




 本文深入探讨了激活函数(如sigmoid、ReLU及其变种)的作用及特性,并详细介绍了多种优化方法(包括SGD、Momentum及Adam等),旨在帮助读者理解深度学习中的关键组件。
本文深入探讨了激活函数(如sigmoid、ReLU及其变种)的作用及特性,并详细介绍了多种优化方法(包括SGD、Momentum及Adam等),旨在帮助读者理解深度学习中的关键组件。
关于激活函数,首先要搞清楚的问题是,激活函数是什么,有什么用?不用激活函数可不可以?答案是不可以。激活函数的主要作用是提供网络的非线性建模能力。如果没有激活函数,那么该网络仅能够表达线性映射,此时即便有再多的隐藏层,其整个网络跟单层神经网络也是等价的。因此也可以认为,只有加入了激活函数之后,深度神经网络才具备了分层的非线性映射学习能力。 那么激活函数应该具有什么样的性质呢?
可微性: 当优化方法是基于梯度的时候,这个性质是必须的。
单调性: 当激活函数是单调的时候,单层网络能够保证是凸函数。
输出值的范围: 当激活函数输出值是 有限 的时候,基于梯度的优化方法会更加 稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是 无限 的时候,模型的训练会更加高效,不过在这种情况小,一般需要更小的learning rate
从目前来看,常见的激活函数多是分段线性和具有指数形状的非线性函数
1.1.1 sigmoid

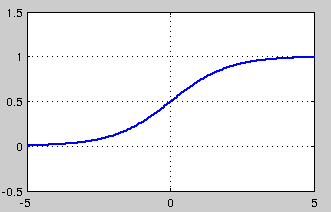
sigmoid 是使用范围最广的一类激活函数,具有指数函数形状,它在物理意义上最为接近生物神经元。此外,(0, 1) 的输出还可以被表示作概率,或用于输入的归一化,代表性的如Sigmoid交叉熵损失函数。
然而,sigmoid也有其自身的缺陷,最明显的就是饱和性。从上图可以看到,其两侧导数逐渐趋近于0

具有这种性质的称为软饱和激活函数。具体的,饱和又可分为左饱和与右饱和。与软饱和对应的是硬饱和, 即
sigmoid 的软饱和性,使得深度神经网络在二三十年里一直难以有效的训练,是阻碍神经网络发展的重要原因。具体来说,由于在后向传递过程中,sigmoid向下传导的梯度包含了一个 f′(x) 因子(sigmoid关于输入的导数),因此一旦输入落入饱和区,f′(x) 就会变得接近于0,导致了向底层传递的梯度也变得非常小。此时,网络参数很难得到有效训练。这种现象被称为梯度消失。一般来说, sigmoid 网络在 5 层之内就会产生梯度消失现象
此外,sigmoid函数的输出均大于0,使得输出不是0均值,这称为偏移现象,这会导致后一层的神经元将得到上一层输出的非0均值的信号作为输入。
1.1.2 tanh

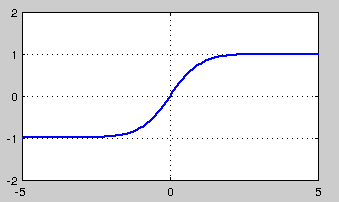
tanh也是一种非常常见的激活函数。与sigmoid相比,它的输出均值是0,使得其收敛速度要比sigmoid快,减少迭代次数。然而,从途中可以看出,tanh一样具有软饱和性,从而造成梯度消失。
1.1.3 ReLU,P-ReLU, Leaky-ReLU

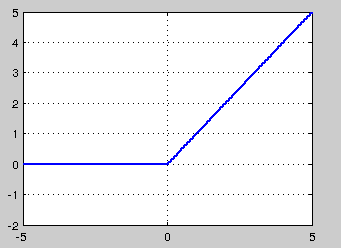
ReLU的全称是Rectified Linear Units,是一种后来才出现的激活函数。 可以看到,当x<0时,ReLU硬饱和,而当x>0时,则不存在饱和问题。所以,ReLU 能够在x>0时保持梯度不衰减,从而缓解梯度消失问题。这让我们能够直接以监督的方式训练深度神经网络,而无需依赖无监督的逐层预训练。
然而,随着训练的推进,部分输入会落入硬饱和区,导致对应权重无法更新。这种现象被称为“神经元死亡”。与sigmoid类似,ReLU的输出均值也大于0,偏移现象和 神经元死亡会共同影响网络的收敛性。
针对在x<0的硬饱和问题,我们对ReLU做出相应的改进,使得

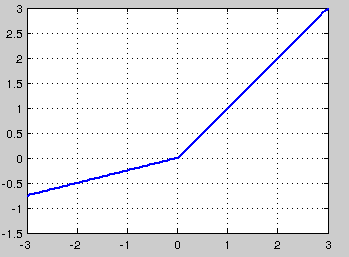
这就是Leaky-ReLU, 而P-ReLU认为,α也可以作为一个参数来学习,原文献建议初始化a为0.25,不采用正则。
1.1.4 ELU

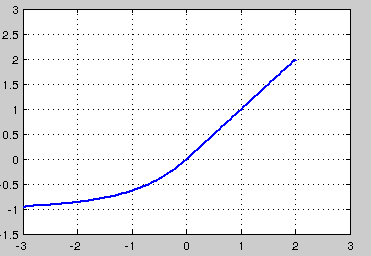
融合了sigmoid和ReLU,左侧具有软饱和性,右侧无饱和性。右侧线性部分使得ELU能够缓解梯度消失,而左侧软饱能够让ELU对输入变化或噪声更鲁棒。ELU的输出均值接近于零,所以收敛速度更快。在 ImageNet上,不加 Batch Normalization 30 层以上的 ReLU 网络会无法收敛,PReLU网络在MSRA的Fan-in (caffe )初始化下会发散,而 ELU 网络在Fan-in/Fan-out下都能收敛
1.1.5 Maxout

在我看来,这个激活函数有点大一统的感觉,因为maxout网络能够近似任意连续函数,且当w2,b2,…,wn,bn为0时,退化为ReLU。Maxout能够缓解梯度消失,同时又规避了ReLU神经元死亡的缺点,但增加了参数和计算量。
2.1 损失函数
在之前的内容中,我们用的损失函数都是平方差函数,即

其中y是我们期望的输出,a为神经元的实际输出(a=σ(Wx+b)。也就是说,当神经元的实际输出与我们的期望输出差距越大,代价就越高。想法非常的好,然而在实际应用中,我们知道参数的修正是与∂C/∂W和∂C/∂b成正比的,而根据

我们发现其中都有σ′(a)这一项。因为sigmoid函数的性质,导致σ′(z)在z取大部分值时会造成饱和现象,从而使得参数的更新速度非常慢,甚至会造成离期望值越远,更新越慢的现象。那么怎么克服这个问题呢?我们想到了交叉熵函数。我们知道,熵的计算公式是

而在实际操作中,我们并不知道y的分布,只能对y的分布做一个估计,也就是算得的a值, 这样我们就能够得到用a来表示y的交叉熵

如果有多个样本,则整个样本的平均交叉熵为

其中n表示样本编号,i表示类别编。 如果用于logistic分类,则上式可以简化成

与平方损失函数相比,交叉熵函数有个非常好的特质,

可以看到其中没有了σ′这一项,这样一来也就不会受到饱和性的影响了。当误差大的时候,权重更新就快,当误差小的时候,权重的更新就慢。这是一个很好的性质。
3.1优化方法
主要是一阶的梯度法,包括SGD, Momentum, Nesterov Momentum, AdaGrad, RMSProp, Adam。 其中SGD,Momentum,Nesterov Momentum是手动指定学习速率的,而后面的AdaGrad, RMSProp, Adam,就能够自动调节学习速率.
3.1.1BGD
即batch gradient descent. 在训练中,每一步迭代都使用训练集的所有内容. 也就是说,利用现有参数对训练集中的每一个输入生成一个估计输出yi^,然后跟实际输出yi比较,统计所有误差,求平均以后得到平均误差,以此来作为更新参数的依据.
具体实现:
需要:学习速率 ϵ, 初始参数 θ
每步迭代过程:
1. 提取训练集中的所有内容{x1,…,xn},以及相关的输出yi
2. 计算梯度和误差并更新参数:

优点:
由于每一步都利用了训练集中的所有数据,因此当损失函数达到最小值以后,能够保证此时计算出的梯度为0,换句话说,就是能够收敛.因此,使用BGD时不需要逐渐减小学习速率ϵk
缺点:
由于每一步都要使用所有数据,因此随着数据集的增大,运行速度会越来越慢.
3.1.2 SGD
SGD全名 stochastic gradient descent, 即随机梯度下降。不过这里的SGD其实跟MBGD(minibatch gradient descent)是一个意思,即随机抽取一批样本,以此为根据来更新参数.
具体实现:
需要:学习速率 ϵ, 初始参数 θ
每步迭代过程:
1. 从训练集中的随机抽取一批容量为m的样本{x1,…,xm},以及相关的输出yi
2. 计算梯度和误差并更新参数:

优点:
训练速度快,对于很大的数据集,也能够以较快的速度收敛.
缺点:
由于是抽取,因此不可避免的,得到的梯度肯定有误差.因此学习速率需要逐渐减小.否则模型无法收敛
因为误差,所以每一次迭代的梯度受抽样的影响比较大,也就是说梯度含有比较大的噪声,不能很好的反映真实梯度.
学习速率该如何调整:
那么这样一来,ϵ如何衰减就成了问题.如果要保证SGD收敛,应该满足如下两个要求:

而在实际操作中,一般是进行线性衰减:

其中ϵ0是初始学习率, ϵτ是最后一次迭代的学习率. τ自然代表迭代次数.一般来说,ϵτ 设为ϵ0的1%比较合适.而τ一般设为让训练集中的每个数据都输入模型上百次比较合适.那么初始学习率ϵ0怎么设置呢?书上说,你先用固定的学习速率迭代100次,找出效果最好的学习速率,然后ϵ0设为比它大一点就可以了.
3.1.3 Momentum
上面的SGD有个问题,就是每次迭代计算的梯度含有比较大的噪音. 而Momentum方法可以比较好的缓解这个问题,尤其是在面对小而连续的梯度但是含有很多噪声的时候,可以很好的加速学习.Momentum借用了物理中的动量概念,即前几次的梯度也会参与运算.为了表示动量,引入了一个新的变量v(velocity).v是之前的梯度的累加,但是每回合都有一定的衰减.
具体实现:
需要:学习速率 ϵ, 初始参数 θ, 初始速率v, 动量衰减参数α
每步迭代过程:
1. 从训练集中的随机抽取一批容量为m的样本{x1,…,xm},以及相关的输出yi
2. 计算梯度和误差,并更新速度v和参数θ:

其中参数α表示每回合速率v的衰减程度.同时也可以推断得到,如果每次迭代得到的梯度都是g,那么最后得到的v的稳定值为

也就是说,Momentum最好情况下能够将学习速率加速11−α倍.一般α的取值有0.5,0.9,0.99这几种.当然,也可以让α的值随着时间而变化,一开始小点,后来再加大.不过这样一来,又会引进新的参数.
特点:
前后梯度方向一致时,能够加速学习
前后梯度方向不一致时,能够抑制震荡
3.1.4 Nesterov Momentum
这是对之前的Momentum的一种改进,大概思路就是,先对参数进行估计,然后使用估计后的参数来计算误差
具体实现:
需要:学习速率 ϵ, 初始参数 θ, 初始速率v, 动量衰减参数α
每步迭代过程:
1. 从训练集中的随机抽取一批容量为m的样本{x1,…,xm},以及相关的输出yi
2. 计算梯度和误差,并更新速度v和参数θ:

注意在估算g^的时候,参数变成了θ+αv而不是之前的θ
3.1.5 AdaGrad
AdaGrad可以自动变更学习速率,只是需要设定一个全局的学习速率ϵ,但是这并非是实际学习速率,实际的速率是与以往参数的模之和的开方成反比的.也许说起来有点绕口,不过用公式来表示就直白的多:

其中δ是一个很小的常亮,大概在10−7,防止出现除以0的情况.
具体实现:
需要:全局学习速率 ϵ, 初始参数 θ, 数值稳定量δ
中间变量: 梯度累计量r(初始化为0)
每步迭代过程:
1. 从训练集中的随机抽取一批容量为m的样本{x1,…,xm},以及相关的输出yi
2. 计算梯度和误差,更新r,再根据r和梯度计算参数更新量

优点:
能够实现学习率的自动更改。如果这次梯度大,那么学习速率衰减的就快一些;如果这次梯度小,那么学习速率衰减的就满一些。
缺点:
任然要设置一个变量ϵ
经验表明,在普通算法中也许效果不错,但在深度学习中,深度过深时会造成训练提前结束。
3.1.6 RMSProp
RMSProp通过引入一个衰减系数,让r每回合都衰减一定比例,类似于Momentum中的做法。
具体实现:
需要:全局学习速率 ϵ, 初始参数 θ, 数值稳定量δ,衰减速率ρ
中间变量: 梯度累计量r(初始化为0)
每步迭代过程:
1. 从训练集中的随机抽取一批容量为m的样本{x1,…,xm},以及相关的输出yi
2. 计算梯度和误差,更新r,再根据r和梯度计算参数更新量

优点:
相比于AdaGrad,这种方法很好的解决了深度学习中过早结束的问题
适合处理非平稳目标,对于RNN效果很好
缺点:
又引入了新的超参,衰减系数ρ
依然依赖于全局学习速率
3.1.7 RMSProp with Nesterov Momentum
当然,也有将RMSProp和Nesterov Momentum结合起来的
具体实现:
需要:全局学习速率 ϵ, 初始参数 θ, 初始速率v,动量衰减系数α, 梯度累计量衰减速率ρ
中间变量: 梯度累计量r(初始化为0)
每步迭代过程:
1. 从训练集中的随机抽取一批容量为m的样本{x1,…,xm},以及相关的输出yi
2. 计算梯度和误差,更新r,再根据r和梯度计算参数更新量

3.1.8 Adam
Adam(Adaptive Moment Estimation)本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。
具体实现:
需要:步进值 ϵ, 初始参数 θ, 数值稳定量δ,一阶动量衰减系数ρ1, 二阶动量衰减系数ρ2
其中几个取值一般为:δ=10−8,ρ1=0.9,ρ2=0.999
中间变量:一阶动量s,二阶动量r,都初始化为0
每步迭代过程:
1. 从训练集中的随机抽取一批容量为m的样本{x1,…,xm},以及相关的输出yi
2. 计算梯度和误差,更新r和s,再根据r和s以及梯度计算参数更新量


















 1142
1142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









