







文章目录
前言
近年来,空气质量问题日益严峻,备受关注。对收集的有关空气质量指数相关的数据进行一个简单的分析。
一、背景
Ⅰ数据来源
数据来源于网络,数据下载,提取码:lrm8
Ⅱ 数据背景
该数据集是指2015年某些城市数据, 包含全国主要城市的相关数据及空气质量指数,其包含326个样本以及12个特征, 这10个特征分别为: 城市,空气质量指数,降雨量,城市生产总值,温度,经度,纬度,海拔高度,人口密度,是否沿海,绿化覆盖率,焚烧量(10000t).
Ⅲ 分析目的
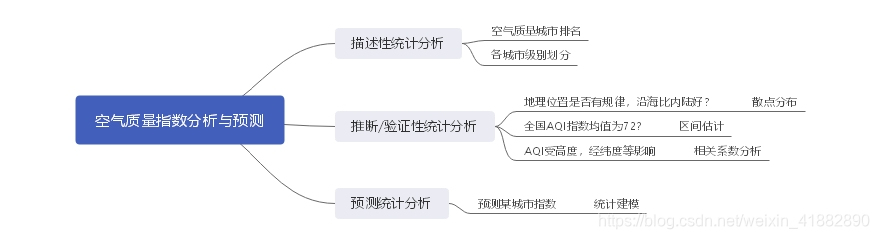
二、数据探索性分析
Ⅰ 数据类型
data.info()
city特征为字符型, AQI、PopulationDensity、Coastal为64位整型, 其余为64位浮点型, 且均无缺失值.只有Precipitation缺少少量的数据。
Ⅱ 描述性统计
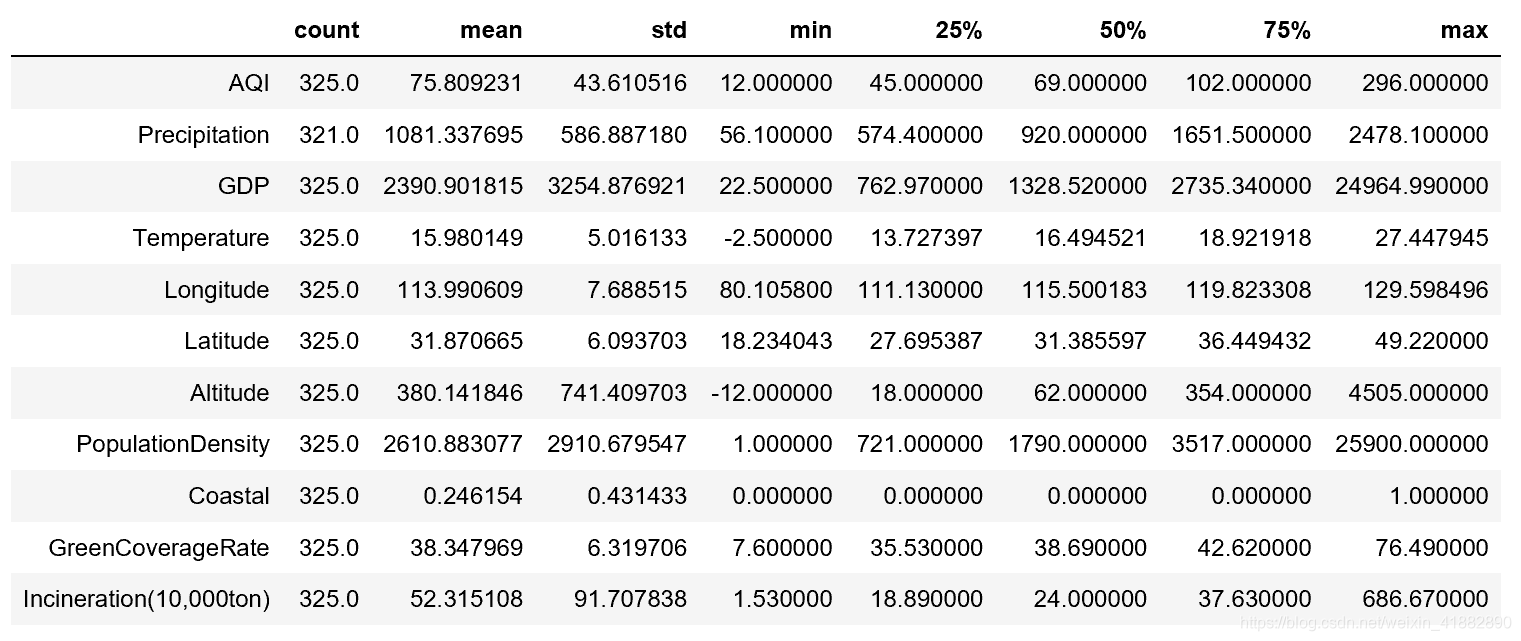
- AQI平均水平;75.8,最高为296,最低为12。中位数与平均数相差不大,只存在少量极值,呈现右偏趋势。
Ⅲ 数据预处理
1.缺失值处理
1)删除缺失值
print(data.Precipitation.skew()) #skew求偏态系数
sns.distplot(data.Precipitation.dropna()) #dropna()删掉缺失的数据,displot不能处理缺失的数据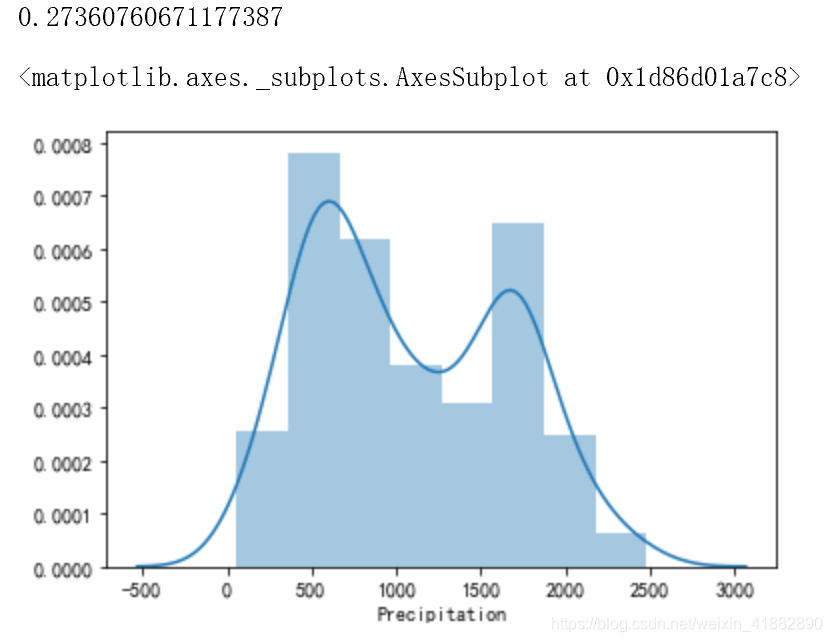
2)均值/中值填充
data.fillna({'Precipitation':data['Precipitation'].median()},inplace=True)2.异常值处理
利用Boxplot查看异常值
plt.figure(figsize=(15,4))
plt.xticks(rotation=45,fontsize=15)
sns.boxplot(data=data)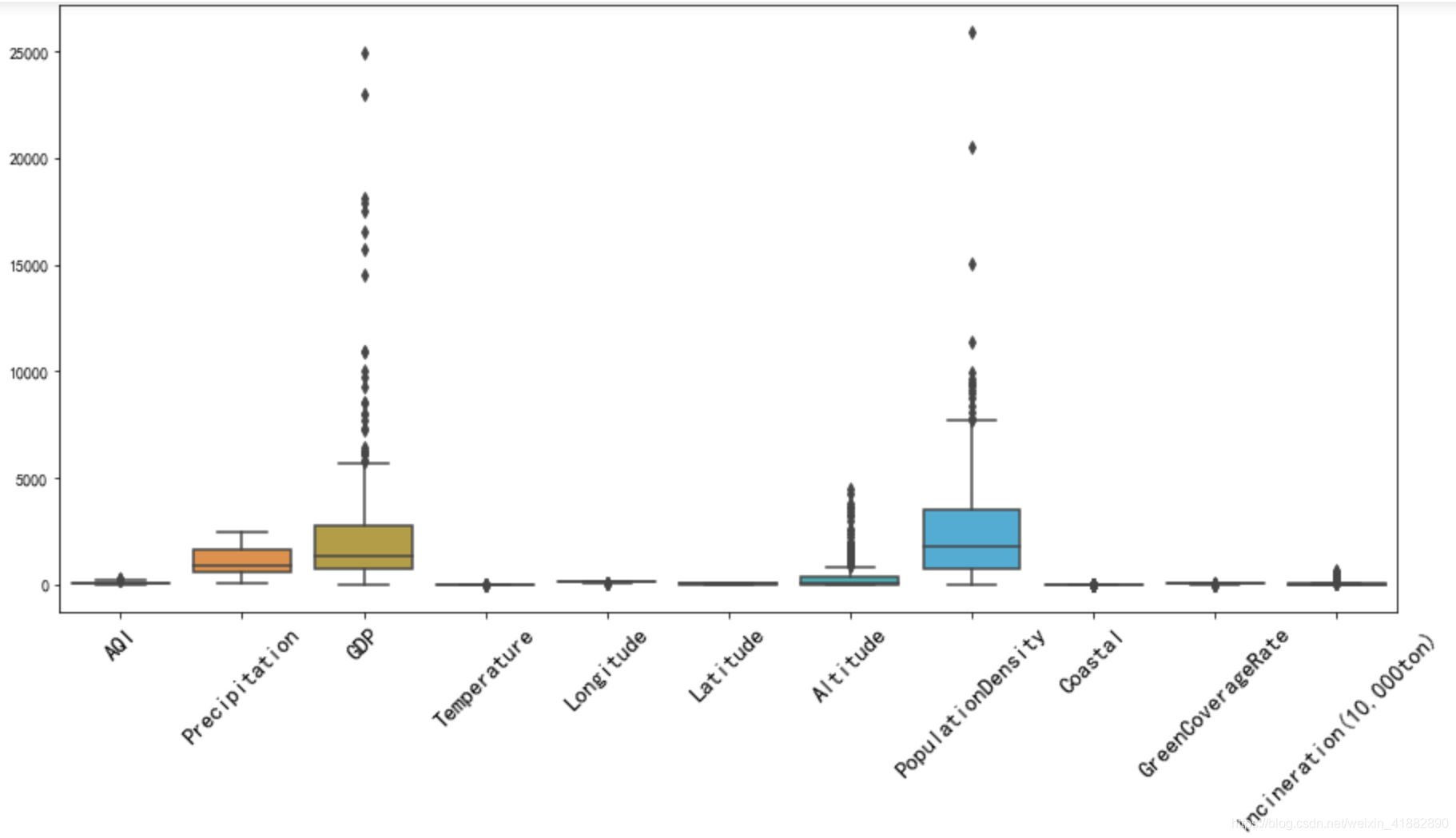
三个特征值存在明显的异常值,利用箱体图进行处理
t=data.copy()
for k in t:
if pd.api.types.is_numeric_dtype(t[k]):
o = t[k].describe()
IQR = o["75%"] - o["25%"]
lower = o["25%"] - 1.5 * IQR
upper = o["75%"] + 1.5 * IQR
t[k][t[k] < lower] = lower
t[k][t[k] > lower] = upper
plt.figure(figsize=(15,4))
plt.xticks(rotation=45,fontsize=15)
sns.boxplot(data=t)这里存在一点问题,第一次可以成功运行,第二次就不可以了。求大神指教🙊
3.重复值处理
#发现重复值
print(data.duplicated().sum())
#查看哪些记录出现了重复值
data[data.duplicated()]
存在两条重复值,由于数量小,可以直接删除。data.drop_duplicates(inplace=True)
三、数据分析
Ⅰ空气质量排名
plt.subplot(231)
#空气最好前五/最差五个的城市
best=data[['City','AQI']].sort_values(by=['AQI'])
print(best.head(5))
plt.xticks(rotation=45)
plt.title('空气质量最好排名')
sns.barplot(x='City',y='AQI',data=best.head(5))
plt.subplot(233)
low=data[['City','AQI']].sort_values(by=['AQI'],ascending=False)
print(best.head(5))
plt.xticks(rotation=45)
plt.title('空气质量最差排名')
sns.barplot(x='City',y='AQI',data=low.head(5))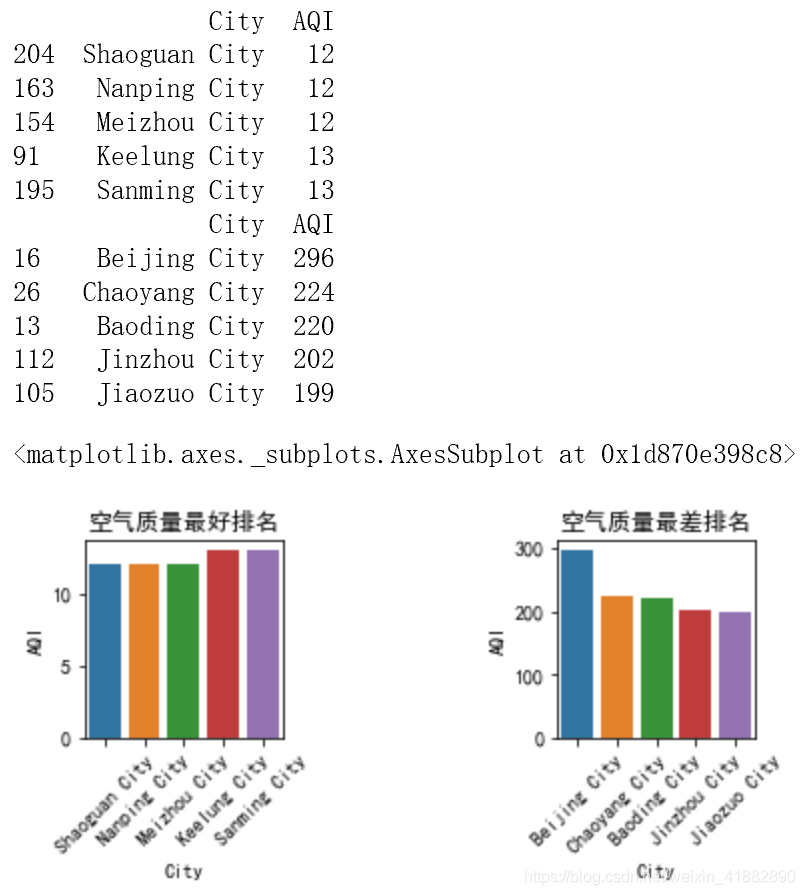
最好的为:韶关,南平,梅州,基隆,三明
最差的为:北京,朝阳,保定,锦州,焦作
Ⅱ 全国空气质量
1.全国空气质量等级统计
def value_to_level(AQI):
if AQI>=0 and AQI<=50:
return '一级'
elif AQI>=51 and AQI<=100:
return '二级'
elif AQI>=101 and AQI<=150:
return '三级'
elif AQI>=151 and AQI<=200:
return '四级'
elif AQI>=201 and AQI<=300:
return '五级'
else:
return '六级'
level=data['AQI'].apply(value_to_level)
print(level.value_counts())
sns.countplot(x=level,order=['一级','二级','三级','四级','五级','六级'])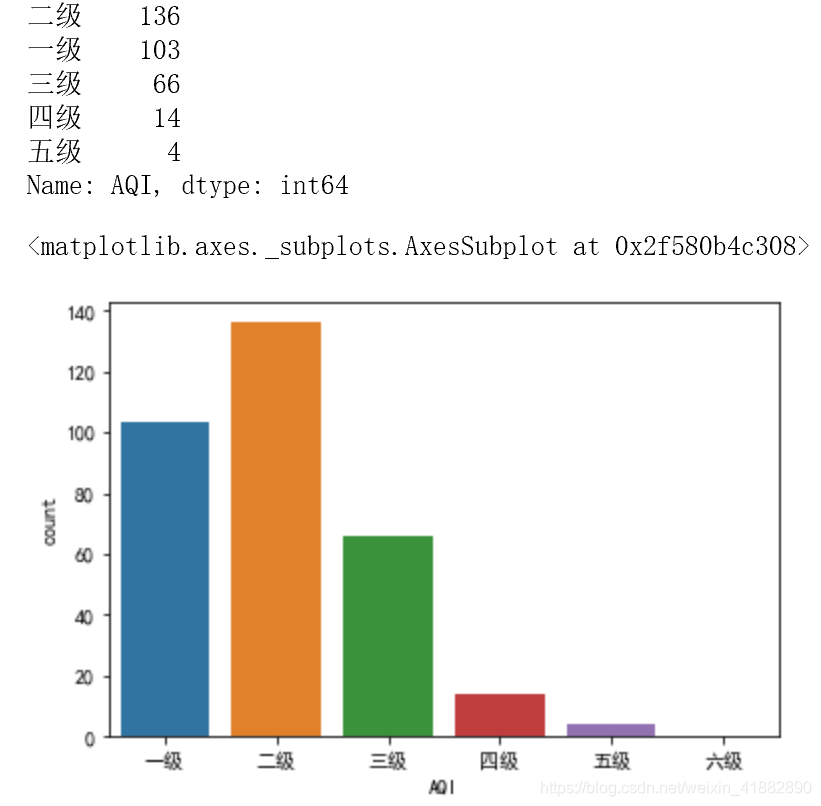
一二级空气质量等级最多,大部分城市的空气质量还是不错的,但是有18个属于四五级的城市需要重点改造。
2.全国空气指数分布
sns.scatterplot(x='Longitude',y='Latitude',hue='AQI',palette=plt.cm.RdYlGn_r,data=data)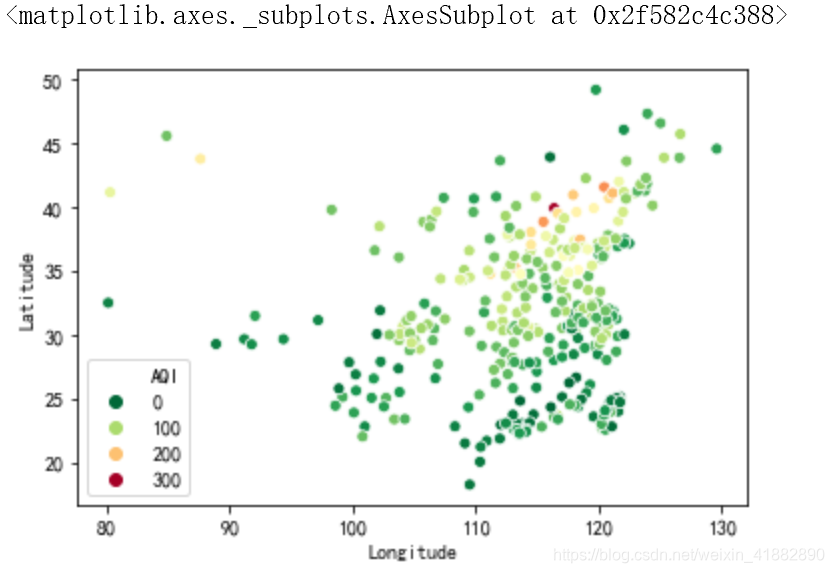
大概可以看出南方好于北方,西方好于东方
Ⅲ 推断验证
1.全国空气质量指数网传为72
简单分析:
data['AQI'].mean()
计算出来为75.334。但是不能下网传不对的结论。如果数据是全国所有城市,那就可以下结论,因此从全国城市中进行抽样,使用抽样的均值来估计总体均值。
- 中心极限定理:在适当的条件下,大量相互独立随机变量的均值经适当标准化后依分布收敛于正态分布。每次从这些总体中随机抽取 n 个抽样,一共抽 m 次。 然后把这 m 组抽样分别求出平均值, 这些平均值的分布接近正态分布。设从均值为μ、方差为(有限)的任意一个总体中抽取样本量为n的样本,当n充分大时,样本均值的抽样分布近似服从均值为μ、方差为的正态分布。
中心极限定理告诉我们,当样本量足够大时,样本均值的分布慢慢变成正态分布
#定义总体数据
total=np.random.normal(loc=30,scale=80,size=10000)
#创建均值数据
mean=np.zeros(1000)
for i in range(len(mean)):
mean[i]=np.random.choice(total,size=64,replace=False).mean()
print('样本均值:',mean.mean())
print('样本标准差:',mean.std())
print('偏度:',pd.Series(mean).skew())
sns.distplot(mean)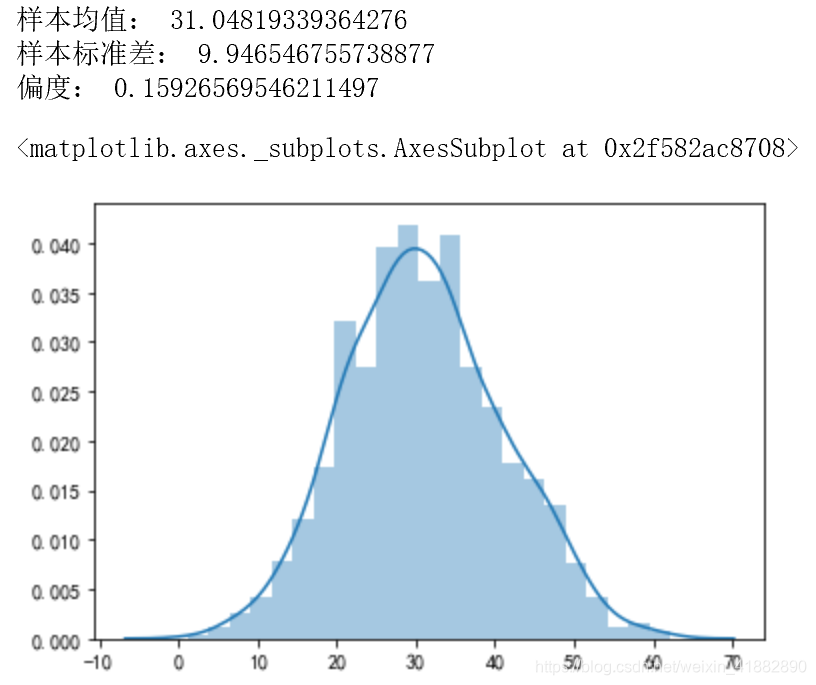
- 置信区间
根据正态分布特性,进行概率上的统计。标准正态分布数据分布比例如下图
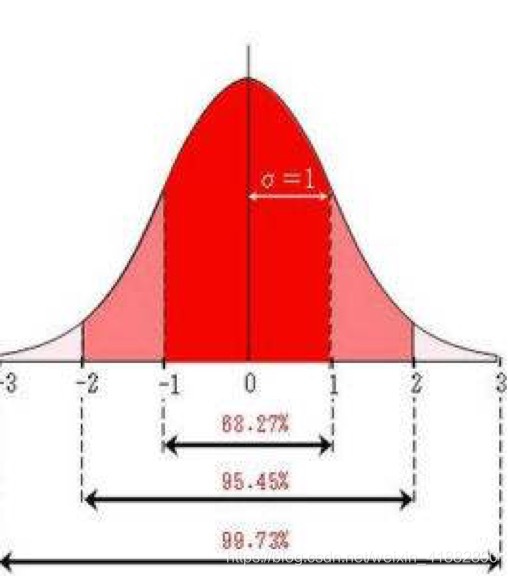
一般正态分布数据分布比例如下图
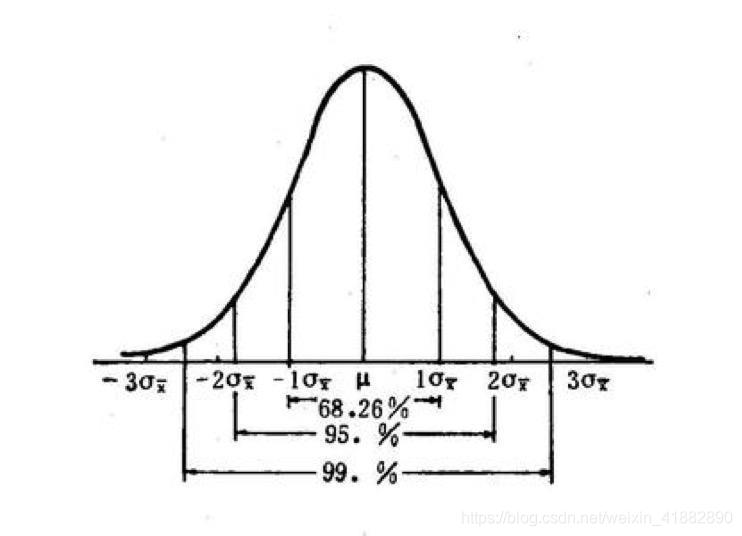
#定义标准差
scale=50
#定义数据
x=np.random.normal(0,scale,size=100000)
#定义标准差的倍数,倍数从1到3
for times in range(1,4):
y=x[(x>=-times*scale)&(x<=times*scale)]
print(f'{times}倍标准差:')
print(f'{len(y)*100/len(x)}%')运行结果:1倍标准差:68.13%,2倍标准差:95.445%,3倍标准差:99.719%
通常我们以二倍标准差作为评定依据,则以均值为中心,正负二倍标准差构成的区间就是置信区间,而二倍标准差区间包含95%的数据,因此此时的置信区间为95%。换言之总体的均值有95%的可能在置信区间内。
- 假设检验–t检验:统计量服从t分布,当自由度(样本容量-1)逐渐增大时,t分布近似于正态分布
from scipy import stats
r=stats.ttest_1samp(data['AQI'],72)
print('t值',r.statistic)
print('p值',r.pvalue)`计算结果:t值 1.393763441074581 p值 0.16435019471704654。P值大于0.05,故在显著度为0.05检验下无法拒绝原假设。
#计算全国平均空气质量指数均值
n=len(data)
df=n-1
left=stats.t.ppf(0.025,df=df)
right=stats.t.ppf(0.975,df=df)
print(left,right)
mean=data['AQI'].mean()
std=data['AQI'].std()
mean+left*(std/np.sqrt(n)),mean+right*(std/np.sqrt(n))计算结果:-1.9673585853224684 1.967358585322468
(70.6277615675309, 80.0409690826239)
结论:全国空气质量指数所在区间大概在70.63-80.04之间,置信度为95%
2.沿海城市是否空气质量更好
plt.subplot(131)
#沿海\内陆城市数量
display(data['Coastal'].value_counts())
plt.title('沿海、内陆城市数量')
sns.countplot(x='Coastal',data=data)
plt.subplot(133)
#临海城市和内陆城市散点分布
plt.title('临海城市和内陆城市散点分布')
sns.swarmplot(x='Coastal',y='AQI',data=data)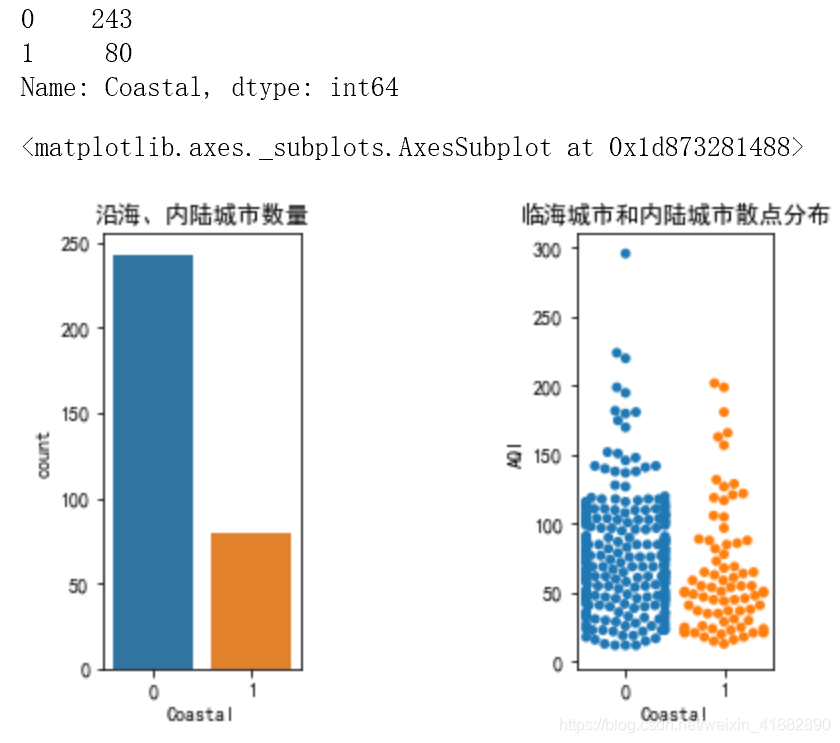
#分别计算均值
display(data.groupby('Coastal')['AQI'].mean())
#sns.barplot(x='Coastal',y='AQI',data=data)
sns.violinplot(x='Coastal',y='AQI',data=data,inner=None)
sns.swarmplot(x='Coastal',y='AQI',color='r',data=data)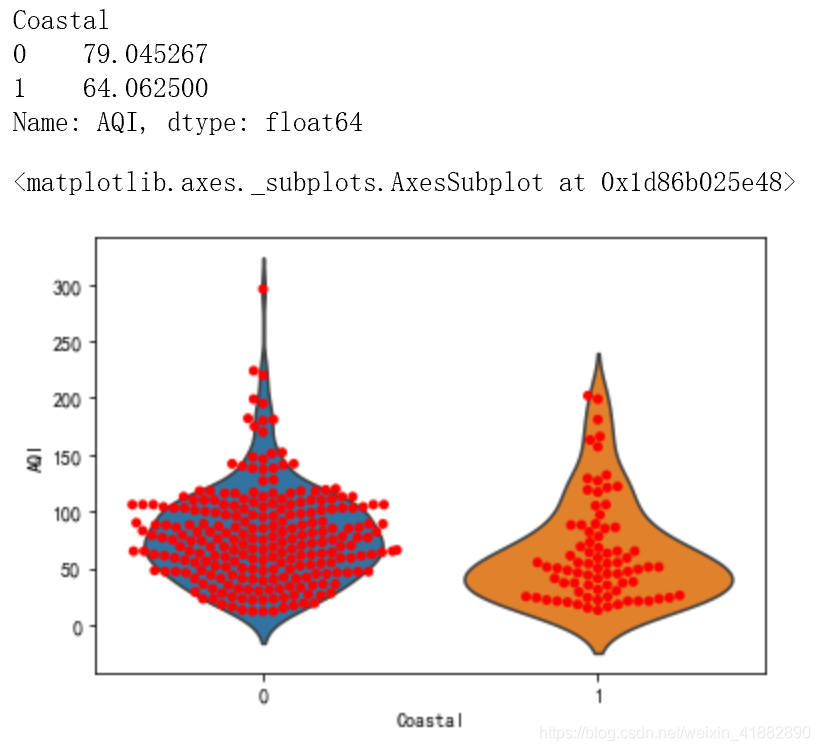
大致可得出结论:沿海城市空气质量普遍好于内陆城市
- 两样本t检验验证
`coastal=data[data['Coastal']==1]['AQI']
inland=data[data['Coastal']==0]['AQI']
#进行方差齐性检验,为后续的两样本t检验服务
print(stats.levene(coastal,inland))
stats.ttest_ind(coastal,inland,equal_var=True)`计算结果:LeveneResult(statistic=0.08825036641952543, pvalue=0.7666054880248168)
Ttest_indResult(statistic=-2.7303827520948905, pvalue=0.006675422541012958)
有99%的概率可以认为沿海空气质量比内陆好
3.空气质量受什么影响
AQI与人口密度,绿化覆盖率影响
sns.pairplot(data[['AQI','PopulationDensity','GreenCoverageRate']])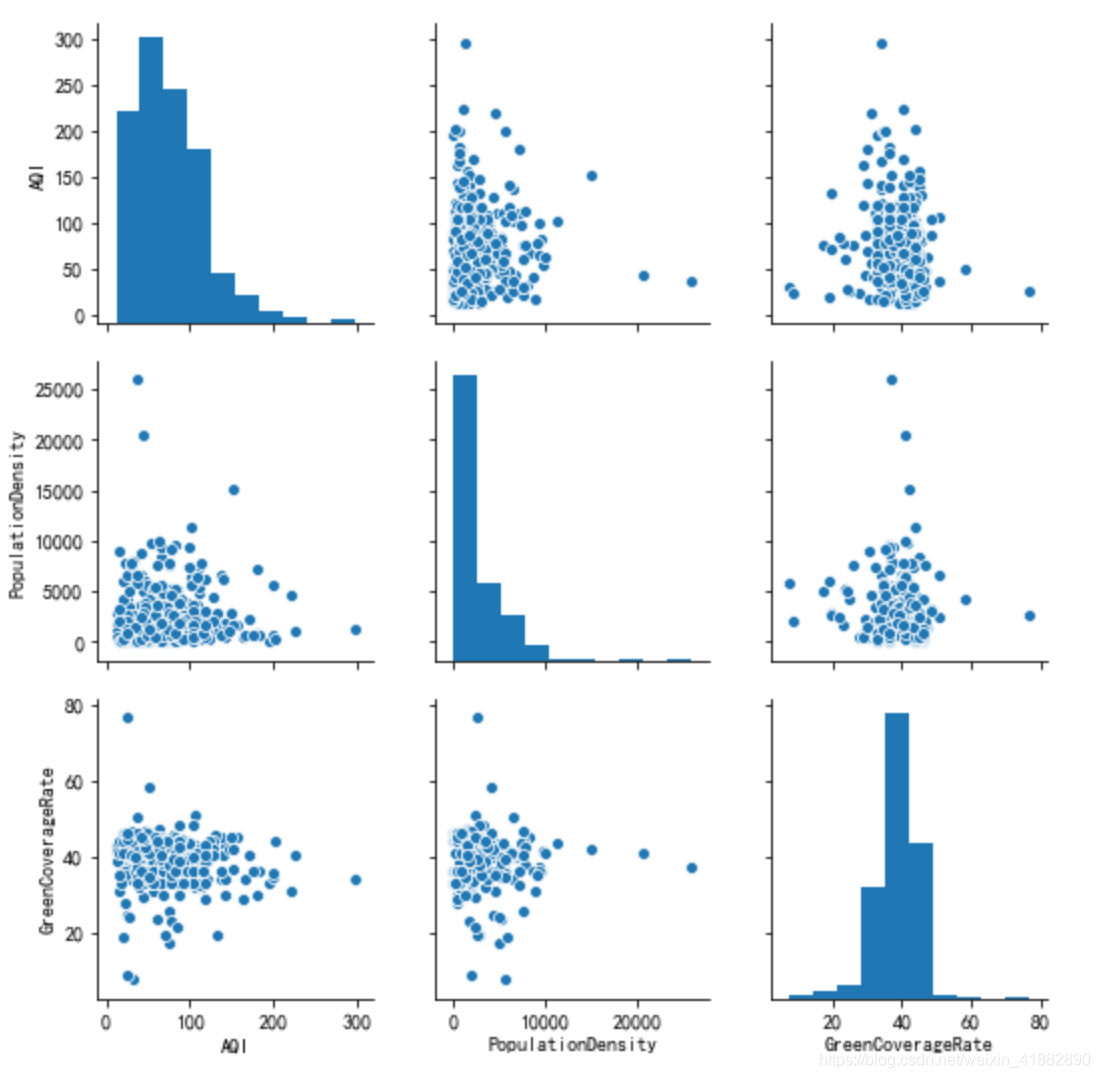
plt.figure(figsize=(15,8))
sns.heatmap(data.corr(),cmap=plt.cm.RdYlGn,annot=True,fmt='.2f')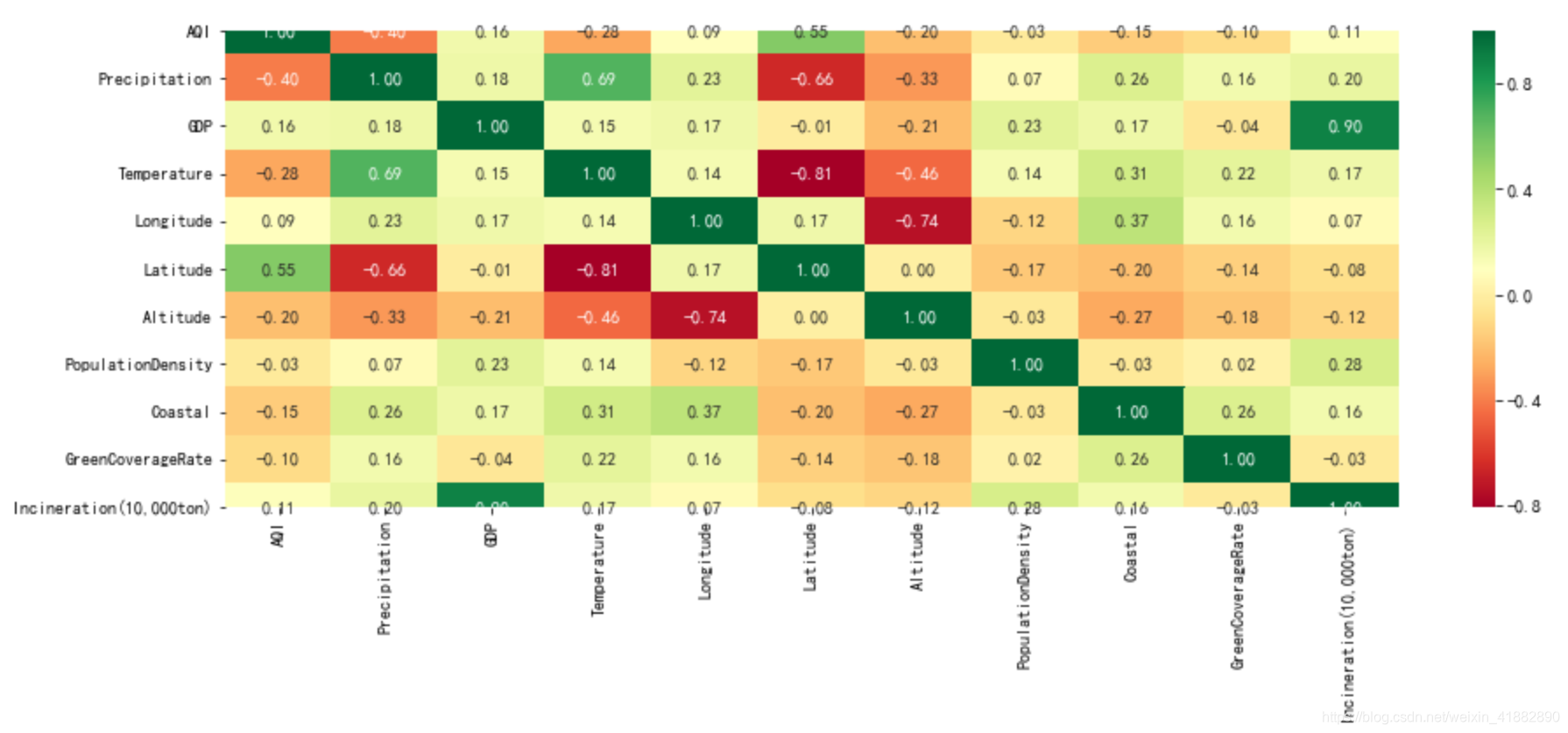
结论:空气质量主要受降水量和纬度影响。与降水量呈正比,纬度呈反比。ps:存在一个可疑相关系数,沿海空气质量好,但却只有-0.15。有需求可进行具体分析。
Ⅳ 预测空气质量指数
- 线性回归预测
#对空气质量进行预测
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
X=data.drop(['City','AQI'],axis=1)
y=data['AQI']
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=0)
lr=LinearRegression()
lr.fit(X_train,y_train)
y_hat=lr.predict(X_test)
print(lr.score(X_train,y_train))
print(lr.score(X_test,y_test))
plt.figure(figsize=(15,6))
plt.plot(y_test.values,'-r',label='真实值',marker='o')
plt.plot(y_hat,'-g',label='预测值',marker='D')
plt.legend()
plt.title("线性回归预测结果",fontsize=20)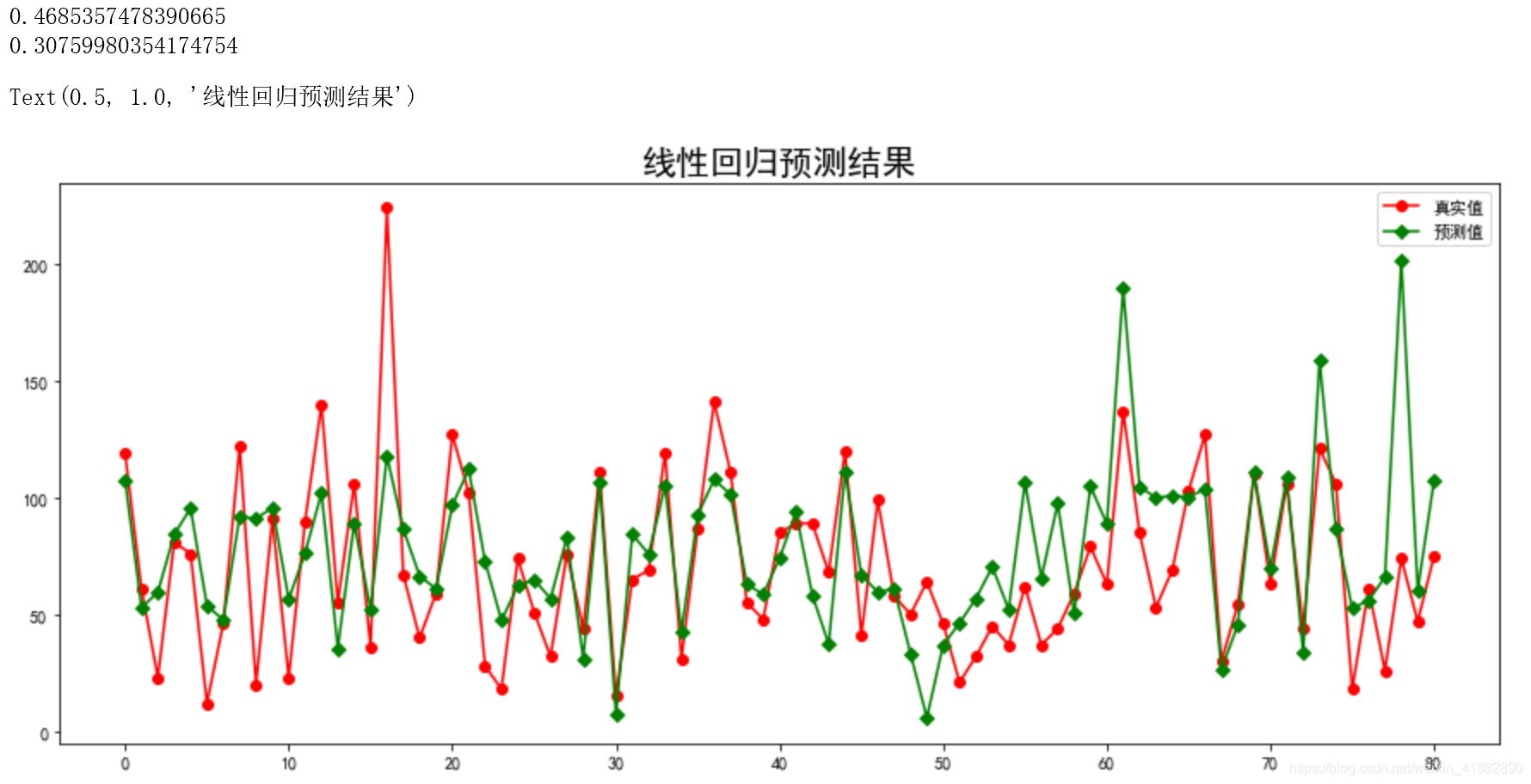
但线性回归的拟合性不是很好,因为在高维空间中并没有呈现线性关系
- 随机森林预测
from sklearn.ensemble import RandomForestRegressor
rf=RandomForestRegressor(n_estimators=500,random_state=0)
rf.fit(X_train,y_train)
y_hat=rf.predict(X_test)
print(rf.score(X_train,y_train))
print(rf.score(X_test,y_test))
plt.figure(figsize=(15,6))
plt.plot(y_test.values,'-r',label='真实值',marker='o')
plt.plot(y_hat,'-g',label='预测值',marker='D')
plt.legend()
plt.title("随机森林预测结果",fontsize=20)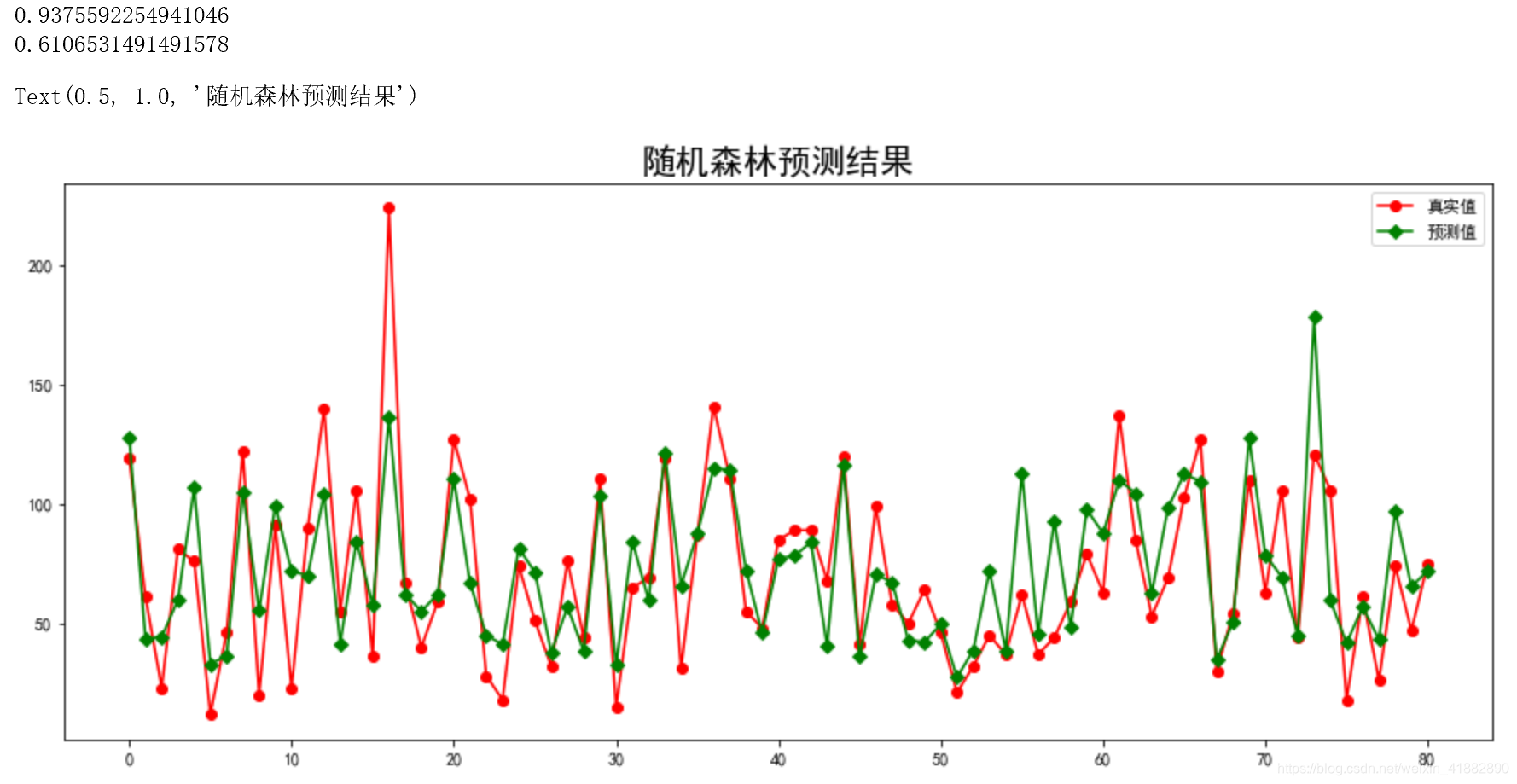
四、总结
空气总体质量南部好于北部,西部好于东部;沿海好于内地。
降雨量与纬度对空气质量影响较大,存在一个可以相关系数,即沿海。
我国城市平均质量指数在70.63到80.04之间,概率高达95%。
通过历史数据,可以进行预测。
虽然我国整体空气质量较好,但是一级的也不是最多的,且四五级占的比例也不低,因此需要加快整治步伐,同时大力宣传,提升国民的环保意识。

















 1656
1656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









