






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
一、基本卷积神经网络
1. AlexNet
AlexNet网络结构相对简单,使用了8层卷积神经网络,前5层是卷积层,剩下的3层是全连接层,具体如下所示:
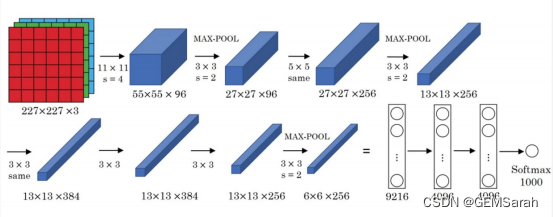
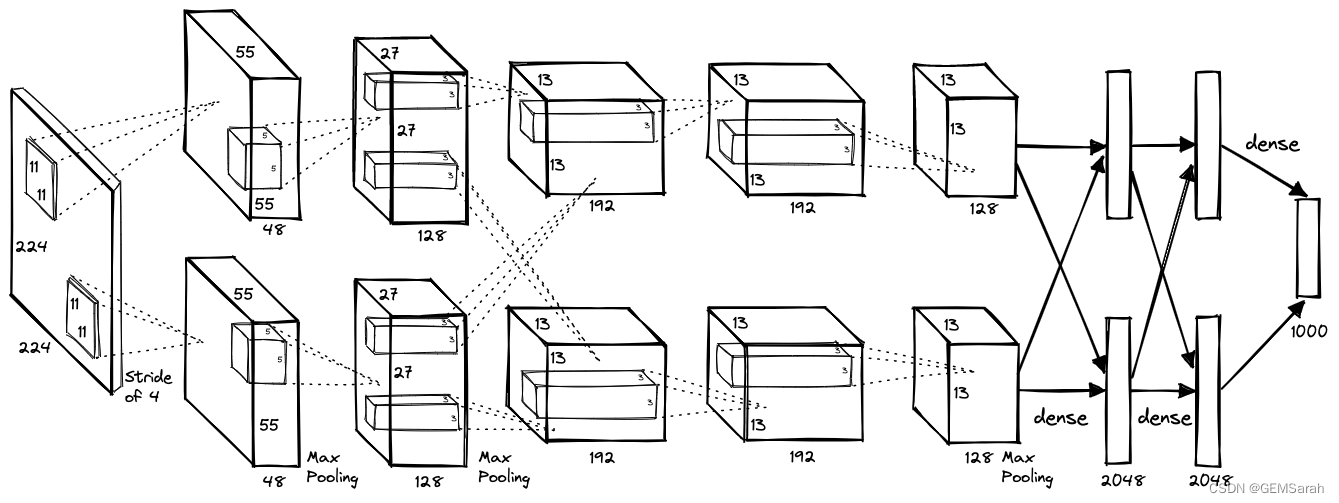
特点: (1) 池化层均采用最大池化; (2) 选用ReLU作为非线性环节激活函数; (3) 网络规模扩大,参数数量接近6000万; (4) 出现“多个卷积层+一个池化层”的结构。
AlexNet代码复现如下:
import time
import torch
from torch import nn, optim
import torchvision
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 96, 11, 4), # in_channels, out_channels, kernel_size, stride, padding
nn.ReLU(),
nn.MaxPool2d(3, 2), # kernel_size, stride
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(3, 2),
# 连续3个卷积层,且使用更小的卷积窗口。除了最后的卷积层外,进一步增大了输出通道数。
# 前两个卷积层后不使用池化层来减小输入的高和宽
nn.Conv2d(256, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(3, 2)
)
# 这里全连接层的输出个数比LeNet中的大数倍。使用丢弃层来缓解过拟合
self.fc = nn.Sequential(
nn.Linear(256*5*5, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(0.5),
# 输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10),
)
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output2. VGG-16
vgg16总共有16层,13个卷积层和3个全连接层,第一次经过64个卷积核的两次卷积后,采用一次pooling,第二次经过两次128个卷积核卷积后,再采用pooling,再重复两次三个512个卷积核卷积后,再pooling,最后经过三次全连接。
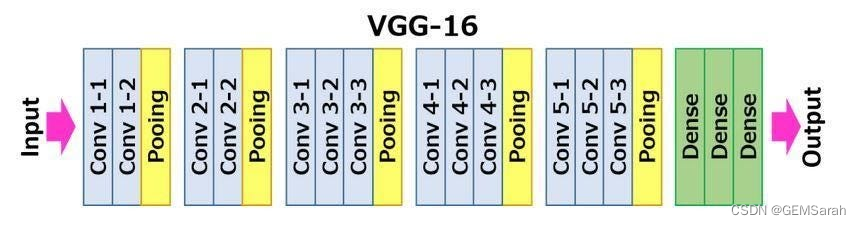
特点: 网络规模进一步增大,参数数量约为1.38亿。由于各卷积层、池化层的超参数基本相同,整体结构呈现出规整的特点。随网络深入,高和宽衰减,通道数增多。代码实现如下所示:
from torch import nn
class Vgg16_net(nn.Module):
def __init__(self):
super(Vgg16_net, self).__init__()
self.layer1=nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=64,kernel_size=3,stride=1,padding=1), #(32-3+2)/1+1=32 32*32*64
nn.BatchNorm2d(64),
#inplace-选择是否进行覆盖运算
#意思是是否将计算得到的值覆盖之前的值,比如
nn.ReLU(inplace=True),
#意思就是对从上层网络Conv2d中传递下来的tensor直接进行修改,
#这样能够节省运算内存,不用多存储其他变量
nn.Conv2d(in_channels=64,out_channels=64,kernel_size=3,stride=1,padding=1), #(32-3+2)/1+1=32 32*32*64
#Batch Normalization强行将数据拉回到均值为0,方差为1的正太分布上,
# 一方面使得数据分布一致,另一方面避免梯度消失。
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2,stride=2) #(32-2)/2+1=16 16*16*64
)
self.layer2=nn.Sequential(
nn.Conv2d(in_channels=64,out_channels=128,kernel_size=3,stride=1,padding=1), #(16-3+2)/1+1=16 16*16*128
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=128,out_channels=128,kernel_size=3,stride=1,padding=1), #(16-3+2)/1+1=16 16*16*128
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.MaxPool2d(2,2) #(16-2)/2+1=8 8*8*128
)
self.layer3=nn.Sequential(
nn.Conv2d(in_channels=128,out_channels=256,kernel_size=3,stride=1,padding=1), #(8-3+2)/1+1=8 8*8*256
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=256,out_channels=256,kernel_size=3,stride=1,padding=1), #(8-3+2)/1+1=8 8*8*256
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=256,out_channels=256,kernel_size=3,stride=1,padding=1), #(8-3+2)/1+1=8 8*8*256
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.MaxPool2d(2,2) #(8-2)/2+1=4 4*4*256
)
self.layer4=nn.Sequential(
nn.Conv2d(in_channels=256,out_channels=512,kernel_size=3,stride=1,padding=1), #(4-3+2)/1+1=4 4*4*512
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512,out_channels=512,kernel_size=3,stride=1,padding=1), #(4-3+2)/1+1=4 4*4*512
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512,out_channels=512,kernel_size=3,stride=1,padding=1), #(4-3+2)/1+1=4 4*4*512
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.MaxPool2d(2,2) #(4-2)/2+1=2 2*2*512
)
self.layer5=nn.Sequential(
nn.Conv2d(in_channels=512,out_channels=512,kernel_size=3,stride=1,padding=1), #(2-3+2)/1+1=2 2*2*512
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512,out_channels=512,kernel_size=3,stride=1,padding=1), #(2-3+2)/1+1=2 2*2*512
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512,out_channels=512,kernel_size=3,stride=1,padding=1), #(2-3+2)/1+1=2 2*2*512
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.MaxPool2d(2,2) #(2-2)/2+1=1 1*1*512
)
self.conv=nn.Sequential(
self.layer1,
self.layer2,
self.layer3,
self.layer4,
self.layer5
)
self.fc=nn.Sequential(
#y=xA^T+b x是输入,A是权值,b是偏执,y是输出
#nn.Liner(in_features,out_features,bias)
#in_features:输入x的列数 输入数据:[batchsize,in_features]
#out_freatures:线性变换后输出的y的列数,输出数据的大小是:[batchsize,out_features]
#bias: bool 默认为True
#线性变换不改变输入矩阵x的行数,仅改变列数
nn.Linear(512,512),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(512,256),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(256,10)
)
def forward(self,x):
x=self.conv(x)
#这里-1表示一个不确定的数,就是你如果不确定你想要reshape成几行,但是你很肯定要reshape成512列
# 那不确定的地方就可以写成-1
#如果出现x.size(0)表示的是batchsize的值
# x=x.view(x.size(0),-1)
x = x.view(-1, 512)
x=self.fc(x)
return x3. 残差网络
在VGG中,卷积网络达到了19层,在GoogLeNet中,网络史无前例的达到了22层。那么,网络的精度会随着网络的层数增多而增多吗?在深度学习中,网络层数增多一般会伴着下面几个问题:计算资源的消耗;模型容易过拟合;梯度消失/梯度爆炸问题的产生;因此残差网络被提出以解决此类问题。
残差网络是由一系列残差块组成。残差网络的搭建分为两步:1. 使用VGG公式搭建Plain VGG网络;2. 在Plain VGG的卷积网络之间插入Identity Mapping,注意需要升维或者降维的时候加入 1×1 卷积。详细介绍可参考:http://t.csdn.cn/sBUTh
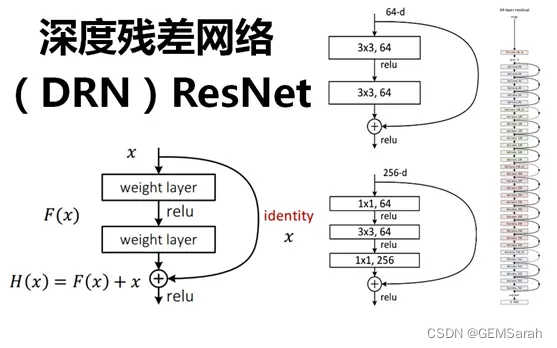
二、常用数据集与评价指标
1. 数据集
在卷积神经网络训练中,比较经典且常用的数据集包括: MNIST, Fashion-MNIST, PASCAL VOC, MS COCO, 和ImageNet等.




2. 评价指标
<1> 算法评估相关概念(TP, FP, FN, TN)

<2> P-R曲线

<3> 置信度与准确率

可以通过改变阈值(也可以看作上下移动蓝色的虚线),来选择让系统识别能出多少个图片,当然阈值的变化会导致Precision与Recall值发生变化。比如,把蓝色虚线放到第一张图片下面,也就是说让系统只识别出最上面的那张飞机图片,那么Precision的值就是100%,而Recall的值则是20%。如果把蓝色虚线放到第二张图片下面,也就是说让系统只识别出最上面的前两张图片,那么Precision的值还是100%,而Recall的值则增长到是40%。
<4> AP计算


三、目标检测+YOLO (1)
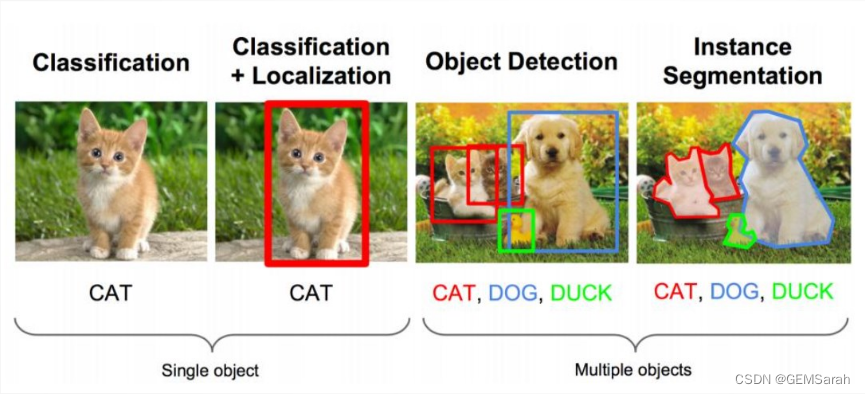
1. 目标检测问题
目标检测是在给定的图片中精确找到物体所在位置,并标注出物体的类别。物体的尺寸变化范围很大,摆放物体的角度,姿态不定,而且可以出现在图片的任何地方,并且物体还可以是多个类别。
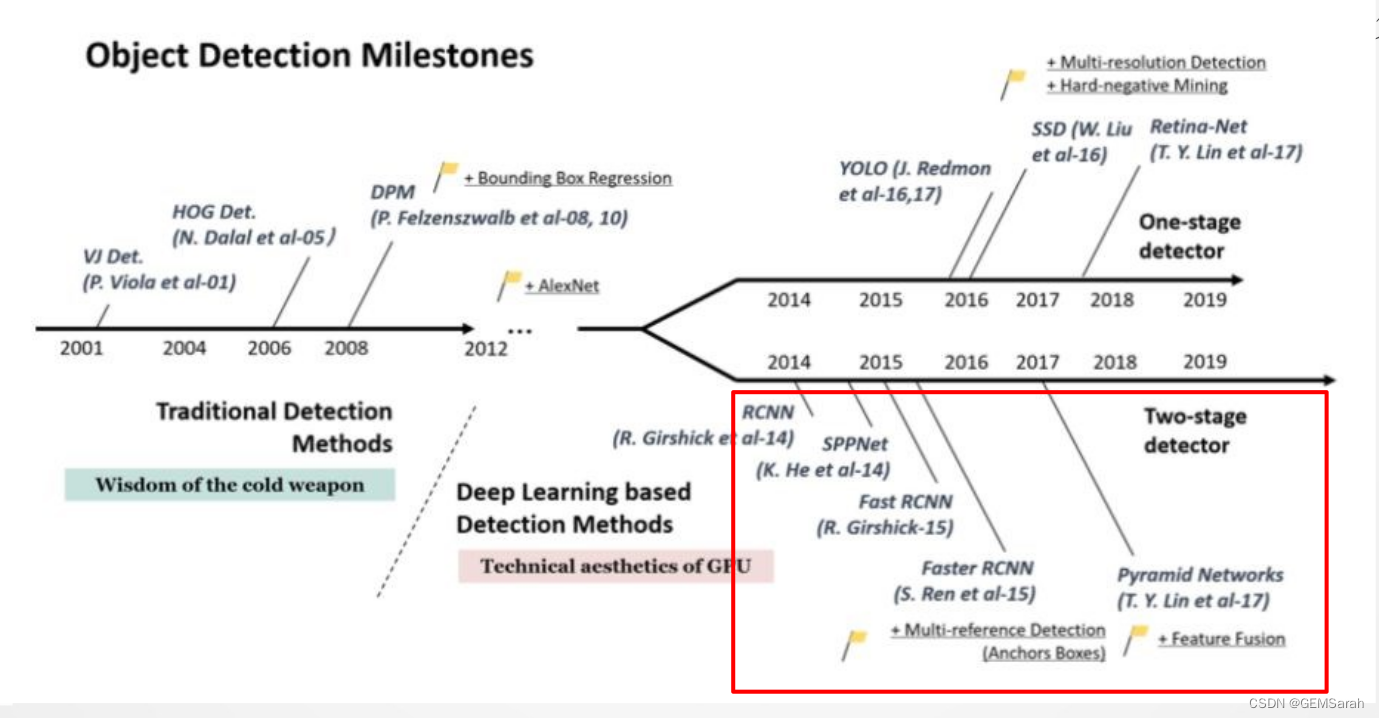
2. 目标检测技术发展
3. 目标检测基本思想
基本的滑动窗口: 采用滑动窗口的目标检测算法思路非常简单,它将的基本原理就是采用不同大小和比例 (宽高比) 的窗口在整张图片上以设定的步长进行滑动,遍历图片的所有位置, 然后对这些窗口对应的区域做图像分类,这样就可以实现对整张图片的检测了。
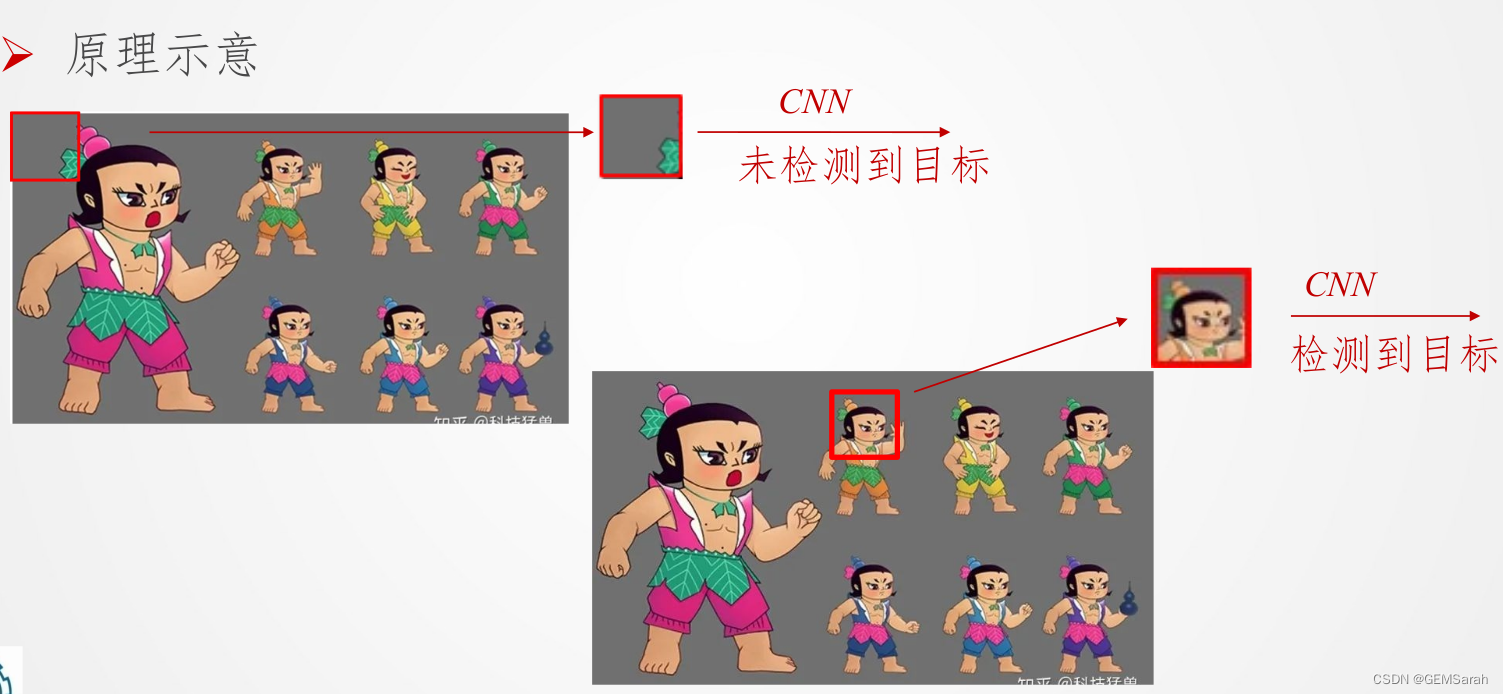
一步法基本思想: 分类问题扩展为回归+分类问题。目标检测|YOLO系列 - 知乎
4. YOLO网络结构
<1> YOLO网络结构概略图
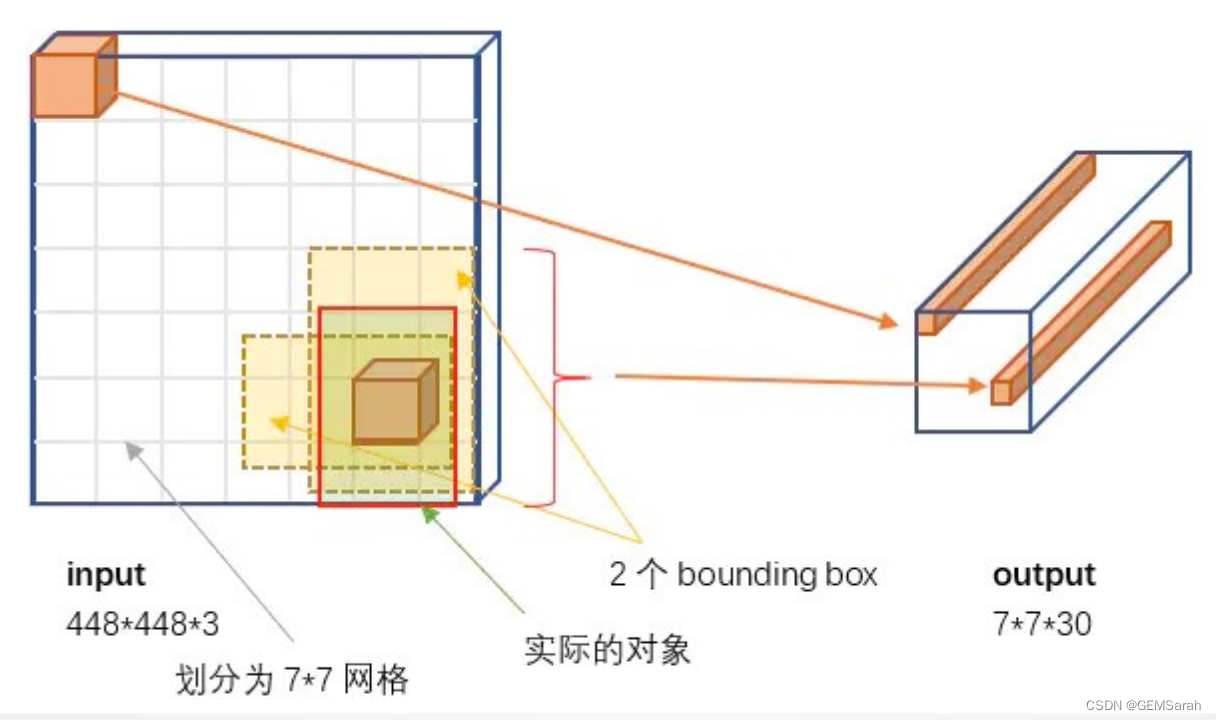
<2> YOLO官方的模型结构图
YOLO网络结构包含24个卷积层和2个全连接层;其中前20个卷积层用来做预训练,后面4个是随机初始化的卷积层,和2个全连接层。
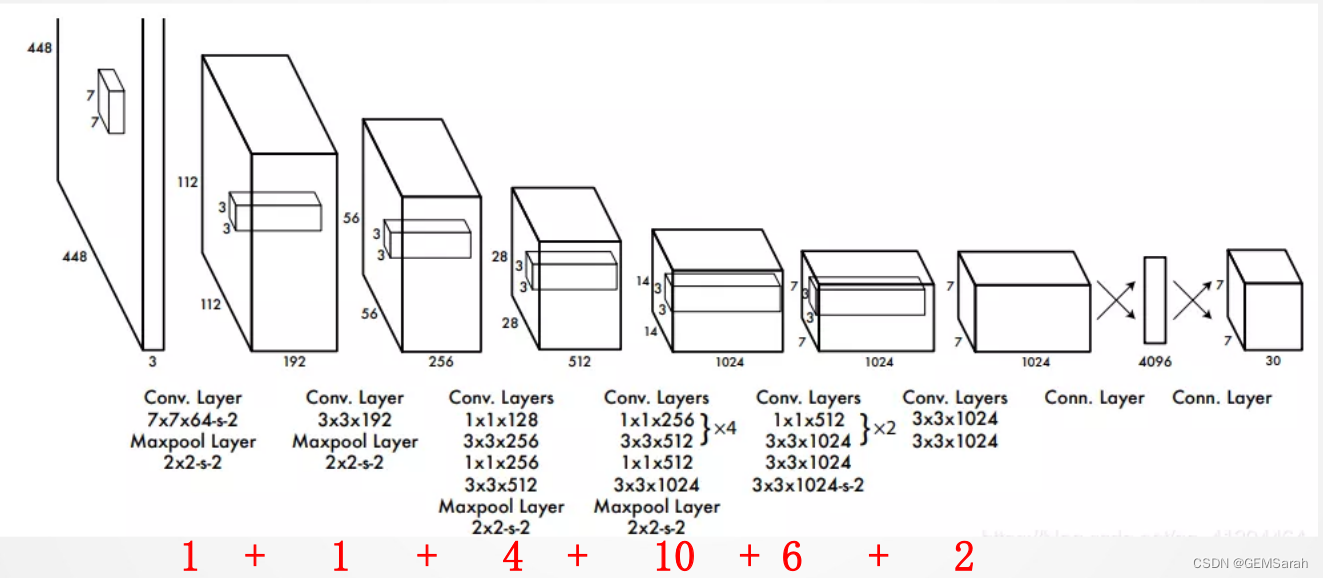
YOLO的结构非常简单,就是单纯的卷积、池化最后加了两层全连接,从网络结构上看,与前面介绍的CNN分类网络没有本质的区别,最大的差异是输出层用线性函数做激活函数,因为需要预测bounding box的位置(数值型),而不仅仅是对象的概率。所以粗略来说,YOLO的整个结构就是输入图片经过神经网络的变换得到一个输出的张量,如下图所示:
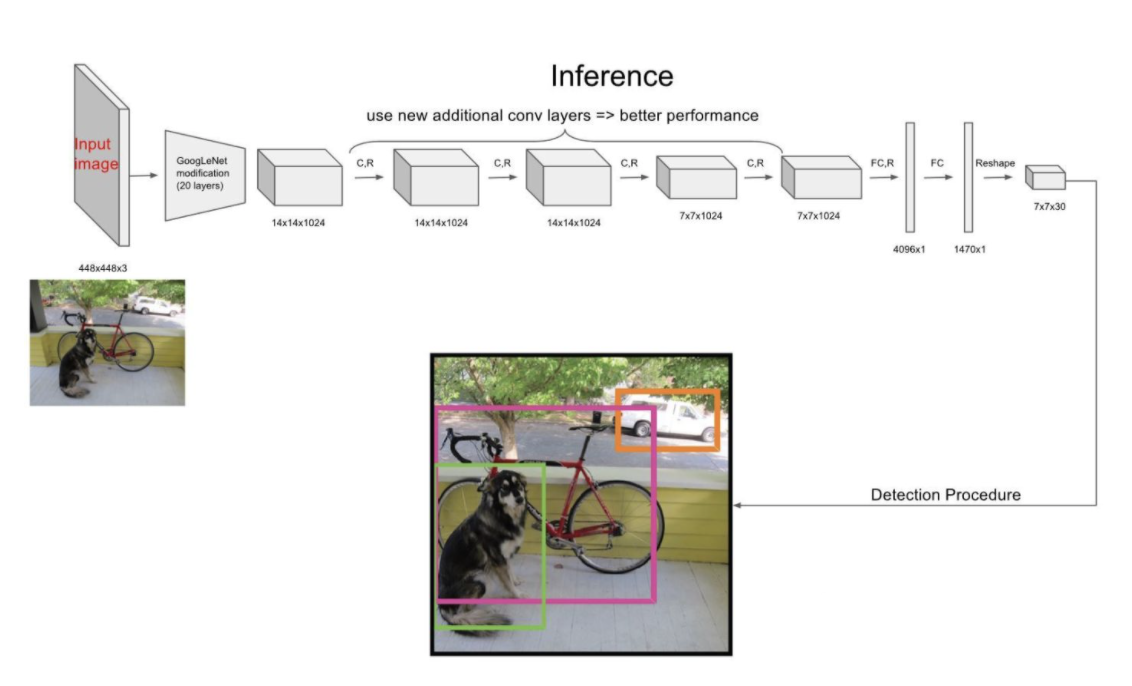
更多详细解释可参考什么是yolo?Yolo算法的网络结构
总结
以上就是今天要讲的内容,本文继上周内容简单介绍了基本卷积神经网络AlexNet, VGG-16和残差网络,并了解了TP, FP, FN, TN,P-R曲线,AP计算等算法评估方法。此外,又开始初步学习目标检测问题及YOLO网络结构。















 1496
1496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









