







机器学习两个重要的过程:学习得到模型和利用模型进行预测。
下面主要总结对比下这两个过程中用到的一些方法。
一,求解无约束的目标优化问题
这类问题往往出现在求解模型,即参数学习的阶段。
我们已经得到了模型的表达式,不过其中包含了一些未知参数。
我们需要求解参数,使模型在某种性质(目标函数)上最大或最小。
最大似然估计:


其中目标函数是对数似然函数。为了求目标函数取最大值时的theta。
有两个关机键步骤,第一个是对目标函数进行求导,第二个是另导数等于0,求解后直接得到最优theta。两个步骤缺一不可。
梯度下降:
对目标函数进行求导,利用导函数提供的梯度信息,使参数往梯度下降最快的方向移动一小步,
来更新参数。为什么不使用最大似然估计的方法来求解呢?
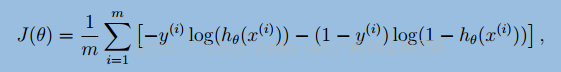
上面是逻辑回归的目标函数,可以看出J(θ)容易进行求导,如下所示:

但是如果通过使偏导数等于0,来求θ是非常困难的。
首先hθ (xi)是关于所有θ的函数,而且h是逻辑回归函数,
其次,每个等式中包含m个hθ (xi)函数。因此只能利用梯度信息,在解空间中进行探索。
EM算法:
和上面一样,也是要求优化一个目标函数。
不同的是,它只能得到目标函数,甚至连目标函数的导函数也求不出来。
如下面的高斯混合模型(GMM)的目标函数函数:

对上面的目标函数求导是非常困难的。
在比如下面的隐马尔科夫模型(HMM)的目标函数:
都是不可以直接求导的,所以需要引入隐变量来简化计算。
好处是:如果我们知道隐变量的值或者概率分布,那么原目标函数可以进行高效的求解(比如可以用最大似然估计法求解)。
通常的步骤是先有参数的先验值和训练数据得到隐变量,再由隐变量和训练数据来最大化目标函数,得到参数。
(个人认为,隐变量可以随便引入,只要能够使原目标函数可以高效求解就行。)
坐标上升或下降(CoordinateAscent):
由先验经验初始化参数。然后每次选择其中一个参数进行优化,其它参数固定(认为是已知变量),如此进行迭代更新。
它和EM的思想差不多,通过引入隐变量(固定的参数),来使得问题变得高效可解。
而引入的隐变量是通过上一次计算的参数得到的(只不过隐变量就等于部分参数本身而已),相当于参数信息落后了一代而已。
k-means和高斯混合模型(GMM)中的EM:
k-means是先由参数和数据得到数据的分类标签,再由数据和分类标签来计算参数。
高斯混合模型中的EM是先由参数和数据得到数据分类标签的概率分布,再由数据和分类标签分布来计算参数。
像k-means这样求隐变量具体值的叫做hard-EM,想GMM这样求隐变量的概率分布的叫做soft-EM。
EM算法收敛性证明:
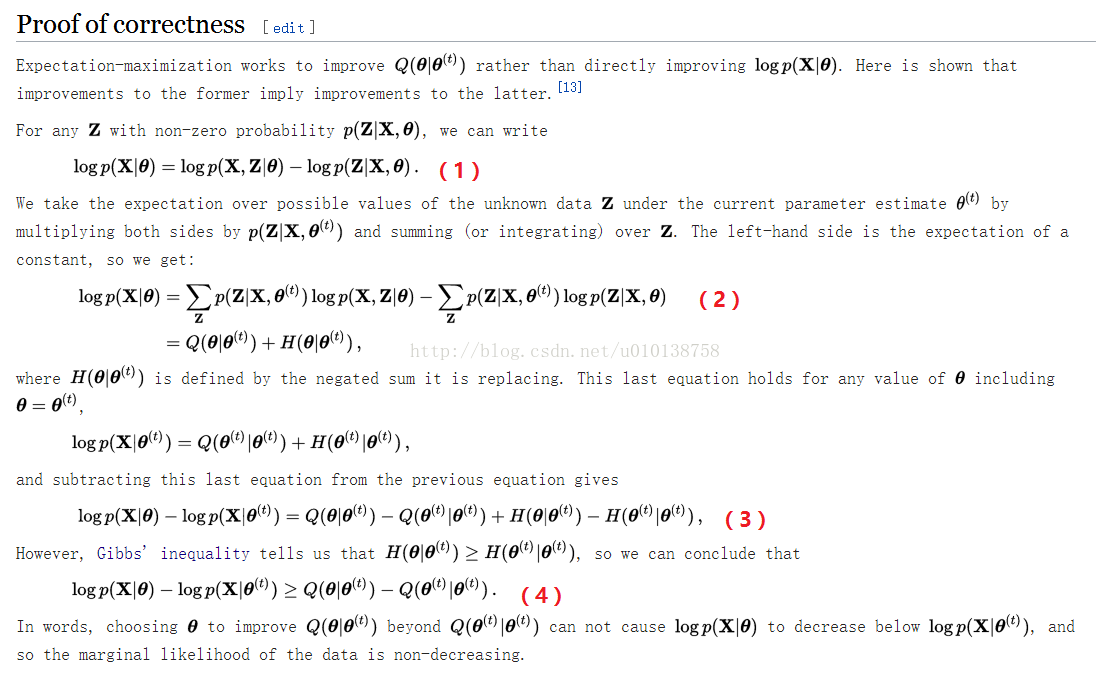
详细说明:


二,求解有约束的目标优化问题


















 432
432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









