







 本文详细介绍了DiffusionModel的工作原理,包括前向过程如何逐步将图像加噪至纯高斯噪声,以及反向过程如何通过神经网络预测噪声来恢复图像。关键在于理解前向过程中的加噪分布和反向过程中的贝叶斯公式应用,以及如何通过重参数化技巧推导出反向过程的分布。文章还探讨了模型参数如β_t和α_t的作用,以及如何通过深度学习网络预测噪声以实现图像还原。
本文详细介绍了DiffusionModel的工作原理,包括前向过程如何逐步将图像加噪至纯高斯噪声,以及反向过程如何通过神经网络预测噪声来恢复图像。关键在于理解前向过程中的加噪分布和反向过程中的贝叶斯公式应用,以及如何通过重参数化技巧推导出反向过程的分布。文章还探讨了模型参数如β_t和α_t的作用,以及如何通过深度学习网络预测噪声以实现图像还原。
前言
本文一共分为三大部分,这是第一部分
Diffusion model(一): 公式推导详解
Diffusion model(二): 训练推导详解
Diffusion model(三): 公式结论
首先附上几个大佬的讲解
lilianweng-diffusion-models
zhihu_由浅入深了解Diffusion Model
b站_diffusion model 原理讲解
b站_基于 pytorch 动手实现 diffusion model
DDPM论文_NIPS_2020
这篇博客借鉴了上述博客、视频以及DDPM论文,同时加上个人的理解整合了一下,尽可能让整个推导详细,希望能使每个人都看懂
结合之前讲过的VAE和GAN模型,Diffusion Model和他们的区别就是latent code和原图是同尺寸大小的。如下图所示,给大家一个直观的认识:Diffusion Model分为前向过程和反向过程,前向过程将输入图片 x 0 x_{0} x0变为纯高斯噪声 x T x_{T} xT(就是一个不断加噪的过程),反向过程就是将噪声 x T x_{T} xT还原为图片 x 0 x_{0} x0的过程(就是一个不断去噪的过程)

知道Diffusion Model在做什么之后,接下来对Diffusion的前向和反向过程做分析推导
Diffusion的前向过程
1. 前向过程从 x t − 1 x_{t-1} xt−1到 x t x_{t} xt的公式
给定真实图片
x
0
∼
q
(
x
)
x_{0} \sim q(x)
x0∼q(x),前向过程中diffusion model对其添加了
T
T
T次高斯噪声,分别得到图
x
1
,
x
2
,
x
3
,
.
.
.
,
x
T
x_{1},x_{2},x_{3},...,x_{T}
x1,x2,x3,...,xT(随着
t
t
t的增加,
x
x
x包含越来越多的噪声),这个过程如下表示
q
(
x
t
∣
x
t
−
1
)
=
N
(
x
t
;
1
−
β
t
x
t
−
1
,
β
t
I
)
(1)
q(x_{t}|x_{t-1}) = \mathcal{N}(x_{t}; \sqrt{1-\beta_{t}}x_{t-1}, \beta_{t}I) \tag{1}
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)(1)
下图展示了前向加噪的过程中图片的变化,从左到右为 x 0 , x 1 , . . . , x T x_{0}, x_{1}, ..., x_{T} x0,x1,...,xT

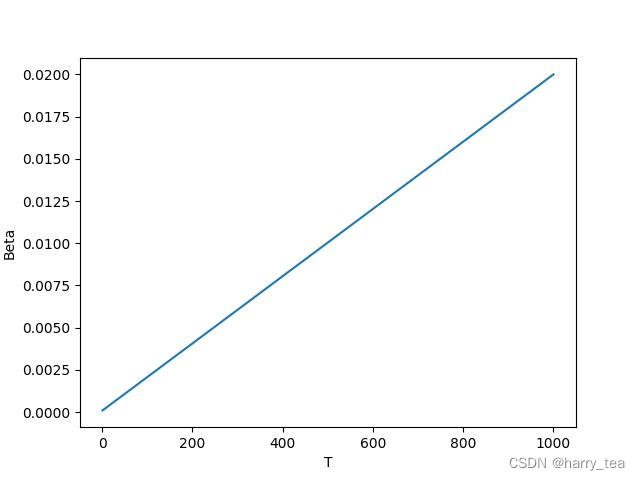
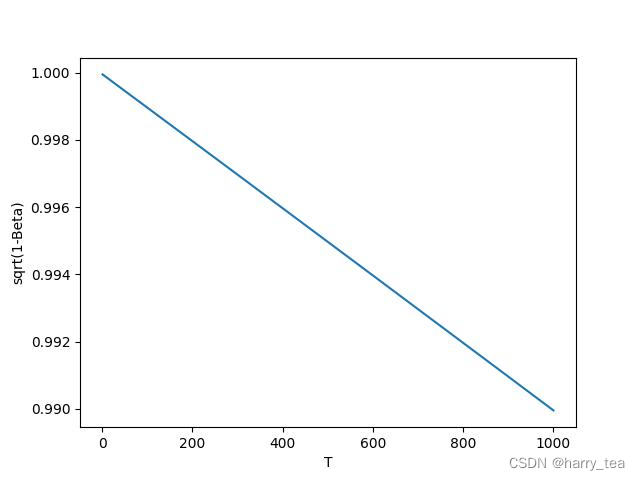
整个前向加噪过程是马尔科夫过程,即 t t t时刻的状态只与 t − 1 t-1 t−1时刻有关,在不断加噪的过程中, x t x_{t} xt不断接近纯噪声, T → ∞ T\rightarrow \infty T→∞, x t x_{t} xt变为正态分布的高斯噪声(为什么下面会讲),在论文中 β t \beta_{t} βt是从0.0001到0.02线性插值的,取 T = 1000 T=1000 T=1000,也就是说 β t \beta_{t} βt是不断增加的, 1 − β t 1-\beta_{t} 1−βt是不断减小的
回过头来再看上述分布 N ( x t ; 1 − β t x t − 1 , β t I ) \mathcal{N}(x_{t}; \sqrt{1-\beta_{t}}x_{t-1}, \beta_{t}I) N(xt;1−βtxt−1,βtI),随着 t t t增加, x t x_{t} xt的均值是 x t − 1 x_{t-1} xt−1的 1 − β t < 1 \sqrt{1-\beta_{t}} <1 1−βt<1倍,因此最终 x t x_{t} xt的均值不断变小,趋近于 0 0 0,而标准正态分布的均值也为0
下面是 β t \beta_{t} βt和 1 − β t \sqrt{1-\beta_{t}} 1−βt随着 T T T增加的变化曲线
 |  |
2. 怎么从 x 0 x_{0} x0直接得到 x t x_{t} xt的表达式?
前向过程的 T T T最多为1000次,如果每次都单独计算过于耗时,这里推导能够一步到位的方式
为了推导方便,原论文令
α
t
=
1
−
β
t
\alpha_{t} = 1-\beta_{t}
αt=1−βt,
α
‾
t
=
∏
i
=
1
T
α
i
\overline{\alpha}_{t} = \prod_{i=1}^{T}\alpha_{i}
αt=∏i=1Tαi,并用重参数化的方法来表示前向过程每一步的数据分布(重参数化方法在文末有介绍),这里我们由
q
(
x
t
∣
x
t
−
1
)
q(x_{t}|x_{t-1})
q(xt∣xt−1)得
x
t
=
1
−
β
t
x
t
−
1
+
β
t
z
1
,
w
h
e
r
e
z
1
,
z
2
,
.
.
.
,
∼
N
(
0
,
I
)
=
α
t
x
t
−
1
+
1
−
α
t
z
1
=
α
t
(
α
t
−
1
x
t
−
2
+
1
−
α
t
−
1
z
2
)
+
1
−
α
t
z
1
=
α
t
α
t
−
1
x
t
−
2
+
α
t
1
−
α
t
−
1
z
2
+
1
−
α
t
z
1
=
α
t
α
t
−
1
x
t
−
2
+
1
−
α
t
α
t
−
1
z
‾
2
,
z
‾
2
∼
N
(
0
,
I
)
=
.
.
.
=
α
t
α
t
−
1
.
.
.
α
1
x
0
+
1
−
α
t
α
t
−
1
.
.
.
α
0
z
‾
t
=
α
‾
t
x
0
+
1
−
α
‾
t
z
‾
t
(2)
\begin{aligned} x_{t} &= \sqrt{1-\beta_{t}}x_{t-1} + \sqrt{\beta_{t}}z_{1}, ~~~~ where~z_{1},z_{2},...,\sim \mathcal{N}(0, I) \\ &= \sqrt{\alpha_{t}}x_{t-1} + \sqrt{1-\alpha_{t}}z_{1} \\ &= \sqrt{\alpha_{t}}(\sqrt{\alpha_{t-1}}x_{t-2} + \sqrt{1-\alpha_{t-1}}z_{2}) + \sqrt{1-\alpha_{t}}z_{1} \\ &= \sqrt{\alpha_{t}\alpha_{t-1}}x_{t-2} + {\color{red}\sqrt{\alpha_{t}}\sqrt{1-\alpha_{t-1}}z_{2} + \sqrt{1-\alpha_{t}}z_{1}} \\ &= \sqrt{\alpha_{t}\alpha_{t-1}}x_{t-2} + {\color{red}\sqrt{1-\alpha_{t}\alpha_{t-1}}\overline{z}_{2}}, ~~~~ \overline{z}_{2}\sim \mathcal{N}(0, I) \\ &= ... \\ &= \sqrt{\alpha_{t}\alpha_{t-1}...\alpha_{1}}x_{0} + \sqrt{1-\alpha_{t}\alpha_{t-1}...\alpha_{0}}\overline{z}_{t} \\ &= \sqrt{\overline{\alpha}_{t}}x_{0} + \sqrt{1-\overline{\alpha}_{t}}\overline{z}_{t} \end{aligned} \tag{2}
xt=1−βtxt−1+βtz1, where z1,z2,...,∼N(0,I)=αtxt−1+1−αtz1=αt(αt−1xt−2+1−αt−1z2)+1−αtz1=αtαt−1xt−2+αt1−αt−1z2+1−αtz1=αtαt−1xt−2+1−αtαt−1z2, z2∼N(0,I)=...=αtαt−1...α1x0+1−αtαt−1...α0zt=αtx0+1−αtzt(2)
公式解释部分,上述公式懂的话可以不看
其中公式的红色部分用到了高斯分布的独立可加性,即 N ( 0 , σ 1 2 I ) + N ( 0 , σ 2 2 I ) ∼ N ( 0 , ( σ 1 2 + σ 2 2 ) I ) \mathcal{N}(0, \sigma^{2}_{1}I) + \mathcal{N}(0, \sigma^{2}_{2}I) \sim \mathcal{N}(0, (\sigma^{2}_{1}+\sigma^{2}_{2})I) N(0,σ12I)+N(0,σ22I)∼N(0,(σ12+σ22)I)
由
α t ( 1 − α t − 1 ) z 2 ∼ N ( 0 , α t ( 1 − α t − 1 ) I ) 1 − α t z 1 ∼ N ( 0 , ( 1 − α t − 1 ) I ) \begin{aligned} & \sqrt{\alpha_{t}(1-\alpha_{t-1})}z_{2} \sim \mathcal{N}(0, \alpha_{t}(1-\alpha_{t-1})I) \\ & \sqrt{1-\alpha_{t}}z_{1} \sim \mathcal{N}(0, (1-\alpha_{t-1})I) \end{aligned} αt(1−αt−1)z2∼N(0,αt(1−αt−1)I)1−αtz1∼N(0,(1−αt−1)I)
可得
α t ( 1 − α t − 1 ) z 2 + 1 − α t z 1 ∼ N ( 0 , ( 1 − α t α t − 1 ) I ) → 1 − α t α t − 1 z ‾ 2 \sqrt{\alpha_{t}(1-\alpha_{t-1})}z_{2} + \sqrt{1-\alpha_{t}}z_{1} \sim \mathcal{N}(0, (1-\alpha_{t}\alpha_{t-1})I) \rightarrow \sqrt{1-\alpha_{t}\alpha_{t-1}}\overline{z}_{2} αt(1−αt−1)z2+1−αtz1∼N(0,(1−αtαt−1)I)→1−αtαt−1z2
x t x_{t} xt的最终结果为 x t = α ‾ t x 0 + 1 − α ‾ t z ‾ t x_{t}=\sqrt{\overline{\alpha}_{t}}x_{0} + \sqrt{1-\overline{\alpha}_{t}}\overline{z}_{t} xt=αtx0+1−αtzt,其中 α ‾ t = ∏ i = 1 T α i \overline{\alpha}_{t} = \prod_{i=1}^{T}\alpha_{i} αt=∏i=1Tαi在 T T T次连乘之后接近于 0 0 0,即 x t = 0 × x 0 + 1 − 0 z ‾ t = z ‾ t x_{t} = 0\times x_{0} + \sqrt{1-0}\overline{z}_{t} = \overline{z}_{t} xt=0×x0+1−0zt=zt,即 N ( 0 , I ) \mathcal{N}(0, I) N(0,I)的正态分布,这就是整个前向推导了
3. 关于 x t − 1 x_{t-1} xt−1到 x t x_{t} xt的一个疑问
为什么 x t x_{t} xt的分布是 q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q(x_{t}|x_{t-1}) = \mathcal{N}(x_{t}; \sqrt{1-\beta_{t}}x_{t-1}, \beta_{t}I) q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)呢?因为这个公式是作者直接给出的,并没有一个推导,公式表明在加噪的过程中均值要乘上 1 − β t \sqrt{1-\beta_{t}} 1−βt,如果要保证均值最后为0的话,只需要每次乘的值小于1就可以了(虽然方差可能并不是 I I I),通过上述推导我们可以发现 x t x_{t} xt的最终等于 α ‾ t x 0 + 1 − α ‾ t z ‾ t \sqrt{\overline{\alpha}_{t}}x_{0} + \sqrt{1-\overline{\alpha}_{t}}\overline{z}_{t} αtx0+1−αtzt,即 T → ∞ , x t ∼ N ( 0 , I ) T \rightarrow \infty, x_{t} \sim \mathcal{N}(0, I) T→∞,xt∼N(0,I),也就是说 N ( x t ; 1 − β t x t − 1 , β t I ) \mathcal{N}(x_{t}; \sqrt{1-\beta_{t}}x_{t-1}, \beta_{t}I) N(xt;1−βtxt−1,βtI)这个分布能够保证 x t x_{t} xt最终收敛为标准高斯分布,但是具体前向分布这个式子怎么得到的,我不是很懂
Diffusion的反向过程
1. 反向过程的理想目标:已知 x t x_{t} xt,预测 x t − 1 x_{t-1} xt−1
在前向加噪过程中,表达式为
q
(
x
t
∣
x
t
−
1
)
=
N
(
x
t
;
1
−
β
t
x
t
−
1
,
β
t
I
)
q(x_{t}|x_{t-1}) = \mathcal{N}(x_{t}; \sqrt{1-\beta_{t}}x_{t-1}, \beta_{t}I)
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI),反向过程就是将上述过程进行逆转,得到
q
(
x
t
−
1
∣
x
t
)
q(x_{t-1}|x_{t})
q(xt−1∣xt)的分布,通过不断的去噪从
x
T
∼
N
(
0
,
I
)
x_{T} \sim \mathcal{N}(0, I)
xT∼N(0,I)中还原出原图
x
0
x_{0}
x0,文中证明了如果
q
(
x
t
∣
x
t
−
1
)
q(x_{t}|x_{t-1})
q(xt∣xt−1)满足高斯分布并且
β
t
\beta_{t}
βt足够小,
q
(
x
t
−
1
∣
x
t
)
q(x_{t-1}|x_{t})
q(xt−1∣xt)仍然是一个高斯分布。但是我们无法简单推断
q
(
x
t
−
1
∣
x
t
)
q(x_{t-1}|x_{t})
q(xt−1∣xt),因此我们使用深度学习模型(参数为
θ
\theta
θ,结构一般为U-net+attention结构)来预测他的真实分布
p
θ
(
x
t
−
1
∣
x
t
)
=
N
(
x
t
−
1
;
μ
θ
(
x
t
,
t
)
,
Σ
θ
(
x
t
,
t
)
)
(3)
p_{\theta}({x_{t-1}|x_{t}}) = \mathcal{N}(x_{t-1}; \mu_{\theta}(x_{t}, t), \Sigma_{\theta}(x_{t}, t)) \tag{3}
pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))(3)
( 3 ) (3) (3)式是我们要通过神经网络预测diffusion model反向过程的式子:已知 x t x_{t} xt以及加噪次数 t t t的情况下,推导 x t − 1 x_{t-1} xt−1,这个过程十分复杂,因为我们有无数的去噪可能性,即使最终得到了 x 0 x_{0} x0,也无法确定 x 0 x_{0} x0是否真的属于 q ( x ) q(x) q(x)这个分布中的数据,因此需要对去噪过程加以限制,即让其去噪后的图片收敛到 q ( x ) q(x) q(x)分布中
2. 额外已知 x 0 x_{0} x0的情况下的反向过程
对于反向过程的分布
q
(
x
t
−
1
∣
x
t
)
q(x_{t-1}|x_{t})
q(xt−1∣xt)我们无法预测,但是从前向过程中我们知道
x
0
x_{0}
x0,所以通过贝叶斯公式得到
q
(
x
t
−
1
∣
x
t
,
x
0
)
q(x_{t-1}|x_{t}, x_{0})
q(xt−1∣xt,x0)为
q
(
x
t
−
1
∣
x
t
,
x
0
)
=
(
x
t
−
1
;
μ
~
(
x
t
,
x
0
)
,
β
~
t
I
)
(4)
q(x_{t-1}|x_{t}, x_{0}) = \mathcal(x_{t-1}; \tilde{\mu}(x_{t}, x_{0}), \tilde{\beta}_{t}I) \tag{4}
q(xt−1∣xt,x0)=(xt−1;μ~(xt,x0),β~tI)(4)
推导过程如下,首先利用贝叶斯公式将反向过程均变为前向过程
x
t
−
1
→
x
t
x_{t-1} \rightarrow x_{t}
xt−1→xt,
x
0
→
x
t
−
1
x_{0}\rightarrow x_{t-1}
x0→xt−1以及
x
0
→
x
t
x_{0}\rightarrow x_{t}
x0→xt
q
(
x
t
−
1
∣
x
t
,
x
0
)
=
q
(
x
t
∣
x
t
−
1
,
x
0
)
q
(
x
t
−
1
∣
x
0
)
q
(
x
t
∣
x
0
)
(5)
q(x_{t-1}|x_{t}, x_{0}) = q(x_{t}|x_{t-1}, x_{0}) \frac{q(x_{t-1}|x_{0})}{q(x_{t}|x_{0})} \tag{5}
q(xt−1∣xt,x0)=q(xt∣xt−1,x0)q(xt∣x0)q(xt−1∣x0)(5)
根据高斯分布的概率密度函数的指数部分
(
μ
,
σ
2
)
∝
exp
(
−
(
x
−
μ
)
2
2
σ
2
)
(\mu, \sigma^{2}) \propto \exp(-\frac{(x-\mu)^2}{2\sigma^{2}})
(μ,σ2)∝exp(−2σ2(x−μ)2)以及前向推导公式
x
t
=
α
t
x
t
−
1
+
1
−
α
t
z
1
x_{t} = \sqrt{\alpha_{t}}x_{t-1} + \sqrt{1-\alpha_{t}}z_{1}
xt=αtxt−1+1−αtz1和
x
t
=
α
‾
t
x
0
+
1
−
α
‾
t
z
‾
t
x_{t} = \sqrt{\overline{\alpha}_{t}}x_{0} + \sqrt{1-\overline{\alpha}_{t}}\overline{z}_{t}
xt=αtx0+1−αtzt得
q
(
x
t
−
1
∣
x
t
,
x
0
)
=
q
(
x
t
∣
x
t
−
1
,
x
0
)
q
(
x
t
−
1
∣
x
0
)
1
q
(
x
t
∣
x
0
)
=
[
α
t
x
t
−
1
+
1
−
α
t
z
1
]
×
[
α
‾
t
−
1
x
0
+
1
−
α
‾
t
−
1
z
‾
t
−
1
]
×
[
1
α
‾
t
x
0
+
1
−
α
‾
t
z
‾
t
]
∝
exp
(
−
1
2
(
(
x
t
−
α
t
x
t
−
1
)
2
β
t
+
(
x
t
−
1
−
α
‾
t
−
1
x
0
)
2
1
−
α
‾
t
−
1
−
(
x
t
−
α
‾
t
x
0
)
2
1
−
α
‾
t
)
)
=
exp
(
−
1
2
(
(
α
t
β
t
+
1
1
−
α
‾
t
−
1
)
x
t
−
1
2
⏟
−
(
2
α
t
β
t
x
t
+
2
α
‾
t
−
1
1
−
α
‾
t
−
1
x
0
)
x
t
−
1
⏟
+
C
(
x
t
,
x
0
⏟
)
)
)
(6)
\begin{aligned} q(x_{t-1}|x_{t}, x_{0}) &= q(x_{t}|x_{t-1}, x_{0}) q(x_{t-1}|x_{0}) \frac{1}{q(x_{t}|x_{0})} \\ &= [\sqrt{\alpha_{t}}x_{t-1} + \sqrt{1-\alpha_{t}}z_{1}] \times [\sqrt{\overline{\alpha}_{t-1}}x_{0} + \sqrt{1-\overline{\alpha}_{t-1}}\overline{z}_{t-1}] \times [\frac{1}{\sqrt{\overline{\alpha}_{t}}x_{0} + \sqrt{1-\overline{\alpha}_{t}}\overline{z}_{t}}] \\ &\propto \exp(-\frac{1}{2}(\frac{(x_{t} - \sqrt{\alpha_{t}}x_{t-1})^2}{\beta_{t}} + \frac{(x_{t-1}-\sqrt{\overline{\alpha}_{t-1}}x_{0})^{2}}{1-\overline{\alpha}_{t-1}} - \frac{(x_{t}-\sqrt{\overline{\alpha}_{t}}x_{0})^{2}}{1-\overline{\alpha}_{t}})) \\ &= \exp(-\frac{1}{2}(( \underbrace{\frac{\alpha_{t}}{\beta_{t}}+\frac{1}{1-\overline{\alpha}_{t-1}})x^{2}_{t-1}} - \underbrace{(\frac{2\sqrt{\alpha_{t}}}{\beta_{t}}x_{t} + \frac{2\sqrt{\overline{\alpha}_{t-1}}}{1-\overline{\alpha}_{t-1}}x_{0})x_{t-1}} + \underbrace{C(x_{t}, x_{0}}))) \end{aligned} \tag{6}
q(xt−1∣xt,x0)=q(xt∣xt−1,x0)q(xt−1∣x0)q(xt∣x0)1=[αtxt−1+1−αtz1]×[αt−1x0+1−αt−1zt−1]×[αtx0+1−αtzt1]∝exp(−21(βt(xt−αtxt−1)2+1−αt−1(xt−1−αt−1x0)2−1−αt(xt−αtx0)2))=exp(−21((
βtαt+1−αt−11)xt−12−
(βt2αtxt+1−αt−12αt−1x0)xt−1+
C(xt,x0)))(6)
根据
exp
(
−
(
x
−
μ
)
2
2
σ
2
)
=
exp
(
−
1
2
(
1
σ
2
x
2
−
2
μ
σ
2
x
+
μ
2
σ
2
)
)
\exp(-\frac{(x-\mu)^{2}}{2\sigma^{2}}) = \exp(-\frac{1}{2}(\frac{1}{\sigma^{2}}x^{2}-\frac{2\mu}{\sigma^{2}}x + \frac{\mu^{2}}{\sigma^{2}}))
exp(−2σ2(x−μ)2)=exp(−21(σ21x2−σ22μx+σ2μ2)),对于大括号中的部分进行化简能够得到
q
(
x
t
−
1
∣
x
t
,
x
0
)
q(x_{t-1}|x_{t}, x_{0})
q(xt−1∣xt,x0)的均值和方差,如下
{
1
σ
2
=
1
β
~
t
=
(
α
t
β
t
+
1
1
−
α
‾
t
−
1
)
2
μ
σ
2
=
2
μ
~
t
(
x
t
,
x
0
)
β
~
t
=
(
2
α
t
β
t
x
t
+
2
α
‾
t
−
1
1
−
α
‾
t
−
1
x
0
)
(7)
\left\{ \begin{array}{ll} \frac{1}{\sigma^{2}} = \frac{1}{\tilde{\beta}_{t}} = (\frac{\alpha_{t}}{\beta_{t}} + \frac{1}{1-\overline{\alpha}_{t-1}}) \\ ~~ \\ \frac{2\mu}{\sigma^{2}} = \frac{2\tilde{\mu}_{t}(x_{t}, x_{0})}{\tilde{\beta}_{t}} = (\frac{2\sqrt{\alpha_{t}}}{\beta_{t}}x_{t} + \frac{2\sqrt{\overline{\alpha}_{t-1}}}{1-\overline{\alpha}_{t-1}}x_{0}) \end{array} \right. \tag{7}
⎩
⎨
⎧σ21=β~t1=(βtαt+1−αt−11) σ22μ=β~t2μ~t(xt,x0)=(βt2αtxt+1−αt−12αt−1x0)(7)
化简得
{
β
~
t
=
1
−
α
‾
t
−
1
1
−
α
‾
t
⋅
β
t
μ
~
t
(
x
t
,
x
0
)
=
α
t
(
1
−
α
‾
t
−
1
)
1
−
α
‾
t
x
t
+
α
‾
t
−
1
β
t
1
−
α
‾
t
x
0
(8)
\left\{ \begin{array}{ll} \tilde{\beta}_{t} = \frac{1-\overline{\alpha}_{t-1}}{1-\overline{\alpha}_{t}} \cdot \beta_{t} \\ ~~ \\ \tilde{\mu}_{t}(x_{t}, x_{0}) = \frac{\sqrt{\alpha_{t}}(1-\overline{\alpha}_{t-1})}{1-\overline{\alpha}_{t}}x_{t} + \frac{\sqrt{\overline{\alpha}_{t-1}}\beta_{t}}{1-\overline{\alpha}_{t}}x_{0} \end{array} \right. \tag{8}
⎩
⎨
⎧β~t=1−αt1−αt−1⋅βt μ~t(xt,x0)=1−αtαt(1−αt−1)xt+1−αtαt−1βtx0(8)
由
x
t
=
α
‾
t
x
0
+
1
−
α
‾
t
z
‾
t
x_{t} = \sqrt{\overline{\alpha}_{t}}x_{0} + \sqrt{1-\overline{\alpha}_{t}}\overline{z}_{t}
xt=αtx0+1−αtzt,得
x
0
=
1
α
‾
t
(
x
t
−
1
−
α
‾
t
z
t
‾
)
x_{0} = \frac{1}{\sqrt{\overline{\alpha}_{t}}}(x_{t}-\sqrt{1-\overline{\alpha}_{t}}\overline{z_{t}})
x0=αt1(xt−1−αtzt)并替换上面均值中的
x
0
x_{0}
x0得到
μ
~
t
=
1
α
t
(
x
t
−
β
t
1
−
α
‾
t
z
‾
t
)
(9)
\tilde{\mu}_{t} = \frac{1}{\sqrt{\alpha_{t}}}(x_{t} - \frac{\beta_{t}}{\sqrt{1-\overline{\alpha}_{t}}}\overline{z}_{t}) \tag{9}
μ~t=αt1(xt−1−αtβtzt)(9)
这样我们证明最初已知
x
0
x_{0}
x0后的反向表达式了,即
q
(
x
t
−
1
∣
x
t
,
x
0
)
=
(
x
t
−
1
;
μ
~
(
x
t
,
x
0
)
,
β
~
t
I
)
w
h
e
r
e
∼
μ
~
t
=
1
α
t
(
x
t
−
β
t
1
−
α
‾
t
z
‾
t
)
∼
β
~
t
=
1
−
α
‾
t
−
1
1
−
α
‾
t
⋅
β
t
(10)
\begin{aligned} & q(x_{t-1}|x_{t}, x_{0}) = \mathcal(x_{t-1}; \tilde{\mu}(x_{t}, x_{0}), \tilde{\beta}_{t}I) \\ & where \sim \tilde{\mu}_{t} = \frac{1}{\sqrt{\alpha_{t}}}(x_{t} - \frac{\beta_{t}}{\sqrt{1-\overline{\alpha}_{t}}}\overline{z}_{t}) \\ &\quad \quad \ \ \ \sim \tilde{\beta}_{t} = \frac{1-\overline{\alpha}_{t-1}}{1-\overline{\alpha}_{t}} \cdot \beta_{t} \end{aligned} \tag{10}
q(xt−1∣xt,x0)=(xt−1;μ~(xt,x0),β~tI)where∼μ~t=αt1(xt−1−αtβtzt) ∼β~t=1−αt1−αt−1⋅βt(10)
观察发现 α t \alpha_{t} αt, β t \beta_{t} βt, α ‾ t \overline{\alpha}_{t} αt, α ‾ t − 1 \overline{\alpha}_{t-1} αt−1都是已知的,要想由 x t x_{t} xt得到 x t − 1 x_{t-1} xt−1未知的只有 z ‾ t \overline{z}_{t} zt,这也是为什么在反向过程中我们要通过神经网络来预测噪声的原因,预测成功之后我们就可以得到 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_{t}, x_{0}) q(xt−1∣xt,x0)的分布了,然后利用重参数技巧来得到 x t − 1 x_{t-1} xt−1
3. 回到第一步的理想目标
通过上述推导发现要得到
x
t
−
1
x_{t-1}
xt−1,反向过程的目的就是预测前向过程每一次t加入的噪声,因此这里的高斯分布
z
‾
t
\overline{z}_{t}
zt是深度学习模型所预测的噪声(即重参数化时从标准高斯分布中采样的噪声),可以看做
z
θ
(
x
t
,
t
)
z_{\theta}(x_{t}, t)
zθ(xt,t),由此得到均值为
μ
θ
(
x
t
,
t
)
=
1
α
t
(
x
t
−
β
t
1
−
α
‾
t
z
θ
(
x
t
,
t
)
)
(11)
\mu_{\theta}(x_{t}, t) = \frac{1}{\sqrt{\alpha_{t}}}(x_{t} - \frac{\beta_{t}}{\sqrt{1-\overline{\alpha}_{t}}}z_{\theta}(x_{t}, t)) \tag{11}
μθ(xt,t)=αt1(xt−1−αtβtzθ(xt,t))(11)
网络的最终目的就是预测 z θ ( x t , t ) z_{\theta}(x_{t}, t) zθ(xt,t),或者说是均值 μ θ ( x t , t ) \mu_{\theta}(x_{t}, t) μθ(xt,t),至于方差 Σ θ ( x t , t ) \Sigma_{\theta}(x_{t}, t) Σθ(xt,t)从推导来看他是一个固定值,论文中也提到当做固定值效果更好

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









