






自适应线性神经网络(Adaline)和感知器的区别:
1.自适应线性神经网络的激活函数不再采用步调函数,而是直接将样本运算的结果(点乘)与实际结果相比较。(白话版:自适应线性神经网络的激活函数,是一个线性函数)
2.自适应线性神经网络提出了代价函数的概念,并对其做了最小优化。基于Adaline规则的权重更新是通过一个连续的线性激活函数(本例子中采用)来完成,而感知器采用的单位阶跃函数。
相关概念:
距离:和方差公式(欧几里得距离): ,
,其中y表示输入的第i组数据对应的结果。不断训练,当这个距离J最小的时候,训练结束。(注意:这是所有输出误差的和,因为本次距离只采用一个神经元,所以只有一个输出,没有用到求和公式)
渐进下降法:和方差的函数实际上是一条曲线,对J(w)求导数,当大于0的时候,减小W,当小于0的时,增加W,这个方法叫渐进下降法。
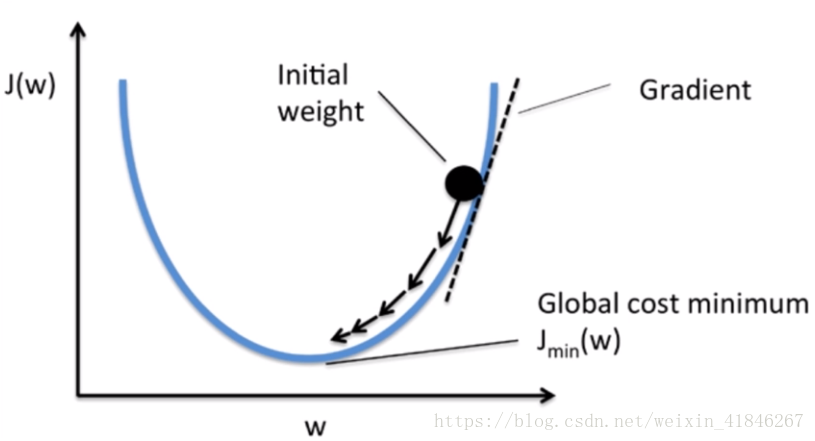
步骤:
(有监督学习的核心:定义一个待优化的目标函数,即做最小化处理的代价函数。)
1.Adaline将和方差公式作为代价函数
2.通过梯度下降算法,沿梯度做权重更新。权重增量定义为负梯度和学习速率
的乘积。
(求偏导的过程,可以理解为权重w对误差结果的影响程度,也就是斜率,斜率越大,影响越大。更新过程就是权重W减去学习速率*总误差关于权重W的斜率。同理,偏置b的更新实际上就是偏置b减去学习速率*总误差关于偏置b的斜率)
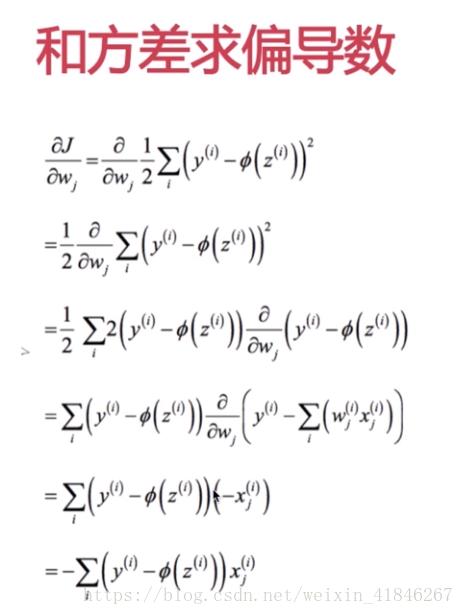
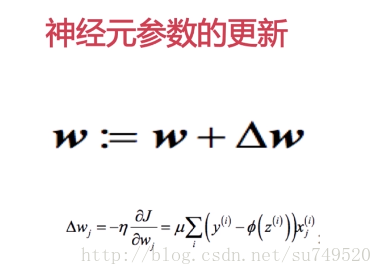
自适应性神经元和感知器的最大区别在于激活函数的不同。















 4518
4518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









