







 文章探讨了如何通过用户行为序列建模,如lastN行为序列和DIN/SIM模型,来增强召回、粗排和精排过程中的用户特征表示。小红书实践中,结合不同行为向量和物品类别信息提高了效果。DIN模型通过注意力机制优化,而SIM则关注长期兴趣并控制计算成本。
文章探讨了如何通过用户行为序列建模,如lastN行为序列和DIN/SIM模型,来增强召回、粗排和精排过程中的用户特征表示。小红书实践中,结合不同行为向量和物品类别信息提高了效果。DIN模型通过注意力机制优化,而SIM则关注长期兴趣并控制计算成本。
一、用户行为序列建模
- 用户行为序列特征加到 召回、粗排、精排,都会有收益
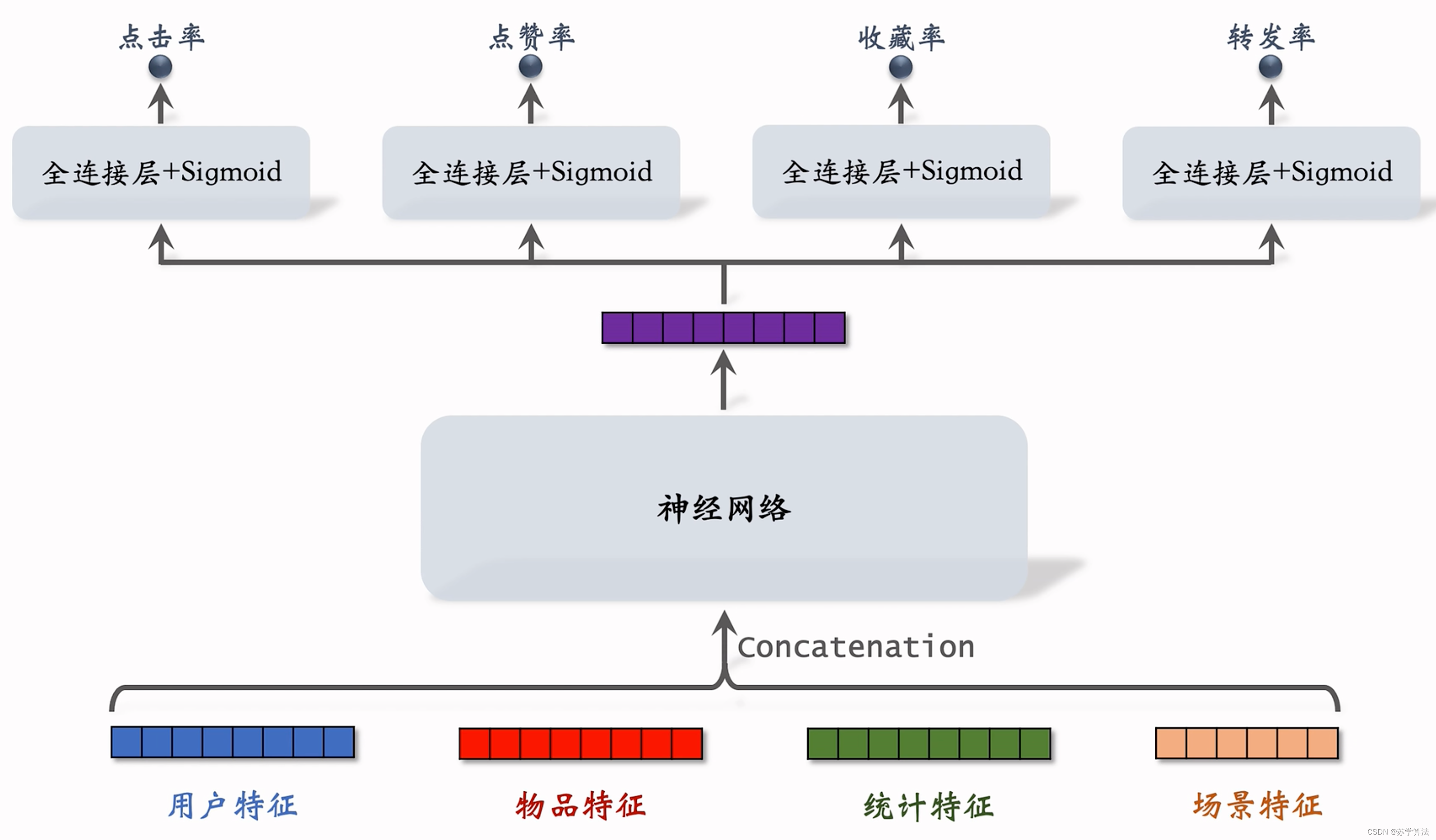
1.1 普通多目标排序模型
下面是普通的多目标排序模型
1.2 用户的 lastN 行为序列
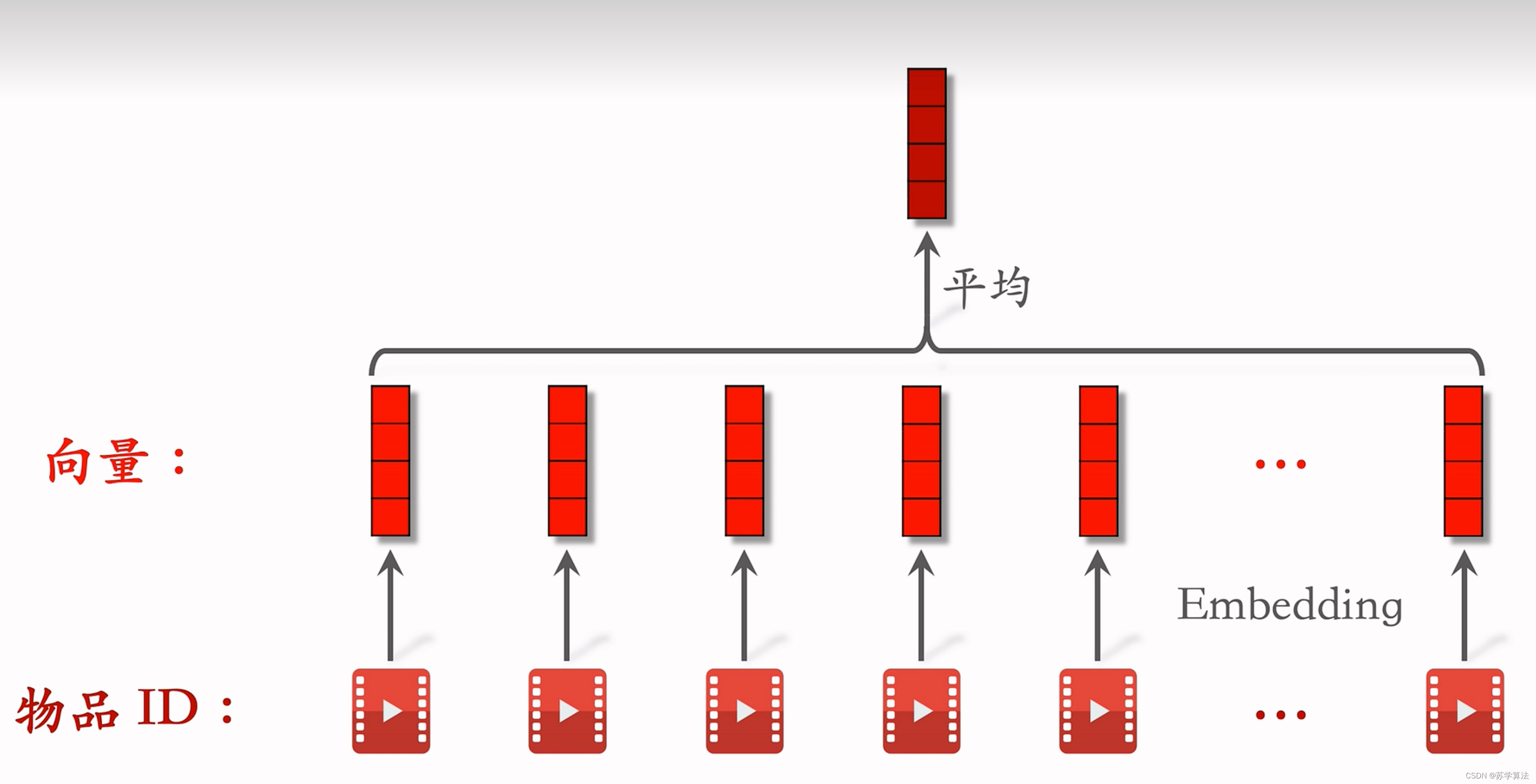
- 这里重点关注 “用户特征” 中的 lastN 行为序列,也就是用户最近交互(曝光、点击、转化等等)过的 N 个物品序列(物品id序列、物品类目序列)
- 做embedding:把N个物品id映射成N个向量,最后对向量取平均得到一个向量,这个向量可以作为用户的一种特征,表示用户过去对哪些物品感兴趣

1、小红书实践
- 把点击、点赞、收藏等不同行为的 最终的多个向量 cancat 起来,作为用户特征
- 在取lastN的时候,不仅会使用物品id,还会使用物品类目,把物品id emb和其他特征的emb拼起来,比只用id emb的效果更好
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2588
2588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









