







1.RNN原理
参考我之前的博客😂
RNN原理
RNN的5种架构
RNN存在五种架构,通俗说就是由输入的字符个数与生成的字符个数不同组合生成的架构,比如说输入一个中文,生成五个中文字,输入五个中文字生成一个中文字。
一对一:
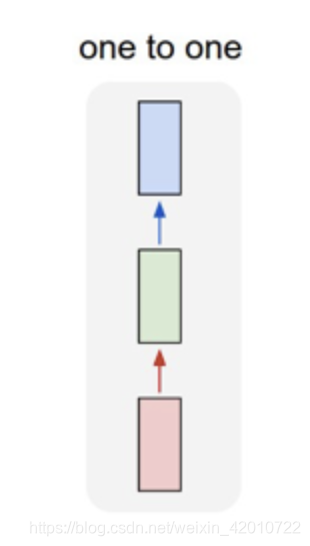
一个输入(单一标签)对应一个输出(单一标签)
一对多:
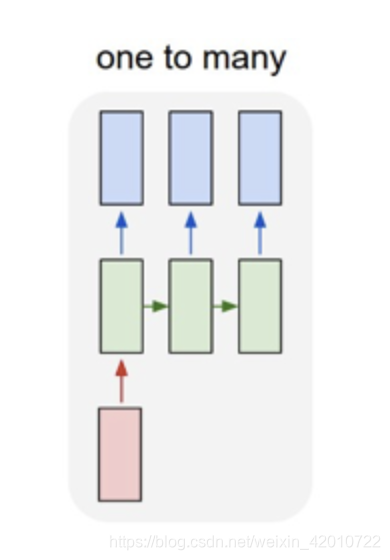
一个输入对应多个输出,即这个架构多用于图片的对象识别,即输入一个图片,输出一个文本序列
多对一:
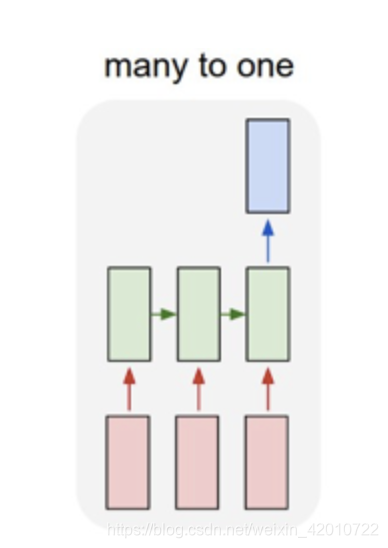
多个输入对应一个输出,多用于文本分类或视频分类,即输入一段文本或视频片段,输出类别
多对多(1):
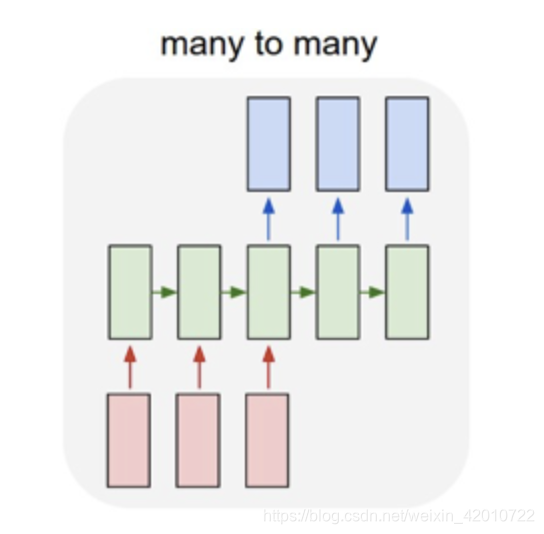
这种结构广泛的用于机器翻译,输入一个文本,输出另一种语言的文本
多对多(2):
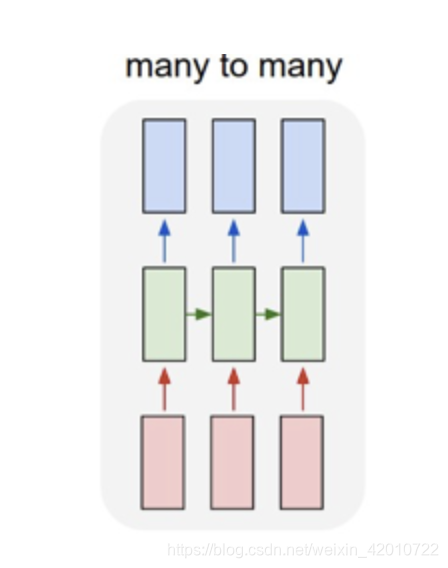
这种广泛的用于序列标注
2.LTSM结构
3.CharRNN结构
CharRNN结构对应为RNN五种结构中最后一个,Char-RNN模型是从字符的维度上,让机器生成文本,即通过已经观测到的字符出发,预测下一个字符出现的概率,也就是序列数据的推测。现在网上介绍的用深度学习写歌、写诗、写小说的大多都是基于这个方法字符的one hot编码。
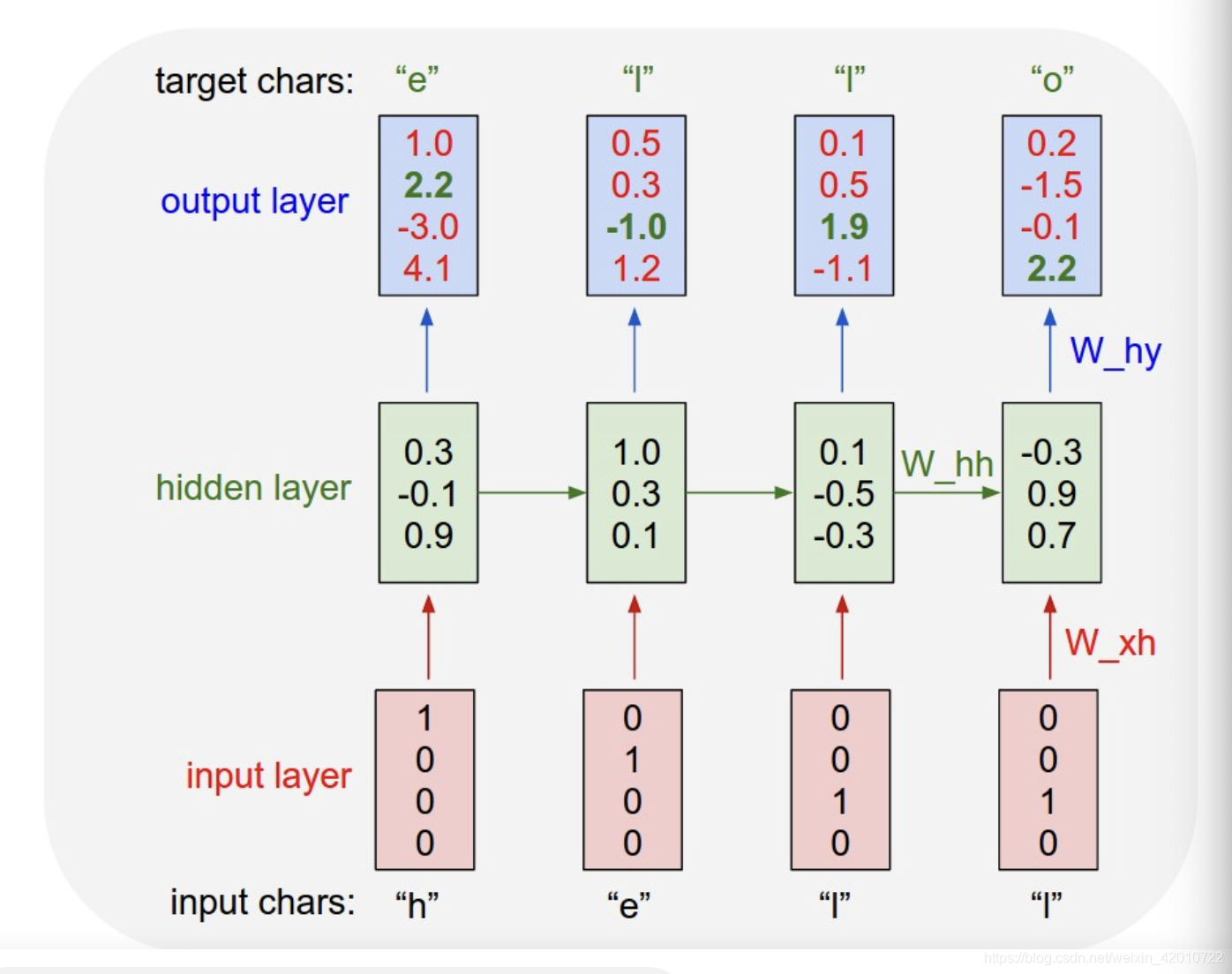
从上图中可以看到,模型输入一个“hello”字符,输入字符“h”,模型预测每个字符的概率,概率最大的为“e”,输入字符“e”,模型预测下一个字符为“I”…,在这里输入的字符通过one hot编码生成一个字符的矩阵。通过这样的模型不断的训练,在训练模型时输入大量的周杰伦歌词段落,就生成一个周杰伦歌词生成模型,这样对任何输入的字符就可以用这个模型来生成歌词段落。
模型架构如下图所示:
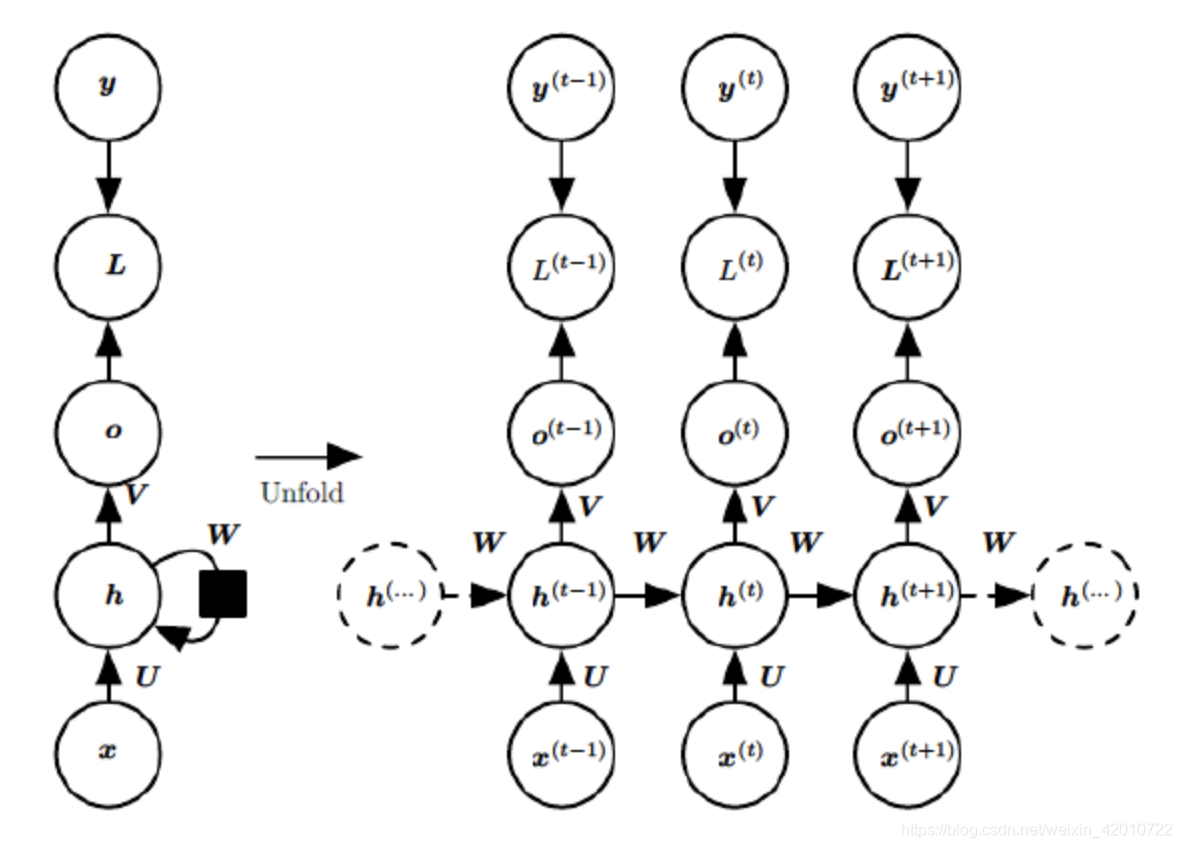
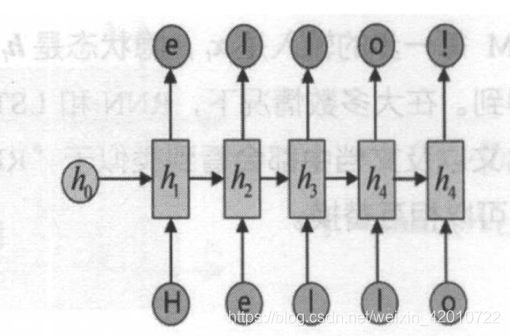
以hello为例:
具体公式如下:
h
t
=
t
a
n
h
(
W
h
h
h
t
−
1
+
W
x
h
x
t
)
+
b
h
h_{t}=tanh(W_{hh}h_{t-1}+W_{xh}x_{t})+b_{h}
ht=tanh(Whhht−1+Wxhxt)+bh
y
t
=
W
h
y
h
t
+
b
y
y_{t}=W_{hy}h_{t}+b_{y}
yt=Whyht+by
模型最后通过定义损失函数,使用梯度下降不断优化模型,实现歌词生成器模型。
4.pytorch实现
文件路径:
\CharRNN
\data
\dataset.py
\dataset
\zhoujielun.txt
\main.py
\model
char_RNN.py
\config.py
dataset文件中保存自己的歌词txt文本,这里可以自己到网易云去爬虫
char_RNN代码实现:
import torch
from torch import nn
from torch.autograd import Variable
from config import opt
class CharRNN(nn.Module):
def __init__(self, num_classes, embed_dim, hidden_size, num_layers,
dropout):
super().__init__()
self.num_layers = num_layers
self.hidden_size = hidden_size
self.word_to_vec = nn.Embedding(num_classes, embed_dim)
self.rnn = nn.GRU(embed_dim, hidden_size, num_layers, dropout)
self.project = nn.Linear(hidden_size, num_classes)
def forward(self, x, hs=None):
batch = x.shape[0]
if hs is None:
hs = Variable(
torch.zeros(self.num_layers, batch, self.hidden_size))
if opt.use_gpu:
hs = hs.cuda()
word_embed = self.word_to_vec(x) # (batch, len, embed)
word_embed = word_embed.permute(1, 0, 2) # (len, batch, embed)
out, h0 = self.rnn(word_embed, hs) # (len, batch, hidden)
le, mb, hd = out.shape
out = out.view(le * mb, hd)
out = self.project(out)
out = out.view(le, mb, -1)
out = out.permute(1, 0, 2).contiguous() # (batch, len, hidden)
return out.view(-1, out.shape[2]), h0
数据预处理dataset.py
import numpy as np
import torch
class TextConverter(object):
def __init__(self, text_path, max_vocab=5000):
"""Construct a text index converter.
Args:
text_path: txt file path.
max_vocab: maximum number of words.
"""
with open(text_path, 'r') as f:
text = f.read()
text = text.replace('\n', ' ').replace('\r', ' ').replace(',', ' ').replace('。', ' ')
vocab = set(text)
# If the number of words is larger than limit, clip the words with minimum frequency.
vocab_count = {}
for word in vocab:
vocab_count[word] = 0
for word in text:
vocab_count[word] += 1
vocab_count_list = []
for word in vocab_count:
vocab_count_list.append((word, vocab_count[word]))
vocab_count_list.sort(key=lambda x: x[1], reverse=True)
if len(vocab_count_list) > max_vocab:
vocab_count_list = vocab_count_list[:max_vocab]
vocab = [x[0] for x in vocab_count_list]
self.vocab = vocab
self.word_to_int_table = {c: i for i, c in enumerate(self.vocab)}
self.int_to_word_table = dict(enumerate(self.vocab))
@property
def vocab_size(self):
return len(self.vocab) + 1
def word_to_int(self, word):
if word in self.word_to_int_table:
return self.word_to_int_table[word]
else:
return len(self.vocab)
def int_to_word(self, index):
if index == len(self.vocab):
return '<unk>'
elif index < len(self.vocab):
return self.int_to_word_table[index]
else:
raise Exception('Unknown index!')
def text_to_arr(self, text):
arr = []
for word in text:
arr.append(self.word_to_int(word))
return np.array(arr)
def arr_to_text(self, arr):
words = []
for index in arr:
words.append(self.int_to_word(index))
return "".join(words)
class TextDataset(object):
def __init__(self, text_path, n_step, arr_to_idx):
with open(text_path, 'r') as f:
text = f.read()
text = text.replace('\n', ' ').replace('\r', ' ').replace(',', ' ').replace('。', ' ')
num_seq = int(len(text) / n_step)
self.num_seq = num_seq
self.n_step = n_step
# Clip more than maximum length.
text = text[:num_seq * n_step]
arr = arr_to_idx(text)
arr = arr.reshape((num_seq, -1))
self.arr = torch.from_numpy(arr)
def __getitem__(self, item):
x = self.arr[item, :]
y = torch.zeros(x.shape)
y[:-1], y[-1] = x[1:], x[0]
return x, y
def __len__(self):
return self.num_seq
config.py 模型配置文件代码:
import warnings
from pprint import pprint
class DefaultConfig(object):
model = 'CharRNN'
# Dataset.
txt = './dataset/poetry.txt'
len = 20
max_vocab = 8000
begin = '天青色等烟雨' # begin word of text
predict_len = 50 # predict length
# Store result and save models.
result_file = 'result.txt'
save_file = './checkpoints/'
save_freq = 30 # save model every N epochs
save_best = True
# Predict mode and generate contexts
load_model = './checkpoints/CharRNN_best_model.pth'
write_file = './write_context.txt'
# Visualization parameters.
vis_dir = './vis/'
plot_freq = 100 # plot in tensorboard every N iterations
# Model parameters.
embed_dim = 512
hidden_size = 512
num_layers = 2
dropout = 0.5
# Model hyperparameters.
use_gpu = True # use GPU or not
ctx = 0 # running on which cuda device
batch_size = 128 # batch size
num_workers = 4 # how many workers for loading data
max_epoch = 200
lr = 1e-3 # initial learning rate
weight_decay = 1e-4
def _parse(self, kwargs):
for k, v in kwargs.items():
if not hasattr(self, k):
warnings.warn("Warning: opt has not attribut %s" % k)
setattr(self, k, v)
print('=========user config==========')
pprint(self._state_dict())
print('============end===============')
def _state_dict(self):
return {k: getattr(self, k) for k, _ in DefaultConfig.__dict__.items()
if not k.startswith('_')}
opt = DefaultConfig()
main.py实现:
from copy import deepcopy
import numpy as np
import torch
from mxtorch import meter
from mxtorch.trainer import Trainer, ScheduledOptim
from torch import nn
from torch.autograd import Variable
from torch.utils.data import DataLoader
from tqdm import tqdm
import models
from config import opt
from data import TextDataset, TextConverter
def get_data(convert):
dataset = TextDataset(opt.txt, opt.len, convert.text_to_arr)
return DataLoader(dataset, opt.batch_size, shuffle=True, num_workers=opt.num_workers)
def get_model(convert):
model = getattr(models, opt.model)(convert.vocab_size,
opt.embed_dim,
opt.hidden_size,
opt.num_layers,
opt.dropout)
if opt.use_gpu:
model = model.cuda()
return model
def get_loss(score, label):
return nn.CrossEntropyLoss()(score, label.view(-1))
def get_optimizer(model):
optimizer = torch.optim.Adam(model.parameters(), lr=opt.lr)
return ScheduledOptim(optimizer)
def pick_top_n(preds, top_n=5):
top_pred_prob, top_pred_label = torch.topk(preds, top_n, 1)
top_pred_prob /= torch.sum(top_pred_prob)
top_pred_prob = top_pred_prob.squeeze(0).cpu().numpy()
top_pred_label = top_pred_label.squeeze(0).cpu().numpy()
c = np.random.choice(top_pred_label, size=1, p=top_pred_prob)
return c
class CharRNNTrainer(Trainer):
def __init__(self, convert):
self.convert = convert
model = get_model(convert)
criterion = get_loss
optimizer = get_optimizer(model)
super().__init__(model, criterion, optimizer)
self.config += ('text: ' + opt.txt + '\n' + 'train text length: ' + str(opt.len) + '\n')
self.config += ('predict text length: ' + str(opt.predict_len) + '\n')
self.metric_meter['loss'] = meter.AverageValueMeter()
def train(self, kwargs):
self.reset_meter()
self.model.train()
train_data = kwargs['train_data']
for data in tqdm(train_data):
x, y = data
y = y.long()
if opt.use_gpu:
x = x.cuda()
y = y.cuda()
x, y = Variable(x), Variable(y)
# Forward.
score, _ = self.model(x)
loss = self.criterion(score, y)
# Backward.
self.optimizer.zero_grad()
loss.backward()
# Clip gradient.
nn.utils.clip_grad_norm(self.model.parameters(), 5)
self.optimizer.step()
self.metric_meter['loss'].add(loss.data[0])
# Update to tensorboard.
if (self.n_iter + 1) % opt.plot_freq == 0:
self.writer.add_scalar('perplexity', np.exp(self.metric_meter['loss'].value()[0]), self.n_plot)
self.n_plot += 1
self.n_iter += 1
# Log the train metrics to dict.
self.metric_log['perplexity'] = np.exp(self.metric_meter['loss'].value()[0])
def test(self, kwargs):
"""Set beginning words and predicted length, using model to generate texts.
Returns:
predicted generating text
"""
self.model.eval()
begin = np.array([i for i in kwargs['begin']])
begin = np.random.choice(begin, size=1)
text_len = kwargs['predict_len']
samples = [self.convert.word_to_int(c) for c in begin]
input_txt = torch.LongTensor(samples)[None]
if opt.use_gpu:
input_txt = input_txt.cuda()
input_txt = Variable(input_txt)
_, init_state = self.model(input_txt)
result = samples
model_input = input_txt[:, -1][:, None]
for i in range(text_len):
out, init_state = self.model(model_input, init_state)
pred = pick_top_n(out.data)
model_input = Variable(torch.LongTensor(pred))[None]
if opt.use_gpu:
model_input = model_input.cuda()
result.append(pred[0])
# Update generating txt to tensorboard.
self.writer.add_text('text', self.convert.arr_to_text(result), self.n_plot)
self.n_plot += 1
print(self.convert.arr_to_text(result))
def predict(self, begin, predict_len):
self.model.eval()
samples = [self.convert.word_to_int(c) for c in begin]
input_txt = torch.LongTensor(samples)[None]
if opt.use_gpu:
input_txt = input_txt.cuda()
input_txt = Variable(input_txt)
_, init_state = self.model(input_txt)
result = samples
model_input = input_txt[:, -1][:, None]
for i in range(predict_len):
out, init_state = self.model(model_input, init_state)
pred = pick_top_n(out.data)
model_input = Variable(torch.LongTensor(pred))[None]
if opt.use_gpu:
model_input = model_input.cuda()
result.append(pred[0])
text = self.convert.arr_to_text(result)
print('Generate text is: {}'.format(text))
with open(opt.write_file, 'a') as f:
f.write(text)
def load_state_dict(self, checkpoints):
self.model.load_state_dict(torch.load(checkpoints))
def get_best_model(self):
if self.metric_log['perplexity'] < self.best_metric:
self.best_model = deepcopy(self.model.state_dict())
self.best_metric = self.metric_log['perplexity']
def train(**kwargs):
opt._parse(kwargs)
torch.cuda.set_device(opt.ctx)
convert = TextConverter(opt.txt, max_vocab=opt.max_vocab)
train_data = get_data(convert)
char_rnn_trainer = CharRNNTrainer(convert)
char_rnn_trainer.fit(train_data=train_data,
epochs=opt.max_epoch,
begin=opt.begin,
predict_len=opt.predict_len)
def predict(**kwargs):
opt._parse(kwargs)
torch.cuda.set_device(opt.ctx)
convert = TextConverter(opt.txt, max_vocab=opt.max_vocab)
char_rnn_trainer = CharRNNTrainer(convert)
char_rnn_trainer.load_state_dict(opt.load_model)
char_rnn_trainer.predict(opt.begin, opt.predict_len)
if __name__ == '__main__':
import fire
fire.Fire()


















 2667
2667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











