






Amount of Information - Formula express of Entropy - KL Divergence - Cross Entropy
Amount of Information
When we are reading papers or news, why not every article is equally important to us. Some give great enlightenment, but some are the old lady’s footwear-smelly and long (老太太的裹脚布,又臭又长。实在不会翻译了), talking nosense. The reason is that their amount of information is different! But how?
It is easy to find that:
The amount of information is only related to the probability of a certain event.
The smaller the probability that something happened, the greater amount of information is indicated, like Yasuo getting penta kill in your team;
The larger the probability, the smaller the amount of information is indicated. For example, my first blog post will be read by many people (it will happen, there is no information).
Fomula express of Entropy
Let’s invent the formula express of Entropy together:
Facing a new concept, we should consider its mathematical properties Additivity, which means
F(event A and B and C…) = F(event A) + F(event B) + F(event C) + …
and as discussed above, Amount of Information only relates to probability, so:
F(p(A, B, C…)) = F(p(A)) + F(p(B)) + F(p(C )) + …
And as we all know, if event A and B are not related, then: p(A, B) = p(A)*p(B)
In addition, Amount of Information should not be negative. We can design:
F(A) = -log(p(A))
As for the choice of base, it is the benchmark that we want to choose. Just like the temperature of 0° and 100° are the melting point of standard pressure ice and the boiling point of water. Theoretically, setting 0° and 100° base on alcohol won’t cause any problem.
In information theory, the base is generally 2, which can be understood as: based on the probability of “tossing a coin with heads up”, it can be calculated as F’(tossing a coin with heads up) = -log(p (tossing a coin with heads up)) . Why take 2? Because the computer is binary, the information transmission is easy to calculate with 2;
In the neural network, e is generally used as the base, nothing else, the derivative is easy to be calculated for gradient decent.
Let’s get down to business, Entropy is defined as: the degree of uncertainty of information, in math, it equal to the expectation of Information Amount, then we get:

Relative Entropy(KL Divergence)
KL Divergence is used to measure the distance between two random events.

In my understanding, KL Divergence is like measure event B from A point of view. Maybe it is more clear in this form:

Cross Entropy
From KL Divergence:

The second part is called Cross Entropy:
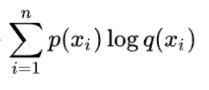
It is widely used in loss function, because p(x) usually means the real distribution of data, which won’t change during training. The second part is what we want to decrease.
本文主要是确保自己明白了,如果我这英语都能说明白,那我是真的明白了。有内容或语法错误欢迎指正!















 2157
2157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









