








1.多模态循环融合(MCF)

MCF的详细过程如图,x,y为不同模态特征向量,首先利用两个投影矩阵W1,W2将将特征投影到VC两个低维空间。

然后利用V、C构造循环矩阵A和B
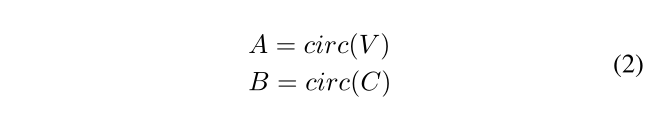
为了使投影向量和循环矩阵中的元素充分作用,我们探索了两种不同的乘法运算
1)在循环矩阵和投影向量之间使用矩阵乘法
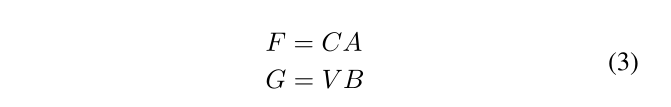
2)是让循环矩阵的投影向量和每行进行元素积

最后通过一个投影矩阵W3,将F和G的利用element-wise sum转换为M
2.MCF for Video Captioning
开发了一个视频->字幕框架:卷积编码器和解码器
在解码器中,将MCF作为粗略解码的基础层,在基础层上堆叠分层扩展以进行精细和最终解码。
因此用MCF构建了一个多级解码器
2.1卷积编码网络
1)特征提取:
使用预先训练的卷积网络对每m帧提取特征,产生向量Xi对第i帧
2)区别性提升:
对两个连续的帧Xi和Xi+1,计算帧间差别diff,然后通过relu运算,添加积极的diff到Xi+1,将消极的diff添加到Xi。
因而扩大区别性差异在Xi与Xi+1之间

Vi是提升结果
3)重构网络
我们构建了一个重构网络来学习每个视频帧的紧凑表示

We是卷积权重,Zi是学习的紧致表示,Wd是重构权重,Ri是重构结果
L是损失函数
2.2Multi-stage Convolutional Decoder with MCF

多级顺序解码器示意图。对于这个解码器,我们首先使用MCF来获得视觉特征和单词嵌入特征的联合表示。然后我们把联合表示作为这个解码器的输入。“粗略”、“精细”和“最终”表示解码器的三个阶段。相应的不断改进的视频描述以绿色、黄色和橙色显示
预测单词序列用第j个解码器:
![]()
目标单词序列:
![]()
1)MCF作为粗解码器
在底部阶段,用一个扩展卷积层来学习一个粗解码器,在每一个时间t,粗解码器的输入包括先前的目标单词Yt-1和mean向量Zmean(编码器的输出)
一开始用MCF去获得联合表示![]()
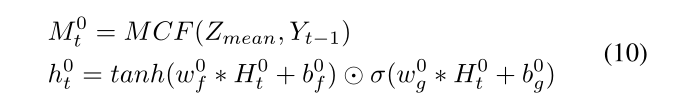
![]()
MCF(a,b)表示使用MCF去融合a和b
wfwg表示第0层的卷积权重
2)改进解码器
由两个阶段组成,第一个阶段包含三个扩张的卷积层,第二阶段仅包括一个堆叠在第一级之上的扩展卷积层。第二阶段的预测作为最终描述。
改进解码器:
对于第一个改进解码器,使用粗解码器的输出h0来计算视觉注意力![]()
该改进解码器中第一层的操作:
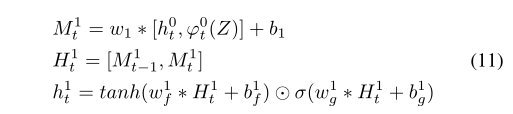
w1是可学习的权重,用于转换级联表示的通道
然后第一改进解码器的下两层操作

第二个改进的解码器:
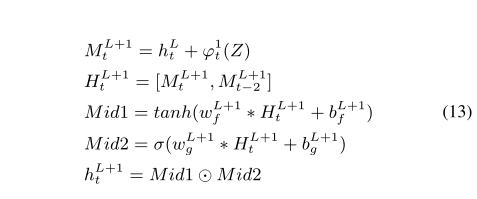














 690
690











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









