







chapter 9 聚类
9.1聚类任务
在无监督学习中,训练样本的标记未知,目标是通过无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础,此类学习中应用最广,研究最多的是“聚类”。
聚类试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个簇,通过这样的划分,每个簇可能对应一些潜在的概念(类别),如“浅色瓜”,“深色瓜”,“有籽瓜”等。这些概念对聚类算法而言事先是未知的,聚类过程仅能自动形成簇结构,簇所对应的概念语义需由使用者来把握和命名。
聚类既能作为一个单独过程,用于找寻数据内在的分布结构,也可作为分类等其他学习任务的前驱过程,例如在商业应用中需对新用户的类型进行判别,但定义“用户类型”对商家来说并不容易,此时往往可先对用户数据进行聚类,根据聚类结果将每个簇定义为一个类,然后再基于这些类训练分类模型,用于判别新用户的类型。
基于不同的学习策略,人们设计出多种类型的聚类算法,先讨论聚类算法涉及的两个基本问题–性能度量和距离计算。
9.2 性能度量
聚类性能度量亦称聚类“有效性指标”,与监督学习的性能度量类似,对聚类结果,我们需通过某种性能度量来评估其好坏,另一方面,若明确了最终将要使用的性能度量,则可直接将其作为聚类过程的优化目标,从而更好地得到符合要求的聚类结果。
较好的聚类结果是“簇内相似度”高且“簇间相似度”低。
聚类性能度量有两类:1、将聚类结果与某个“参考模型”进行比较,称为“外部指标”;另一类是直接考察聚类结果而不利用任何参考模型,称为“内部指标”。
对数据集D,假定聚类给出的簇划分为C={C1,C2…Ck},参考模型给出的簇划分为C*={C1*,C2*…Cs*},将样本两两配对考虑,定义:
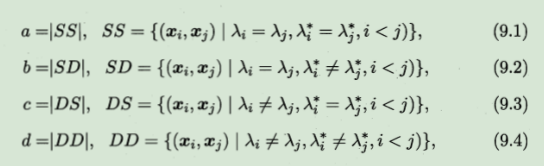
a表示xi和xj在C和C中都属于同一个簇的样本对数,b表示在C中属于相同簇,但在C中属于不同簇的样本对数,以此类推。
基于9.1-9.4可导出下面这些常用的聚类性能度量外部指标:
1、Jaccard系数:

2、FM指数:

3、Rand指数:

上面这些值越大,聚类结果越好。
聚类性能度量内部指标
考虑聚类结果的簇划分C={C1,C2…Ck},定义:

dist用于计算两个样本之间的距离,μ代表簇C的中心点。
avg(C)对应于簇C内样本间的平均距离,diam(C)对应簇C内样本间的最远距离,dmin(Ci,Cj)对应于两个簇最近样本间的距离,dcen(Ci,Cj)对应于两个簇中心点间的距离。
基于9.8-9.11可导出下面这些常用的聚类性能度量内部指标。
1、DB指数,简称DBI
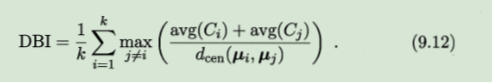
2、Dunn指数,简称DI
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 380
380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









