







 本文详细介绍了目标检测中的各种技巧,包括训练阶段的warmup策略、软NMS、GIoU等,以及测试阶段的数据增强技术如TTA。还讨论了伪标签法和模型集成方法,如Ensemble和Weighted Box Fusion,以提高模型性能。
本文详细介绍了目标检测中的各种技巧,包括训练阶段的warmup策略、软NMS、GIoU等,以及测试阶段的数据增强技术如TTA。还讨论了伪标签法和模型集成方法,如Ensemble和Weighted Box Fusion,以提高模型性能。
1 目标检测通用trick


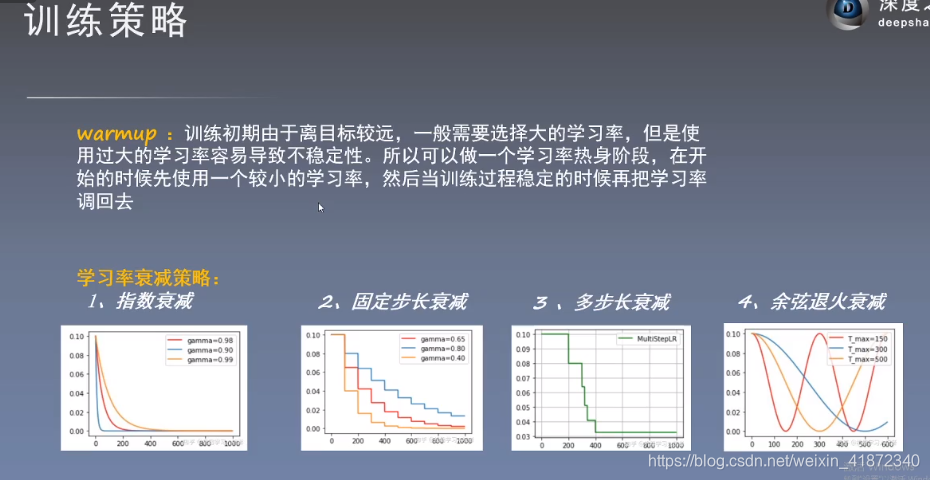
👆warmup:先用小学习率训练几个epoch,当稳定后再调大,防止学习一开始就陷入局部极小

👆:将原本为0或1的标签设置为0.99或其他数,使模型避免过于自信
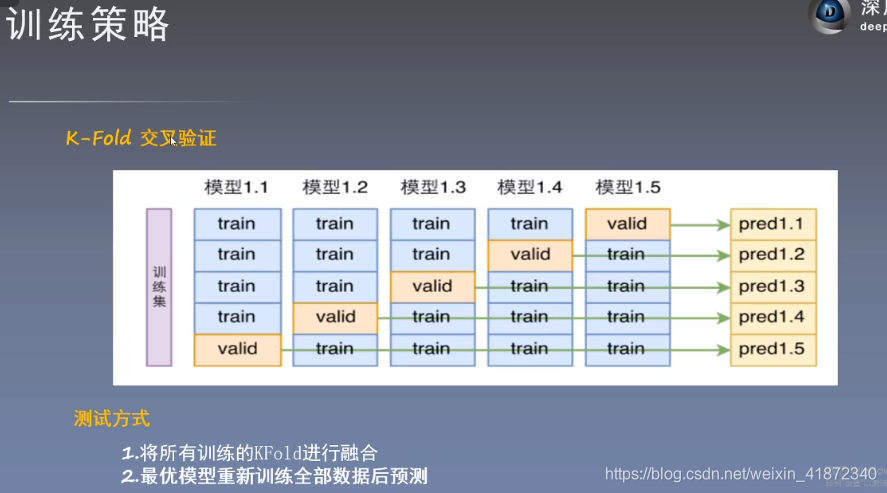

👆:soft nms,可以保留重叠区域的框

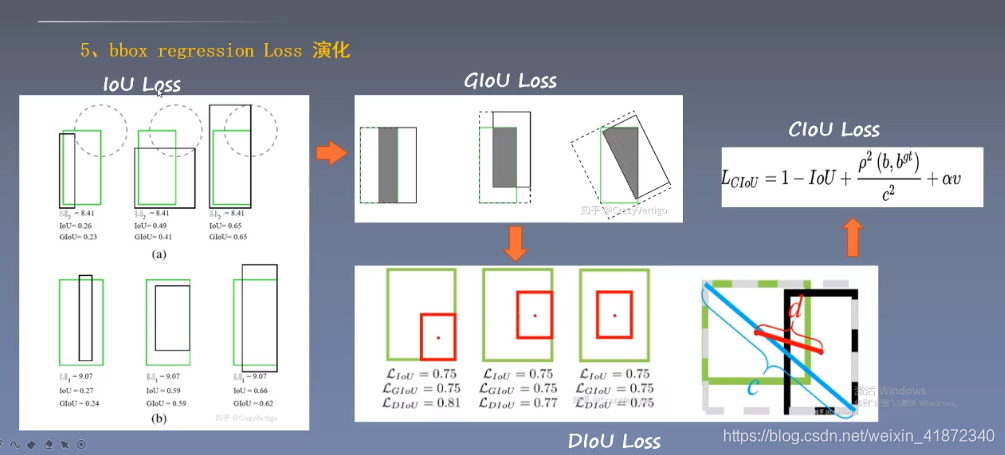
👆:iou不能反映两框中心点位置关系
2.Baseline中的trick

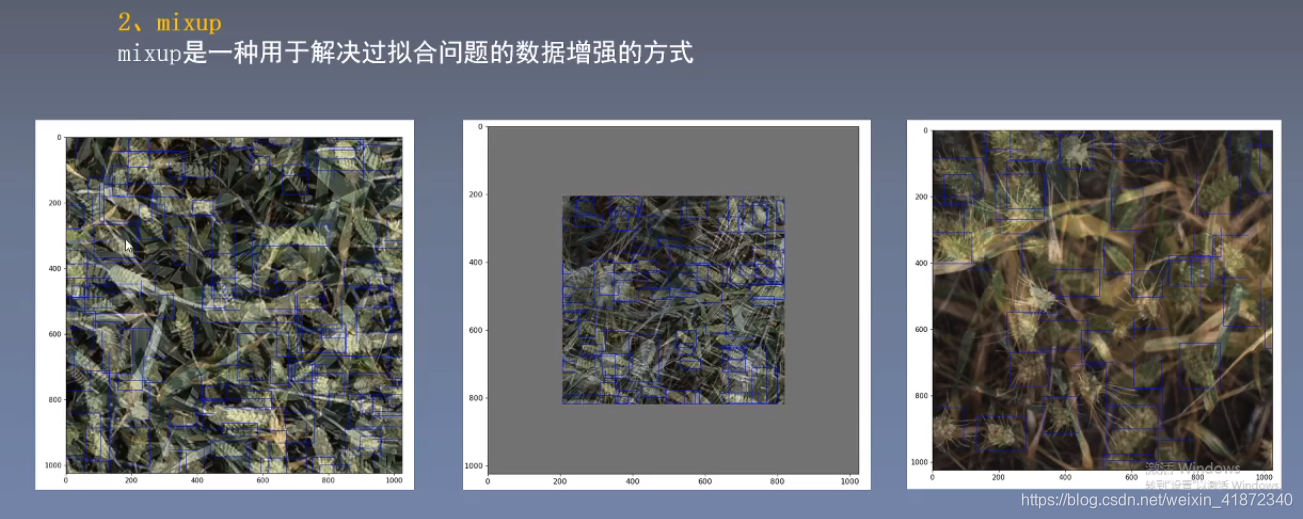
👆:以不同的比例混合两张图,并能模拟遮挡的效果
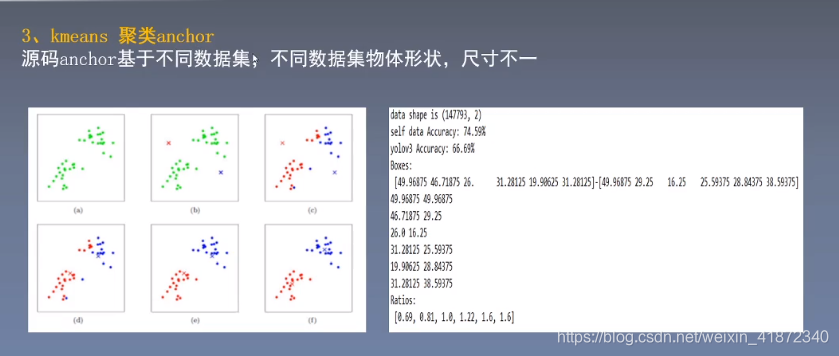
👆:anchor是基准框,每次拟合时,都照基准框的方向进行拟合
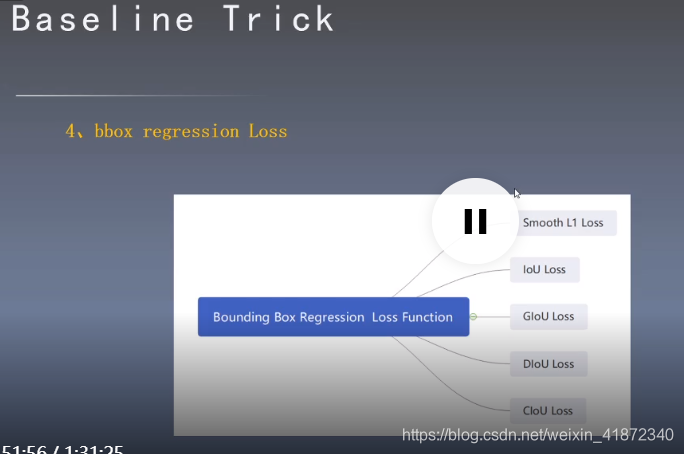
smoothL1:计算四个点的损失1
GIOU:用一个框包围预测框和真实框,进行计算
Diou:把包围框的对角线距离和中心点的距离都考虑进来
ciou:把预测矿和真实框的宽高加入

拉近与gt的距离,拉远与其他框的距离
测试阶段trick
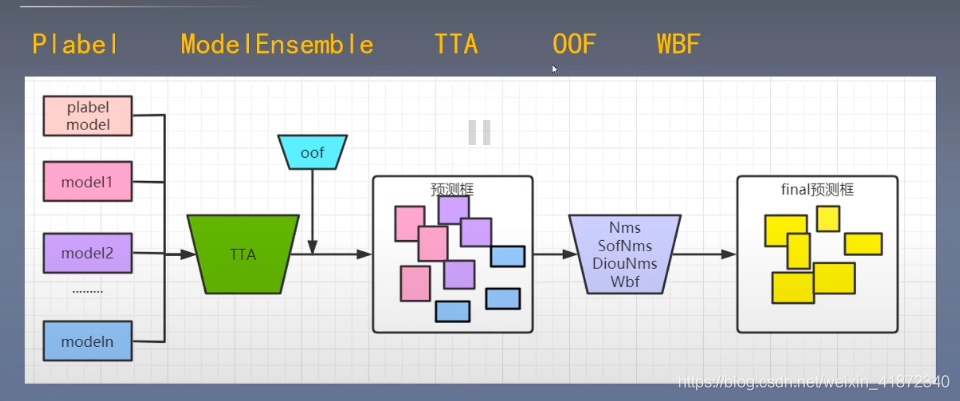
👆:TTA:测试时数据增强。一张图像变形成多张,增加测试样本数量,对结果进行融合。使测试结果更好。
OOF:对框的置信度进行处理,滤除置信度较小的物体,如果阈值较高,那么召回率就会降低(漏检),如果阈值较低,召回率上升,精确度下降(误检)。因此选定合适的阈值很重要。而OOF就是选择阈值的方法。
NMS系列:对框去重。(wbf也是去重作用)。
Pseudo-labelling
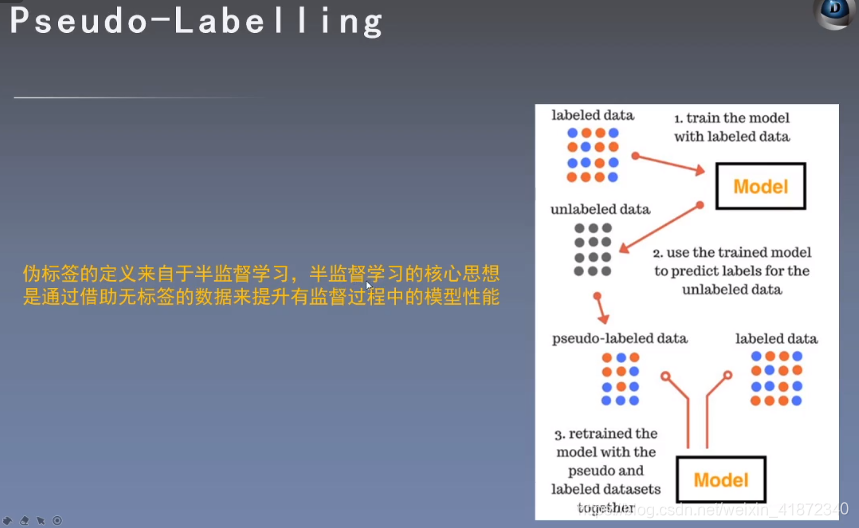
👆:用有标签的数据训练模型,对未标签测试数据用模型打标签,将测试数据和训练数据重新训练模型。
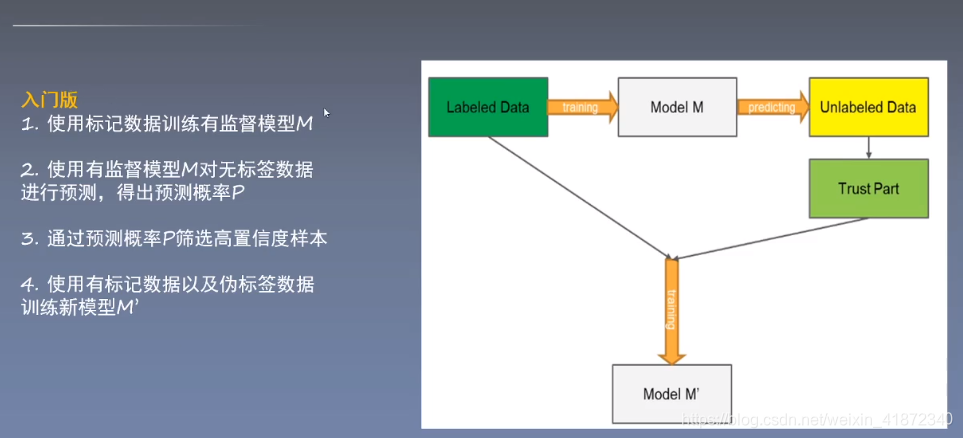
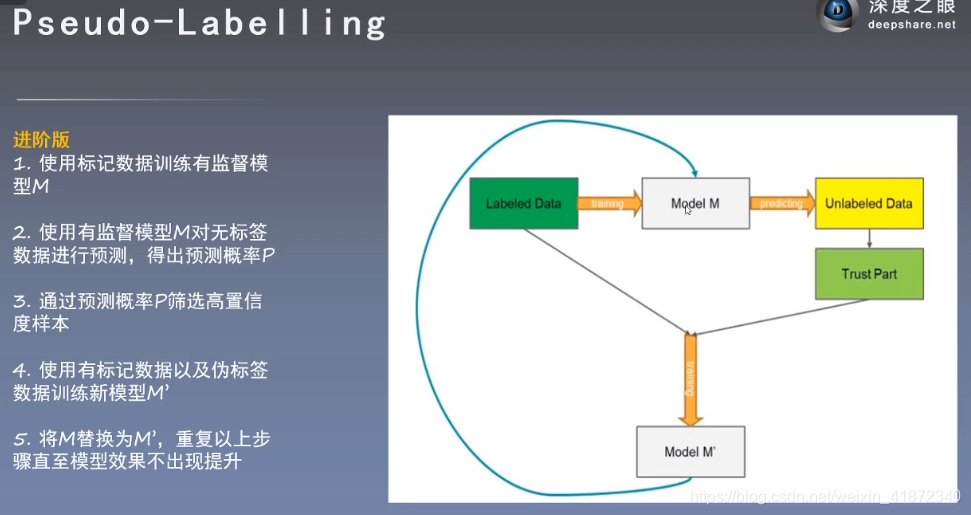
进阶版进行重复训练以提升效果
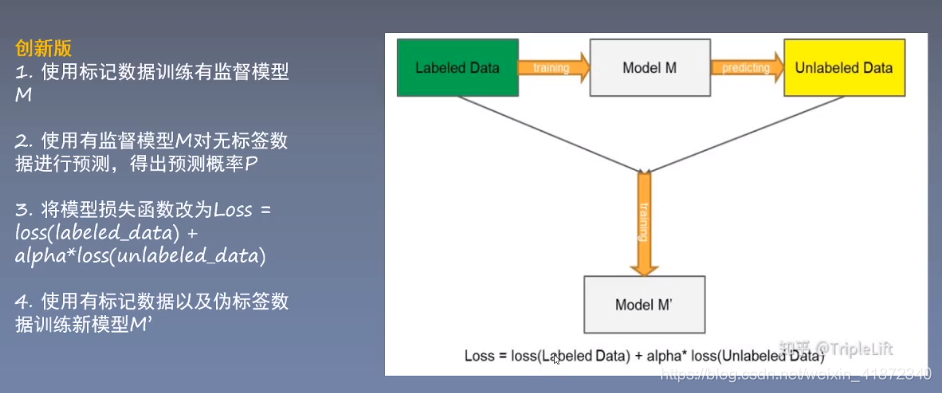
对损失加上不同的权重(通过减小未标签的损失权重)
from utils.datasets import *
from utils.utils import *
def makePseudolabel():
source = '../input/global-wheat-detection/test/' # 拿测试数据
weights = WEIGHTS # 模型权重
imagenames = os.listdir(source)
device = torch.device('cuda') if torch.cuda.is_available() 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1383
1383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









