







西瓜书学习笔记
chapter 2 模型评估与选择
2.1 经验误差与过拟合
分类错误的样本数占总样本的比例称为“错误率”(error rate)
精度=1-错误率
学习器的实际预测输出与样本的真实输出之间的差异称为“误差”,在训练集上称为训练误差,测试集上称为泛化误差。
过拟合的原因:学习能力太过强大,学习到了训练集中的不太一般的特性。
欠拟合则是学习能力不够,可以通过在决策树学习中扩展分支,在神经网络中增加训练轮数。
对候选模型进行泛化评估(在测试集上测试性能,作为泛化误差的近似,注意这两者不画等号),选择泛化性能最好的那个模型。
测试样本要尽可能与训练集互斥,以获得更准确的泛化效果评估。
对样本D进行适当处理,从中产生训练集S和测试集T。
划分方法有:1,留出法:也就是1000个样本按一定比例划分。单次使用留出法得到的估计结果往往不够可靠,一般采用若干次随机划分,重复进行试验评估后取平均值作为留出法的评估结果。
2,交叉验证法:先将样本划分为k个大小相似的互斥子集,并保持数据分布的一致性,将k-1个子集用作训练集,剩下的一个用作测试集。
这样可以得到k组训练/测试集。进行k次交叉验证,返回的是k次的均值。
k 的通常取值为10。
同留出法一样,将D划分为k组也有多种方式,所以应进行p次试验,减小因样本划分不同而造成的误差。常见的是“十次十折交叉验证”。
3,自助法:给定包含m个数据的样本D,每次从D中挑选一个样本放入D’,然后将其放回D中,重复m次,得到包含m个样本的数据集D’。
初始数据集约有36.8%的样本未出现在D’中,将D’用作训练集,D用作测试集。自助法适用于数据集较小,难以有效划分训练/测试集时很有效。
调参与最终模型
参数调节得不好往往对最终模型有关键性影响。
我们把学得模型在实际使用中遇到de数据称为测试数据,模型评估与选择中用于评估测试的数据集常称为验证集。
使用在测试集上的判别效果估计模型在实际使用时的泛化能力。
把训练集另外划分为训练集和验证集,基于验证集上的性能来进行模型选择和调参。
2.3性能度量
什么样的模型是好的,不仅取决于算法和数据,还取决于任务需求(误差评判方式)。
回归问题的常用性能度量是“均方误差”。
分类问题的性能度量是“错误率和精度”。
对于二分类问题,可将样例根据其真实类别与学习器预测的类别的组合划分为true positive:好瓜被认为是好瓜,true negative:坏瓜被认为是坏瓜,false positive:坏瓜被认为是好瓜,false negative:好瓜被认为是坏瓜。
查准率:好瓜被正确地判断为好瓜的比例(挑出的西瓜中有多少比例是好瓜)查准率是针对我们预测结果而言的,它表示的是预测为正的样例(TP+FP)中有多少是真正的正样例。
查全率:所有好瓜中有多少比例被挑了出来。查全率是针对我们原来的样本而言的,它表示的是样本中的正例(TP+FN)有多少被预测正确。定义公式如5所示。
查准率和查全率是一对矛盾的度量。一般来说,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。
思考一个问题:为什么会有这样的情况呢?
答案:我们可以这样理解,在一个分类器中,你想要更高的查准率,那么你的阈值要设置的更高,只有这样才能有较高的把握确定我们预测是正例是真正例。一旦我们把阈值设置高了,那我们预测出正例的样本数就少了,那真正例数就更少了,查不全所有的正样例。
P-R图直观地显示出学习器在样本总体上的查全率、查准率。
通过置信度就可以对所有样本进行排序,再逐个样本的选择阈值,在该样本之前的都属于正例,该样本之后的都属于负例。每一个样本作为划分阈值时,都可以计算对应的precision和recall,那么就可以以此绘制曲线。
若一个学习器的P-R曲线被另一个完全包裹,则后者的性能优于前者。
平衡点(Break-Event Point,BEP),是P=R时的取值,高的模型性能好。

有时对查全率和查准率的要求程度不同,用户推荐时查准率重要,抓犯人时查全率重要。因此有F1的一般形式:

ROC和AOC
很多学习器是为测试样本产生一个实值或概率预测,然后将预测值与分类阈值进行比较,大于阈值为正类,小于阈值为负类。可以根据该预测值将所有样例进行排序,如更重视查准率,则阈值在排序靠前的位置。如更重视查全率,阈值在排序靠后的位置。
ROC曲线从排序本身质量的好坏出发,研究学习器的泛化性能。
作图方式类似于P-R曲线,但横纵坐标变为真正确率(TPR)和假真确率(FPR):

作图方式:把样例按预测值排序,把每个分类阈值设定为当前样例的预测值,计算TPR和FPR。得到ROC曲线。
AUC(Area Under roc Curve)即ROC曲线的面积,AUC考虑的是样本预测的排序质量,因此它与排序误差联系紧密。
1.ROC曲线能很容易的查出任意阈值对学习器的泛化性能影响。
2.有助于选择最佳的阈值。ROC曲线越靠近左上角,模型的查全率就越高。最靠近左上角的ROC曲线上的点是分类错误最少的最好阈值,其假正例和假反例总数最少。
3.可以对不同的学习器比较性能。将各个学习器的ROC曲线绘制到同一坐标中,直观地鉴别优劣,靠近左上角的ROC曲所代表的学习器准确性最高。

AUC就是从所有正样本中随机选择一个样本,从所有负样本中随机选择一个样本,然后根据你的学习器对两个随机样本进行预测,把正样本预测为正例的概率p1,把负样本预测为正例的概率p2,p1>p2的概率就等于AUC。所以AUC反映的是分类器对样本的排序能力。根据这个解释,如果我们完全随机的对样本分类,那么AUC应该接近0.5。
代价敏感错误率与代价曲线
不同的分类错误所造成的代价不同(如医生判定健康人和病人)。
前面的性能度量大都假设了均等代价,如错误率是直接计算错误次数。如果算上不同的代价,则得出的是代价敏感错误率:
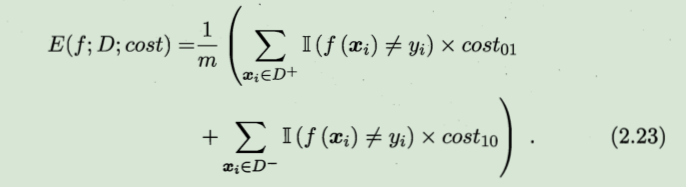
非均等代价下,ROC曲线不再适用,而“代价曲线”可以达到该目的。
2.4 比较检验
统计假设检验是进行学习器性能比较的重要依据,基于假设检验的结果可推断出,若在测试集上观察到学习器A比B好,则A的泛化性能是否在统计意义上优于B,以及这个结论的把握有多大。
2.4.1假设检验
泛化错误率与测试错误率未必相同,但应该会比较接近。因此可根据测试错误率估推出泛化错误率的分布。
泛化错误率e被测得测试错误率为e’的概率
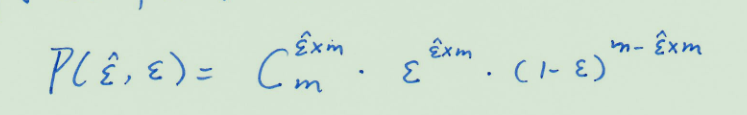
查全率: 真实正例被预测为正例的比例
真正例率: 真实正例被预测为正例的比例
显然查全率与真正例率是相等的。
查准率:预测为正例的实例中真实正例的比例
假正例率: 真实反例被预测为正例的比例
两者并没有直接的数值关系。














 431
431











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









