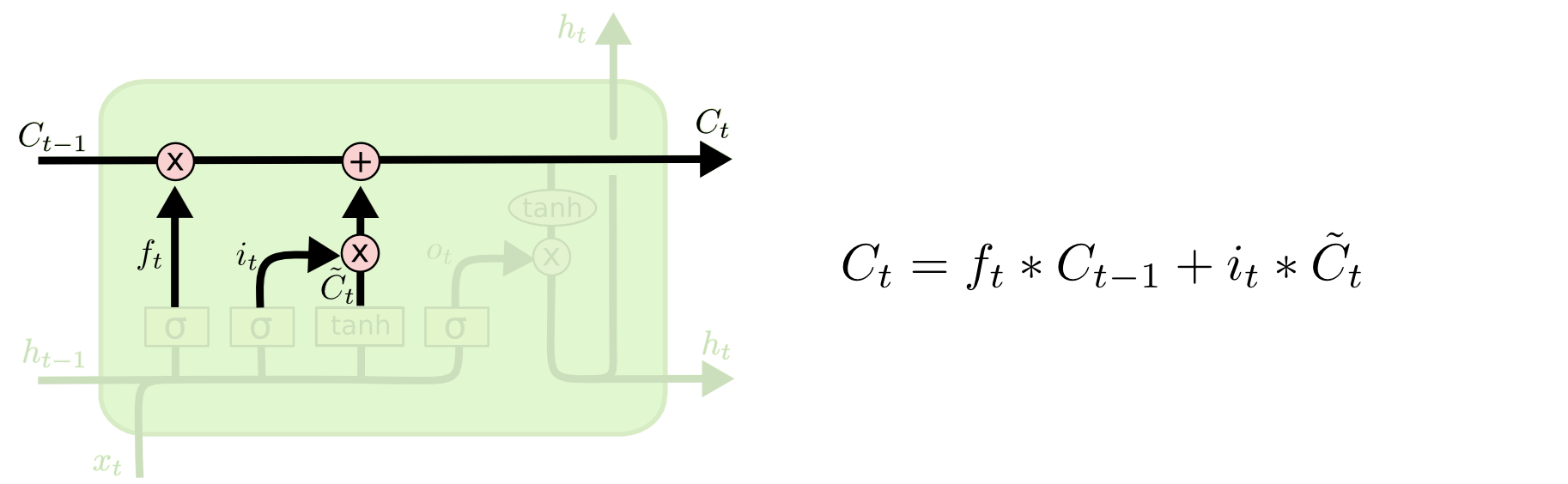
“输出门”: 最终,我们需要确定输出什么值。这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。首先,我们运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去。接着,我们把细胞状态通过 tanh 进行处理(得到一个在 -1 到 1 之间的值)并将它和 sigmoid 门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。
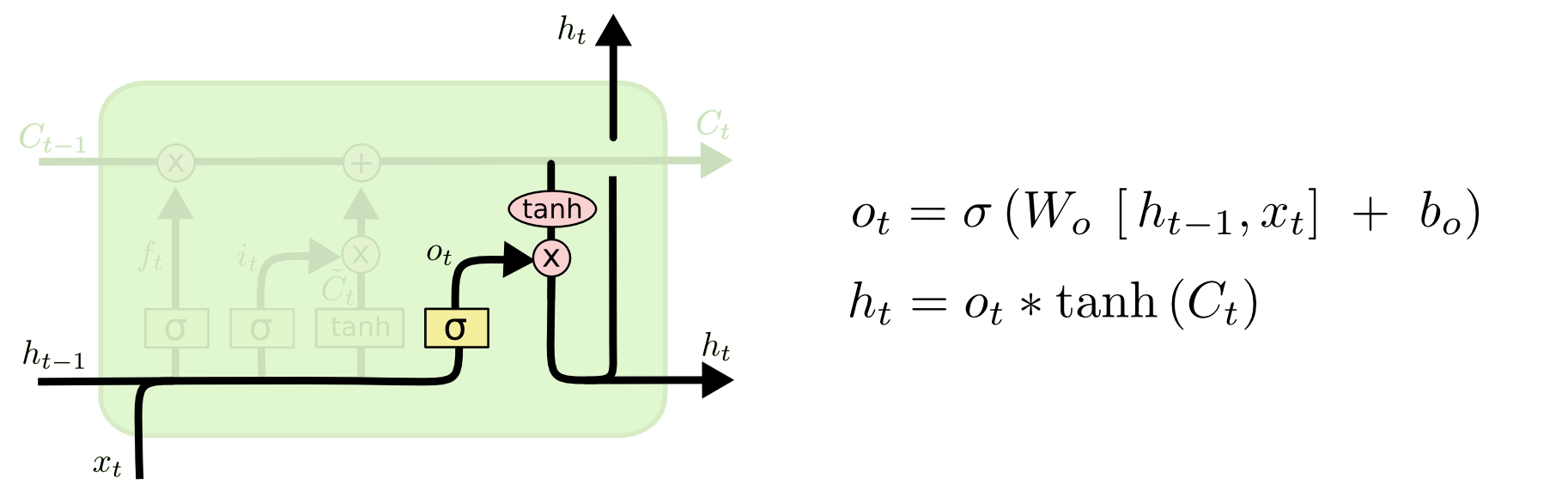
这三个门虽然功能上不同,但在执行任务的操作上是相同的。他们都是使用sigmoid函数作为选择工具,tanh函数作为变换工具,这两个函数结合起来实现三个门的功能。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









