








在预测的时候,用到XGBoost来对输入的特征进行重要性的排序和筛选。看网上的教程直接用plot_imporance打印出来,这个函数自动将特征按重要性排序并输出得分,但特征较多就会挤在一起看不清,而且我需要在接下来的操作里用到这些特征名称,不能一个一个手打出来。网上没有找到合适的教程,于是记录一下我的思路。
进入plot_importance函数,
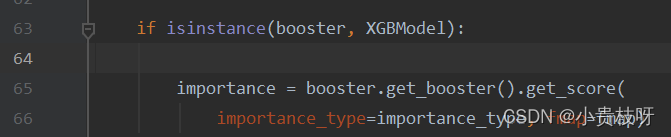
可以看到特征以及得分都在importance里面了, 再往下看
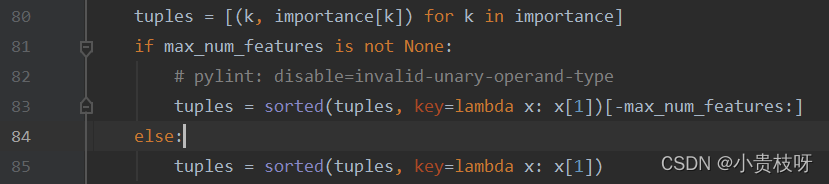
把特征及得分放到元组列表里,对元组进行排序。
受上面的代码启发,我提取特征名称代码如下:
import xgboost as xgb
model = xgb.XGBRegressor() model.fit(X_train, y_train)#训练模型 importance = model.get_booster().get_score() tuples = [(k, importance[k]) for k in importance] tuples = sorted(tuples, key=lambda x: x[1],reverse=True) feature_names,scores = map(list,zip(*tuples))#zip(*)是对元组解压缩 print(feature_names)

















 1035
1035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









