






说在前面
此博客用于记录学习diffusion model初期对于模型原理,数学公式推导的认识,本人在学习过程中,发现没有真正优质能让人看懂的博客,那就自己做一个记录吧,以下内容来自网络,文末附引用。
什么是扩散模型?
每接触一个新的模型都会问的问题,GPT的解释是这样的:
Diffusion Model 是近年来在生成式建模领域取得显著进展的一类概率模型,主要用于生成高质量的样本,比如图像、音频、视频等数据类型。它基于对数据分布的逐步逼近与还原,结合了理论上的优雅性和实际应用的高性能。
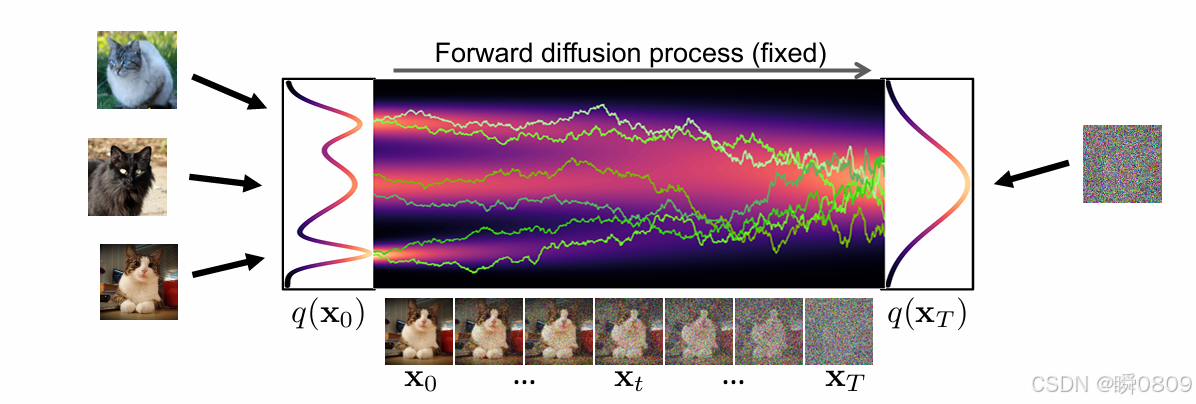
其核心思想是通过一系列逐步增加噪声的过程将数据分布转换成一个简单的先验分布(如高斯分布),再训练一个模型来逆转这个过程,即从噪声中逐渐恢复出原始的数据分布。
扩散模型的训练目标通常是优化一个损失函数,这个损失函数衡量的是模型预测的噪声与实际添加的噪声之间的差异。训练过程中,模型学习到的是如何从噪声数据中恢复出原始数据的方法,因此能够用于生成新的数据样本。
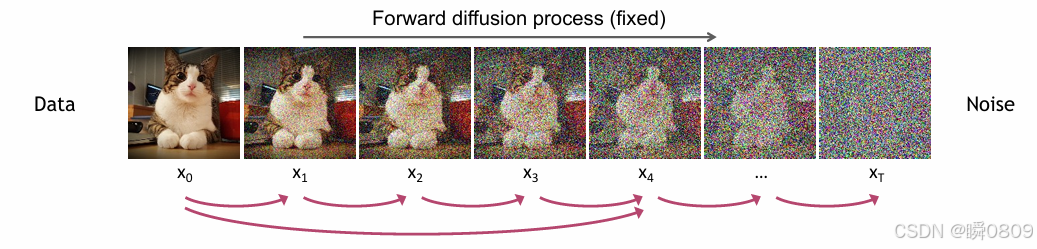
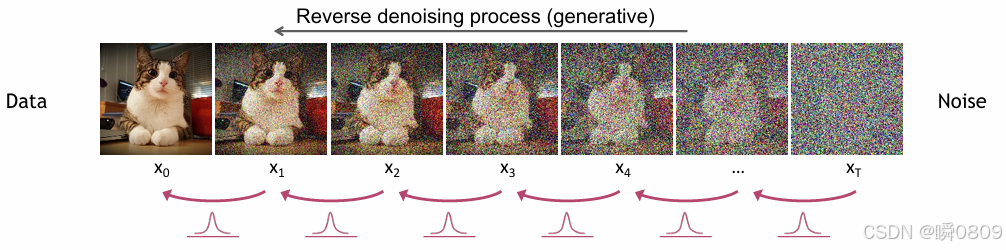
可以理解为模拟的是一个正向扩散过程和反向生成过程。在正向过程中,是将噪声逐步加入到数据中,最终转化为近似高斯分布的情况;在反向过程中,是从纯噪声逐步还原数据,直到生成近似真实样本的结果。
公式推导
前向过程
α t = 1 − β t \alpha _t=1-\beta _t αt=1−βt 这里面的 β \beta β会逐渐变大,从0.0001到0.002,对应的 α \alpha α就会逐渐变小,在代码中是直接在这个范围内等间隔采样,随着迭代次数的增加, β \beta β增大。
x t = a t x t − 1 + 1 − a t z 1 ( 1 ) x_t=\sqrt{a_t} x_{t-1}+\sqrt{1-a_t}z_1(1) xt=atxt−1+1−atz1(1)
这个式子描述前向过程中由
x
t
−
1
x_{t-1}
xt−1得
x
t
x_{t}
xt。可以看到在开始时候,只加一点噪声,后来越加越多,直到近似成为全噪声的图像。
现在需要解决的问题:对于整个序列,一个一个计算太费事,对任意时刻的
X
t
X_t
Xt能不能直接由
X
0
X_0
X0计算得来?
x t − 1 = a t − 1 x t − 2 + 1 − a t − 1 z 2 ( 2 ) x_{t-1}=\sqrt{a_{t-1}} x_{t-2}+\sqrt{1-a_{t-1}}z_2(2) xt−1=at−1xt−2+1−at−1z2(2),将这个(2)式带入(1)式,有:
x t = a t ( a t − 1 x t − 2 + 1 − α t − 1 z 2 ) + 1 − α t z 1 ( 3 ) x_t=\sqrt{a_t}(\sqrt{a_{t-1}}x_{t-2}+\sqrt{1-\alpha_{t-1}}z_2)+\sqrt{1-\alpha_t}z_1(3) xt=at(at−1xt−2+1−αt−1z2)+1−αtz1(3)
目前已知的是每次加入的噪声
z
1
,
z
2
z_1,z_2
z1,z2等都服从高斯分布
N
(
0
,
I
)
\mathcal{N}(0,\mathbf{I})
N(0,I)
将(3)式展开:
x t = a t a t − 1 x t − 2 + ( a t ( 1 − α t − 1 ) z 2 + 1 − α t z 1 ) ( 4 ) x_t=\sqrt{a_ta_{t-1}}x_{t-2}+(\sqrt{a_t(1-\alpha_{t-1})}z_2+\sqrt{1-\alpha_t}z_1)(4) xt=atat−1xt−2+(at(1−αt−1)z2+1−αtz1)(4)
x t = a t a t − 1 x t − 2 + 1 − α t α t − 1 z ( 5 ) x_t=\sqrt{a_ta_{t-1}}x_{t-2}+\sqrt{1-\alpha_t\alpha_{t-1}}{z}(5) xt=atat−1xt−2+1−αtαt−1z(5)
已知(4)中的 z 1 , z 2 z_1,z_2 z1,z2分别服从 N ( 0 , 1 − α t ) , N ( 0 , a t ( 1 − α t − 1 ) ) \mathcal{N}(0,\mathbf{1-\alpha_t}),\mathcal{N}(0,\mathbf{a_t(1-\alpha_{t-1})}) N(0,1−αt),N(0,at(1−αt−1))。
有性质 N ( 0 , σ 1 2 I ) + N ( 0 , σ 2 2 I ) ∼ N ( 0 , ( σ 1 2 + σ 2 2 ) I ) \mathcal{N}(0,\sigma_1^2\mathbf{I})+\mathcal{N}(0,\sigma_2^2\mathbf{I})\sim\mathcal{N}(0,(\sigma_1^2+\sigma_2^2)\mathbf{I}) N(0,σ12I)+N(0,σ22I)∼N(0,(σ12+σ22)I) ,所以(5)式中的 z 的方差是 1 − α t + a t ( 1 − α t − 1 ) = 1 − α t α t − 1 1-\alpha_t+a_t(1-\alpha_{t-1})=1-\alpha_t\alpha_{t-1} 1−αt+at(1−αt−1)=1−αtαt−1
观察(5)式,可以发现 x t x_t xt 和 x t − 2 x_{t-2} xt−2 的关系可以迭代推广,一直迭代到 x 0 x_0 x0,得到:
x t = α ‾ t x 0 + 1 − α ‾ t z t x_t=\sqrt{\overline{\alpha}_t}x_0+\sqrt{1-\overline{\alpha}_t}{z}_t xt=αtx0+1−αtzt (其中 α ‾ t \overline{\alpha}_t αt 指的是累乘,就是 α t ∗ α t − 1 ∗ α t − 2 ∗ ∗ α 1 {\alpha}_t*{\alpha}_{t-1}*{\alpha}_{t-2}**{\alpha}_{1} αt∗αt−1∗αt−2∗∗α1)(6)
上面的式子说明对于扩散模型的前向过程,可根据 x 0 x_0 x0直接得到任意时刻的分布。到此,前向过程可以进行。
反向过程
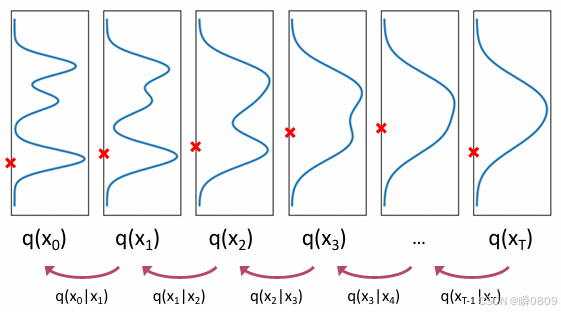
根据上面的逆向图例,要根据
X
T
X_T
XT求
X
T
−
1
X_{T-1}
XT−1,就需要知道
q
(
x
T
−
1
∣
x
T
)
q(x_{T-1}|x_T)
q(xT−1∣xT)
有贝叶斯公式可知, q ( x T − 1 ∣ x T ) = q ( x T ∣ x T − 1 ) q ( x T − 1 ) q ( x T ) q(x_{T-1}|x_T)=q(x_{T}|x_{T-1}) \frac{q(x_{T-1})}{q(x_T)} q(xT−1∣xT)=q(xT∣xT−1)q(xT)q(xT−1)
结合正向过程中的 x 0 x_0 x0,有 q ( x t − 1 ∣ x t , x 0 ) = q ( x t ∣ x t − 1 , x 0 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) q(\mathbf{x}_{t-1}|\mathbf{x}_t,\mathbf{x}_0)=q(\mathbf{x}_t|\mathbf{x}_{t-1},\mathbf{x}_0)\frac{q(\mathbf{x}_{t-1}|\mathbf{x}_0)}{q(\mathbf{x}_t|\mathbf{x}_0)} q(xt−1∣xt,x0)=q(xt∣xt−1,x0)q(xt∣x0)q(xt−1∣x0)
上式左侧的三个部分都可求,对应的 q ( x t − 1 ∣ x t , x 0 ) q(\mathbf{x}_{t-1}|\mathbf{x}_t,\mathbf{x}_0) q(xt−1∣xt,x0)也可求。
q ( x t − 1 ∣ x 0 ) a ‾ t − 1 x 0 + 1 − a ‾ t − 1 z ∼ N ( a ‾ t − 1 x 0 , 1 − a ‾ t − 1 ) {q(\mathbf{x}_{t-1}|\mathbf{x}_0)}\quad\sqrt{\overline{a}_{t-1}}x_0+\sqrt{1-\overline{a}_{t-1}}z\quad\sim\mathcal{N}(\sqrt{\overline{a}_{t-1}}x_0 , 1-\overline{a}_{t-1}) q(xt−1∣x0)at−1x0+1−at−1z∼N(at−1x0,1−at−1)
q ( x t ∣ x 0 ) a ‾ t x 0 + 1 − a ‾ t z ∼ N ( a ‾ t x 0 , 1 − a ‾ t ) {q(\mathbf{x}_{t}|\mathbf{x}_0)}\quad\sqrt{\overline{a}_{t}}x_0+\sqrt{1-\overline{a}_{t}}z\quad\sim\mathcal{N}(\sqrt{\overline{a}_{t}}x_0 , 1-\overline{a}_{t}) q(xt∣x0)atx0+1−atz∼N(atx0,1−at)
q ( x t ∣ x t − 1 , x 0 ) a t x t − 1 + 1 − a t z ∼ N ( a t x t − 1 , 1 − a t ) q(\mathbf{x}_t|\mathbf{x}_{t-1},\mathbf{x}_0)\quad\sqrt{{a}_{t}}x_{t-1}+\sqrt{1-{a}_{t}}z\quad\sim\mathcal{N}(\sqrt{{a}_{t}}x_{t-1} , 1-{a}_{t}) q(xt∣xt−1,x0)atxt−1+1−atz∼N(atxt−1,1−at)
上面第一个式子可以理解为直接根据 x 0 x_0 x0求 x t − 1 x_{t-1} xt−1,第二个式子是直接根据 x 0 x_0 x0求 x t x_{t} xt,直接套用上面的公式(6)即可,而对第三个单纯就是式子(1)。
已知对于高斯分布 N ( μ , σ ) \mathcal{N}(\mu,\sigma) N(μ,σ),有概率密度函数 p ( x ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 p(x)=\frac1{\sqrt{2\pi}\sigma}e^{\frac{-(x-\mu)^2}{2\sigma^2}} p(x)=2πσ1e2σ2−(x−μ)2
即 N ( μ , σ ) ∝ e − ( x − μ ) 2 2 σ 2 \mathcal{N}(\mu,\sigma) \propto e^{\frac{-(x-\mu)^2}{2\sigma^2}} N(μ,σ)∝e2σ2−(x−μ)2,可以根据上面部分的高斯分布得到我们要求解的 q ( x T − 1 ∣ x T ) q(x_{T-1}|x_T) q(xT−1∣xT)正比的形式。
q ( x t − 1 ∣ x t , x 0 ) ∝ exp ( − 1 2 ( ( x t − α t x t − 1 ) 2 β t + ( x t − 1 − α ˉ t − 1 x 0 ) 2 1 − α ˉ t − 1 − ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) ) \begin{aligned}&q(\mathbf{x}_{t-1}|\mathbf{x}_t,\mathbf{x}_0)\propto\exp\Big(-\frac12\big(\frac{(\mathbf{x}_t-\sqrt{\alpha_t}\mathbf{x}_{t-1})^2}{\beta_t}+\frac{(\mathbf{x}_{t-1}-\sqrt{\bar{\alpha}_{t-1}}\mathbf{x}_0)^2}{1-\bar{\alpha}_{t-1}}-\frac{(\mathbf{x}_t-\sqrt{\bar{\alpha}_t}\mathbf{x}_0\big)^2}{1-\bar{\alpha}_t}\big)\big)\end{aligned} q(xt−1∣xt,x0)∝exp(−21(βt(xt−αtxt−1)2+1−αˉt−1(xt−1−αˉt−1x0)2−1−αˉt(xt−αˉtx0)2))

根据对应关系,可以看到上面图片中的红色部分括号中对应分布的方差。又因为在最原始的模型中,
α
t
和
β
t
\alpha_t和\beta_t
αt和βt都是固定已知的,所以方差已知。上图中蓝色部分对应可以求解均值,求出的均值:
μ ~ t ( x t , x 0 ) = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 β t 1 − α ˉ t x 0 \tilde{\boldsymbol{\mu}}_t(\mathbf{x}_t,\mathbf{x}_0) =\frac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t}\mathbf{x}_t+\frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1-\bar{\alpha}_t}\mathbf{x}_0 μ~t(xt,x0)=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtx0
但是目前存在的问题:
X
0
X_0
X0就是要反向过程要求解的状态。
这个时候正向过程的(6)式就可以拿来替换了,由(6)式得到
x
0
=
1
α
ˉ
t
(
x
t
−
1
−
α
ˉ
t
z
t
)
\mathbf{x}_{0}=\frac{1}{\sqrt{\bar{\alpha}_{t}}}(\mathbf{x}_{t}-\sqrt{1-\bar{\alpha}_{t}}\mathbf{z}_{t})
x0=αˉt1(xt−1−αˉtzt)
最终结果:
μ
~
t
=
1
a
t
(
x
t
−
β
t
1
−
a
‾
t
z
t
)
\tilde{\mu}_{t}=\frac{1}{\sqrt{a_{t}}}(x_{t}-\frac{\beta_{t}}{\sqrt{1-\overline{a}_{t}}}{z}_{t})
μ~t=at1(xt−1−atβtzt)
目前已知方差和均值,可以将反向的过程一步一步进行下去了。
但是目前又出现问题:上式中的 z t {z}_{t} zt用数学方法始终没办法求,所以只能借助于模型训练,通过模型预测在某时刻 t 的噪声。(ps:一顿操作猛如虎,最后还是需要神经网络出手 -_-)
模型训练
上面提到了,其实就是对每一步的噪声进行拟合,模型的训练需要标签,在扩散模型中,正向过程加噪的过程中,自己加入的噪声肯定是已知的。那么在反向的过程中,关注模型预测出来的噪声和原来加入的噪声之间的差异,尝试最小化两者之间差异就可以进行训练。
算法解读

训练阶段
#2 对于某一个特定的分布q(x_0),在该分布中进行采样(大致可以理解为,比如全是猫的数据集,全是狗的数据集,在这个特定的数据集里面进行采样得到x_0)
#3 对应的t是在1到T这个范围内随机选的。在同一个batch中,每个图片对应的t也不一致
#4 前提:噪声需要服从标准正态分布
#5 模型的训练,其中是指要训练的模型,模型的输入就是图中框出来的部分,也就是X_T,模型的输入同时还包含 t,就是把时刻也输入到了模型中,在实际操作中,会根据 t 生成一个向量(正弦位置嵌入),作为轮数的编码。用模型预测值不断拟合真实值,通过Unet这个框架学习到噪音的信息。
采样阶段
#1 x_T 是随机采样的,看作高斯分布
#2#3#4#5 做循环,从 x_T 一直循环到 x_1,逐步从全噪音图还原成想要的图片。使用的是推导的公式,配合已经训练的模型,可以实现想要的效果。
#6 得到最终的x_0
感谢Diffusion Model:比“GAN"还要牛逼的图像生成模型!论文精读+公式推导 视频的讲解,侵删

















 896
896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









