







我们先来看一首诗。
深宫有奇物,璞玉冠何有。
度岁忽如何,遐龄复何欲。
学来玉阶上,仰望金闺籍。
习协万壑间,高高万象逼。
这是一首藏头诗,每句诗的第一个字连起来就是“深度学习”。想必你也猜到了,这首诗就是使用深度学习写的!本章我们将学习一些自然语言处理的基本概念,并尝试自己动手,用RNN实现自动写诗。
9.1 自然语言处理的基础知识
自然语言处理(Natural Language Processing,NLP)是人工智能和语言学领域的分支学科。自然语言处理是一个很宽泛的学科,涉及机器翻译、句法分析、信息检索等诸多研究方向。由于篇幅的限制,本章重点讲解自然语言处理中的两个基本概念:词向量(Word Vector)和循环神经网络(Recurrent Neural Network,RNN)。
9.1.1 词向量
自然语言处理主要研究语言信息,语言(词、句子、篇章等)属于人类认知过程中产生的高层认知抽象实体,而语音和图像属于较低层的原始输入信号。语音、图像数据表达不需要特殊的编码,并且有天生的顺序性和关联性,近似的数字会被认为是近似的特征。正如图像是由像素组成,语言是由词或字组成,可以把语言转换为词或字表示的集合。
然而,不同于像素的大小天生具有色彩信息,词的数值大小很难表征词的含义。最初,人们为了方便,采用One-Hot编码格式。以一个只有10个不同词的语料库为例(这里只是举个例子,一般中文语料库的字平均在8000 ~ 50000,而词则在几十万左右),我们可以用一个10维的向量表示每个词,该向量在词下标位置的值为1,而其他全部为0。示例如下:
第1个词:[1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
第2个词:[0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
第3个词:[0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
……
第10个词:[0, 0, 0, 0, 0, 0, 0, 0, 0, 1]
这种词的表示方法十分简单,也很容易实现,解决了分类器难以处理属性(Categorical)数据的问题。它的缺点也很明显:冗余太多、无法体现词与词之间的关系。可以看到,这10个词的表示,彼此之间都是相互正交的,即任意两个词之间都不相关,并且任何两个词之间的距离也都是一样的。同时,随着词数的增加,One-Hot向量的维度也会急剧增长,如果有3000个不同的词,那么每个One-Hot词向量都是3000维,而且只有一个位置为1,其余位置都是0,。虽然One-Hot编码格式在传统任务上表现出色,但是由于词的维度太高,应用在深度学习上时,常常出现维度灾难,所以在深度学习中一般采用词向量的表示形式。
词向量(Word Vector),也被称为词嵌入(Word Embedding),并没有严格统一的定义。从概念上讲,它是指把一个维数为所有词的数量的高维空间(几万个字,几十万个词)嵌入一个维度低得多的连续向量空间(通常是128或256维)中,每个单词或词组被映射为实数域上的向量。
词向量有专门的训练方法,这里不会细讲,感兴趣的读者可以学习斯坦福的CS224系列课程(包括CS224D和CS224N)。在本章的学习中,读者只需要知道词向量最重要的特征是相似词的词向量距离相近。每个词的词向量维度都是固定的,每一维都是连续的数。举个例子:如果我们用二维的词向量表示十个词:足球、比赛、教练、队伍、裤子、长裤、上衣和编织、折叠、拉,那么可视化出来的结果如下所示。可以看出,同类的词(足球相关的词、衣服相关的词、以及动词)彼此聚集,相互之间的距离比较近。
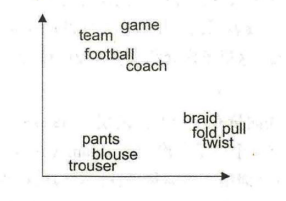
可见,用词向量表示的词,不仅所用维度会变少(由10维变成2维),其中也会包含更合理的语义信息。除了相邻词距离更近之外,词向量还有不少有趣的特征,如下图所示。虚线的两端分别是男性词和女性词,例如叔叔和阿姨、兄弟和姐妹、男人和女人、先生和女士。可以看出,虚线的方向和长度都差不多,因此可以认为vector(国王) - vector(女王) ≈ vector(男人) - vector(女人),换一种写法就是vector(国王) - vector(男人) ≈ vector(女王) - vector(女人),即国王可以看成男性君主,女王可以看成女性君主,国王减去男性,只剩下君主的特征;女王减去女性,也只剩下君主的特征,所以这二者相似。

英文一般是用一个向量表示一个词,也有使用一个向量表示一个字母的情况。中文同样也有一个词或者一个字的词向量表示,与英文采用空格来区分词不同,中文的词与词之间没有间隔,因此如果采用基于词的词向量表示,需要先进行中文分词。
这里只对词向量做一个概括性的介绍,让读者对词向量有一个直观的认知。读者只需要掌握词向量技术用向量表征词,相似词之间的向量距离近。至于如何训练词向量,如何评估词向量等内容,这里不做介绍,感兴趣的读者可以参看斯坦福大学的相关课程。
在PyTorch中,针对词向量有一个专门的层nn.Embedding,用来实现词与词向量的映射。nn.Embedding具有一个权重,形状是(num_words,embedding_dim),例如对上述例子中的10个词,每个词用2维向量表征,对应的权重就是一个10 * 2的矩阵。Embedding的输入形状是N * W,N是batch size,W是序列的长度,输出的形状是N * W * embedding_dim。输入必须是LongTensor,FloatTensor必须通过tensor.long()方法转成LongTensor。举例如下:
#coding:utf8
import torch as t
from torch import nn
embedding = t.nn.Embedding(10, 2) # 10个词,每个词用2维词向量表示
input = t.arange(0, 6).view(3, 2).long() # 3个句子,每个句子有2个词
input = t.autograd.Variable(input)
output = embedding(input)
print(output.size())
print(embedding.weight.size())
输出是:
(3L, 2L, 2L)
(10L, 2L)
需要注意的是,Embedding的权重也是可以训练的,既可以采用随机初始化,也可以采用预训练好的词向量初始化。
9.1.2 RNN
RNN的全称是Recurrent Neural Network,在深度学习中还有一个Recursive Neural Network也被称为RNN,这里应该注意区分,除非特殊说明,我们所遇到的绝大多数RNN都是指前者。在用深度学习解决NLP问题时,RNN几乎是必不可少的工具。假设我们现在已经有每个词的词向量表示,那么我们将如何获得这些词所组成的句子的含义呢?我们无法单纯地分析一个词,因此每一个词都依赖于前一个词,单纯地看某一个词无法获得句子的信息。RNN则可以很好地解决这个问题,通过每次利用之前词的状态(hidden state)和当前词相结合计算新的状态。
RNN的网络结构图如下所示。
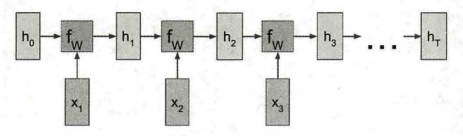
- x 1 , x 2 , x 3 , . . . , x T x_1,x_2,x_3,...,x_T x1,x2,x3,...,xT:输入词的序列(共有 T T T个词),每个词都是一个向量,通常用词向量表示。
- h 0 , h 1 , h 2 , h 3 , . . . , h T h_0,h_1,h_2,h_3,...,h_T h0,h1,h2,h3,...,h
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 605
605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









