






因为数据集规模可能会超级大,很难有足够大的内存完全存下所有数据。因此需要一个按需加载样本到内存的数据集类。本文将为一个包含上千万个图样本的数据集构建一个数据集类。
1、Dataset基类简介
在PyG中,通过继承torch_geometric.data.Dataset基类来自定义一个按需加载样本到内存的数据集类。
继承torch_geometric.data.InMemoryDataset基类要实现的方法,继承此基类同样要实现,此外还需要实现以下方法:
len():返回数据集中的样本的数量。
get():实现加载单个图的操作。注意:在内部,getitem ()返回通过调用get()来获取Data对象,并根据transform参数对它们进行选择性转换。
下面让我们通过一个简化的例子看继承torch_geometric.data.Dataset基类的规范:
import os.path as osp
import torch
from torch_geometric.data import Dataset, download_url
class MyOwnDataset(Dataset):
def __init__(self, root, transform=None, pre_transform=None):
super(MyOwnDataset, self).__init__(root, transform, pre_transform)
@property
def raw_file_names(self):
return ['some_file_1', 'some_file_2', ...]
@property
def processed_file_names(self):
return ['data_1.pt', 'data_2.pt', ...]
def download(self):
# Download to `self.raw_dir`.
path = download_url(url, self.raw_dir)
...
def process(self):
i = 0
for raw_path in self.raw_paths:
# Read data from `raw_path`.
data = Data(...)
if self.pre_filter is not None and not self.pre_filter(data):
continue
if self.pre_transform is not None:
data = self.pre_transform(data)
torch.save(data, osp.join(self.processed_dir, 'data_{}.pt'.format(i)))
i += 1
def len(self):
return len(self.processed_file_names)
def get(self, idx):
data = torch.load(osp.join(self.processed_dir, 'data_{}.pt'.format(idx)))
return data
对于无需下载数据集原文件的情况,我们不重写(override)download方法即可跳过下载。对于无需对数据集做预处理的情况,我们不重写process方法即可跳过预处理。
2、图样本封装成批(BATCHING)与DataLoader类
图可以有任意数量的节点和边,它不是规整的数据结构,因此对图数据封装成批的操作与对图像和序列等数据封装成批的操作不同。
PyTorch Geometric中采用的将多个图封装成批的方式是:将小图作为连通组件(connected component)的形式合并,构建一个大图。于是小图的邻接矩阵存储在大图邻接矩阵的对角线上。
此方法有以下关键的优势:
依靠消息传递方案的GNN运算不需要被修改,因为消息仍然不能在属于不同图的两个节点之间交换。
没有额外的计算或内存的开销。例如,这个批处理程序的工作完全不需要对节点或边缘特征进行任何填充。请注意,邻接矩阵没有额外的内存开销,因为它们是以稀疏的方式保存的,只保留非零项,即边。
通过torch_geometric.data.DataLoader类,多个小图被封装成一个大图。 torch_geometric.data.DataLoader是PyTorch的DataLoader的子类,它覆盖了collate()函数,该函数定义了一列表的样本是如何封装成批的。因此,所有可以传递给PyTorch DataLoader的参数也可以传递给PyTorch Geometric的 DataLoader,例如,num_workers。
3、小图的属性增值与拼接
将小图存储到大图中时需要对小图的属性做一些修改,一个最显著的例子就是要对节点序号增值。在最一般的形式中,PyTorch Geometric的DataLoader类会自动对edge_index张量增值,增加的值为当前被处理图的前面的图的累积节点数量。
比方说,现在对第个图的edge_index张量做增值,前面 k-1个图的累积节点数量为n,那么对第k个图的edge_index张量的增值n。增值后,对所有图的edge_index张量(其形状为[2, num_edges])在第二维中连接起来。
然而,有一些特殊的场景中(如下所述),基于需求我们希望能修改这一行为。PyTorch Geom etric 允许我们通过覆盖torch_geometric.data.inc ()和torch_geometric.data. cat_dim ()函数 来实现我们希望的行为。在未做修改的情况下,它们在Data类中的定义如下。
def __inc__(self, key, value):
if 'index' in key or 'face' in key:
return self.num_nodes
else:
return 0
def __cat_dim__(self, key, value):
if 'index' in key or 'face' in key:
return 1
else:
return 0
inc ()定义了两个连续的图的属性之间的增量大小,而__cat_dim__()定义了同一属性的图形张量应该在哪个维度上被连接起来。PyTorch Geometric为存储在Data类中的每个属性调用此二函数,并以它们各自的key和值value作为参数。
如果你想在一个Data对象中存储多个图,例如用于图匹配等应用,我们需要确保所有这些图的正确封装成批行为。例如,考虑将两个图,一个源图G_s和一个目标图G_t,存储在一个Data类中,即
class PairData(Data):
def __init__(self, edge_index_s, x_s, edge_index_t, x_t):
super(PairData, self).__init__()
self.edge_index_s = edge_index_s
self.x_s = x_s
self.edge_index_t = edge_index_t
self.x_t = x_t
在这种情况中,edge_index_s应该根据源图的节点数做增值,即x_s.size(0),而edge_index_t应该根据目标图的节点数做增值,即x_t.size(0)。
class PairData(Data):
def __init__(self, edge_index_s, x_s, edge_index_t, x_t):
super(PairData, self).__init__()
self.edge_index_s = edge_index_s
self.x_s = x_s
self.edge_index_t = edge_index_t
self.x_t = x_t
def __inc__(self, key, value):
if key == 'edge_index_s':
return self.x_s.size(0)
if key == 'edge_index_t':
return self.x_t.size(0)
else:
return super().__inc__(key, value)
我们可以通过设置一个简单的测试脚本来测试我们的PairData批处理行为。
edge_index_s = torch.tensor([
[0, 0, 0, 0],
[1, 2, 3, 4],
])
x_s = torch.randn(5, 16) # 5 nodes.
edge_index_t = torch.tensor([
[0, 0, 0],
[1, 2, 3],
])
x_t = torch.randn(4, 16) # 4 nodes.
data = PairData(edge_index_s, x_s, edge_index_t, x_t)
data_list = [data, data]
loader = DataLoader(data_list, batch_size=2)
batch = next(iter(loader))
print(batch)
# Batch(edge_index_s=[2, 8], x_s=[10, 16], edge_index_t=[2, 6], x_t=[8, 16])
print(batch.edge_index_s)
# tensor([[0, 0, 0, 0, 5, 5, 5, 5], [1, 2, 3, 4, 6, 7, 8, 9]])
print(batch.edge_index_t)
# tensor([[0, 0, 0, 4, 4, 4], [1, 2, 3, 5, 6, 7]])
由于PyTorch Geometric无法识别PairData对象中实际的图,所以batch属性(将大图每个节点映射到其各自对应的小图)没有正确工作。此时就需要DataLoader的follow_batch参数发挥作用。在这里,我们可以指定我们要为哪些属性维护批信息。
loader = DataLoader(data_list, batch_size=2, follow_batch=['x_s', 'x_t'])
batch = next(iter(loader))
print(batch)
# Batch(edge_index_s=[2, 8], x_s=[10, 16], x_s_batch=[10],
edge_index_t=[2, 6], x_t=[8, 16], x_t_batch=[8])
print(batch.x_s_batch)
# tensor([0, 0, 0, 0, 0, 1, 1, 1, 1, 1])
print(batch.x_t_batch)
# tensor([0, 0, 0, 0, 1, 1, 1, 1])
可以看到,follow_batch=['x_s', 'x_t']现在成功地为节点特征x_s'和x_t’分别创建了名为x_s_batch和x_t_batch的赋值向量。这些信息现在可以用来在一个单一的Batch对象中对多个图进行聚合操作,例如,全局池化。
4、二部图(Bipartite Graphs)的节点增值操作
二部图的邻接矩阵可能为平方矩阵,即可能有N 不等于M,因此,对二部图的封装成批过程中,edge_index 中边的源节点与目标节点做的增值操作应是不同的。我们将二部图中两类节点的特征特征张量分别存储为x_s和x_t。
class BipartiteData(Data):
def __init__(self, edge_index, x_s, x_t):
super(BipartiteData, self).__init__()
self.edge_index = edge_index
self.x_s = x_s
self.x_t = x_t
为了对二部图实现正确的封装成批,我们需要告诉PyTorch Geometric,它应该在edge_index 中独立地为边的源节点和目标节点做增值操作。
def __inc__(self, key, value):
if key == 'edge_index':
return torch.tensor([[self.x_s.size(0)], [self.x_t.size(0)]])
else:
return super().__inc__(key, value)
其中,edge_index[0] (边的源节点)根据 x_s.size(0) 做增值运算,而 edge_index[1] (边的目标节点)根据 x_t.size(0) 做增值运算。 我们可以再次通过运行一个简单的测试脚本来测试我们的实现。
edge_index = torch.tensor([
[0, 0, 1, 1],
[0, 1, 1, 2],
])
x_s = torch.randn(2, 16) # 2 nodes.
x_t = torch.randn(3, 16) # 3 nodes.
data = BipartiteData(edge_index, x_s, x_t)
data_list = [data, data]
loader = DataLoader(data_list, batch_size=2)
batch = next(iter(loader))
print(batch)
# Batch(edge_index=[2, 8], x_s=[4, 16], x_t=[6, 16])
print(batch.edge_index)
# tensor([[0, 0, 1, 1, 2, 2, 3, 3], [0, 1, 1, 2, 3, 4, 4, 5]])
可以看到我们得到我们期望的结果。
5、在新的维度上做拼接
有时,Data对象的属性需要在一个新的维度上做拼接(如经典的封装成批),例如,图级别属性或预测目标。具体来说,形状为[num_features]的属性列表应该被返回为[num_examples, num_features],而不是[num_examples * num_features]。PyTorch Geometric通过在__cat_dim__()中返回一个None的连接维度来实现这一点。
class MyData(Data):
def __cat_dim__(self, key, item):
if key == 'foo':
return None
else:
return super().__cat_dim__(key, item)
edge_index = torch.tensor([
[0, 1, 1, 2],
[1, 0, 2, 1],
])
foo = torch.randn(16)
data = MyData(edge_index=edge_index, foo=foo)
data_list = [data, data]
loader = DataLoader(data_list, batch_size=2)
batch = next(iter(loader))
print(batch)
# Batch(edge_index=[2, 8], foo=[2, 16])
正如我们期望的,batch.foo现在由两个维度来表示,一个批维度,一个特征维度。
6、创建超大规模数据集类实践
我们定义的数据集类如下:
import os
import os.path as osp
import pandas as pd
import torch
from ogb.utils import smiles2graph
from ogb.utils.torch_util import replace_numpy_with_torchtensor
from ogb.utils.url import download_url, extract_zip
from rdkit import RDLogger
from torch_geometric.data import Data, Dataset
import shutil
RDLogger.DisableLog('rdApp.*')
class MyPCQM4MDataset(Dataset):
def __init__(self, root):
self.url = 'https://dgl-data.s3-accelerate.amazonaws.com/dataset/OGB-LSC/pcqm4m_kddcup2021.zip'
super(MyPCQM4MDataset, self).__init__(root)
filepath = osp.join(root, 'raw/data.csv.gz')
data_df = pd.read_csv(filepath)
self.smiles_list = data_df['smiles']
self.homolumogap_list = data_df['homolumogap']
@property
def raw_file_names(self):
return 'data.csv.gz'
def download(self):
path = download_url(self.url, self.root)
extract_zip(path, self.root)
os.unlink(path)
shutil.move(osp.join(self.root, 'pcqm4m_kddcup2021/raw/data.csv.gz'), osp.join(self.root, 'raw/data.csv.gz'))
def len(self):
return len(self.smiles_list)
def get(self, idx):
smiles, homolumogap = self.smiles_list[idx], self.homolumogap_list[idx]
graph = smiles2graph(smiles)
assert(len(graph['edge_feat']) == graph['edge_index'].shape[1])
assert(len(graph['node_feat']) == graph['num_nodes'])
x = torch.from_numpy(graph['node_feat']).to(torch.int64)
edge_index = torch.from_numpy(graph['edge_index']).to(torch.int64)
edge_attr = torch.from_numpy(graph['edge_feat']).to(torch.int64)
y = torch.Tensor([homolumogap])
num_nodes = int(graph['num_nodes'])
data = Data(x, edge_index, edge_attr, y, num_nodes=num_nodes)
return data
# 获取数据集划分
def get_idx_split(self):
split_dict = replace_numpy_with_torchtensor(torch.load(osp.join(self.root, 'pcqm4m_kddcup2021/split_dict.pt')))
return split_dict
if __name__ == "__main__":
dataset = MyPCQM4MDataset('dataset2')
from torch_geometric.data import DataLoader
from tqdm import tqdm
dataloader = DataLoader(dataset, batch_size=256, shuffle=True, num_workers=4)
for batch in tqdm(dataloader):
pass
在生成一个该数据集类的对象时,程序首先会检查指定的文件夹下是否存在data.csv.gz文件,如果不在,则会执行download方法,这一过程是在运行super类的__init__方法中发生的。然后程序继续执行__init__方法的剩余部分,读取data.csv.gz文件,获取存储图信息的smiles格式的字符串,以及回归预测的目标homolumogap。
我们将由smiles格式的字符串转成图的过程在get()方法中实现,这样我们在生成一个DataLoader变量时,通过指定num_workers可以实现并行执行生成多个图。
7、实践
非常感谢“天国之影”共享的结果文件,让我们得以看到最终的结果。
自己尝试了很久之后,已经放弃跑图预测任务实践的代码了。
以下用tensorboard预览最终的结果:
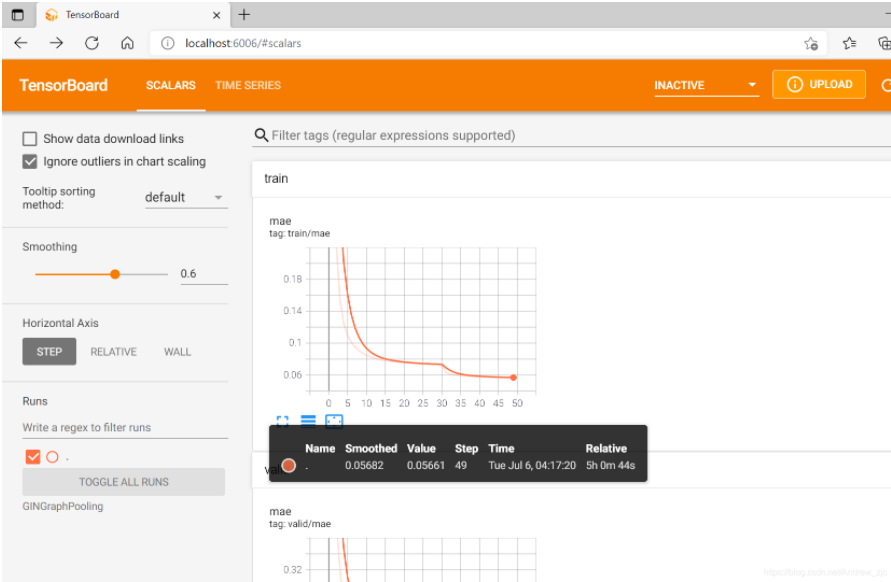
可以从tensorboard里看到训练了五个多小时,最终曲线比较平稳。
参考资料:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









