








文章目录
Pre-Neural Machine Translation
机器翻译
- 机器翻译(MT)是将一个句子 x 从一种语言( 源语言 )转换为另一种语言( 目标语言 )的句子 y 的任务。
- 1950s: Early Machine Translation
将俄语翻译成英语(motivated by冷战)
基本是基于规则的,使用双语词典将俄语单词与英语单词对应起来 - 1990s-2010s: Statistical Machine Translation
- 核心思想:从数据中学习一个概率模型
- 假设给定法语句子x,要找到最优的英语翻译y,
a
r
g
m
a
x
y
P
(
y
∣
x
)
argmax_yP(y|x)
argmaxyP(y∣x)
使用贝叶斯法则将式子分成两部分,一部分为翻译模型,一部分为语言模型。

翻译模型:对单词和短语如何转化建模(忠实度),从平行语料中学习
语言模型:对如何写出好的英语句子建模(流利度),从单语语料中学习
翻译模型
- 语言模型之前已经介绍过了,比较简单,而翻译模型很难。
- 因为源语言句子和目标语言句子长度不一定相同,所以就会涉及到单词或短语的对齐问题。有一对多,多对一,一对NULL,NULL对有,等等。
- IBM提出了五个经典的翻译模型,前三个是基于单词的,后两个是基于短语的。由于时间以及篇幅,还有本人也没有完全搞懂,所以这里就不深入研究了。本课中也未深入讲解,有兴趣同学可以查阅资料。
Neural Machine Translation
- 神经机器翻译(NMT)是用单神经网络进行机器翻译的一种方法。
- 神经网络结构称为sequence-to-sequence (也称为seq2seq),它包含两个rnn。

seq2seq架构包含两个RNN,一个用作编码器,对输入序列进行编码获得其表示。一个用作解码器,编码器最终的隐藏层输出作为解码器的起始输入,最终生成目标句子。上图中解码器部分是test时的架构(将当前时间步的输出当作下一个时间步的输入) - seq2seq是多功能的
- 不仅在MT中有用,在许多NLP任务中都有作用
文本摘要( long text → short text)
对话系统(previous utterances → next utterance)
解析(input text → output parse as sequence)
代码生成(natural language → Python code)
- 不仅在MT中有用,在许多NLP任务中都有作用
- seq2seq模型是条件语言模型的一个例子。
- 语言模型:因为解码器预测目标句子y的下一个词
- 条件性:因为预测是基于源语言x的
- NMT直接计算
p
(
y
∣
x
)
p(y|x)
p(y∣x)

How to train a NMT system?
首先需要获取一个大的平行语料

如上图,seq2seq训练过程与测试过程不同。在训练过程中,解码器部分每个时间步输入是目标序列,而每个时间步的正确结果为下一个时间步的输入,损失函数使用交叉熵即可。
搜素策略
Greedy decoding

- 在解码器的每个时间步使用argmax来生成(或“解码”)目标语句,即每步都选择概率最大的一个词
- 这样会出现一些问题

贪婪解码没有方法去撤销每一步的决定
如何解决呢?
Exhaustive search decoding
- 理想情况下,我们要找到一个翻译y能够最大化
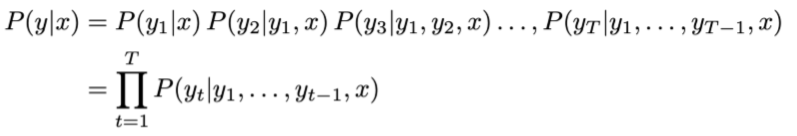
- 穷举搜索解码,顾名思义,就是将每步的所可能性都记录下来,这样就能计算所有可能的目标句子y
- 这就意味着在解码器的第 t 步,我们要跟踪 V t V^t Vt种可能的部分翻译,这里V是词表大小
- 复杂度为 O ( V T ) O(V^T) O(VT),计算量太大了。
Beam search decoding
-
核心思想:在解码器的每一步,只跟踪前 k 种最有可能的部分翻译,我们称之为假设。k 是 beam size(实际中大约为5~10)
-
一个假设的得分是其对数概率
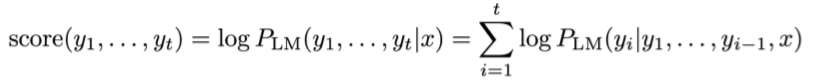
所有分数都是负的,越高越好
在每个时间步,我们搜索高分的假设,跟踪前 k 个 -
Beam search 不保证找到最优解,但是比穷尽搜索更加有效
-
例子




中间过程省略,得到最终结果为

然后回溯找到最优解

-
停止条件:
- 在greedy docoding中,经常解码得到<END>时停止
- 在beam search中,不同的假设可能在不同的时间步产生<END>
- 当一个假设产生<END>,这个假设就完整了
- 将它放到一边,然后继续通过beam search搜索其他假设
- 通常,在以下情况发生时,停止
- 到达时间步T(T是提前设定好的截止值),或者
- 当我们至少含有 n 个完整的假设(n也是提前设定好的戒指值)
-
选择哪个作为最终的翻译?
- 停止后,我们有一个假设的列表
- 每个假设
y
1
,
y
2
,
⋅
⋅
⋅
,
y
t
y_1, y_2, ···, y_t
y1,y2,⋅⋅⋅,yt都有一个分数
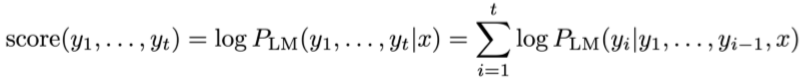
如果单纯选择分数最高的一个有些问题,因为越长的假设分数越低,偏向于选择较短的假设。 - 因此,按长度先正则化,然后选择最优的假设:

NMT的优缺点
- Advantages of NMT
比起SMT,NMT有很多优点- 更好的效果:更加流利、对上下文利用更充分、对短语相似性利用更加充分
- 到端优化的单一神经网络,没有要单独优化的子组件
- 需要更少的人力工程:无特征工程,对所有语言对使用相同的方法
- Disadvantages of NMT
比起SMT- NMT缺乏可解释性:很难去debug
- NMT很难控制:例如,无法轻松指定翻译规则或指导原则,安全问题
MT的评价
-
BLEU(Bilingual Evaluation Understudy)
BLEU通过比较机器翻译和人工翻译,并基于n-gram精确率(通常使用1,2,3和4-grams),再加上对太短句子翻译的惩罚,计算出一个相似性分数。 -
BLEU很有用但不完美
- 翻译一个句子有很多有效的方法
- 因此,一个好的翻译可能得到一个很差的BLEU分数,因为它与人类翻译有很低的n-gram重叠
-
MT的进步历程

NMT是NLP深度学习的最大成功案例 -
神经机器翻译从2014的边缘研究活动到2016的领先标准方法。
- 2014年,第一篇seq2seq论文发表
- 2016年,谷歌翻译从SMT转为NMT
-
这很令人惊奇
SMT系统是由数百名工程师多年来建造的,其性能在几个月内被少数工程师训练的NMT系统超越。
那么机器翻译问题解决了吗?
- 并没有
- 还有很多问题等着去解决
- 词汇量不足的词
- 训练与试验数据之间的域不匹配
- 在较长文本上维护上下文
- 缺乏资源的语言对
- NMT在训练数据继承了偏差

- 不可解释的系统有时候会做奇怪的事

NMT研究还在继续
- NMT是NLP深度学习的旗舰任务
- NMT研究开创了NLP深度学习的许多最新创新
- 研究人员对基础RNN提出了很多的改进,比如其中之一就是ATTENTION注意力机制
Attention
瓶颈问题

编码器需要将整个源语言句子的编码集中到最后一个隐藏层的输出中,这就产生了一个信息瓶颈。
Attention
-
注意力机制提供了一个解决这个问题的方法
-
核心思想:在解码器的每个时间步,让其与编码器的某些时间步直接连接来更加关注源语言句子的某些特定部分。
-
以下是解码过程的图示












-
用等式来描述:
- 编码器隐藏层状态 h 1 , h 2 , ⋅ ⋅ ⋅ , h N ∈ R h h_1, h_2, ···, h_N \in R^h h1,h2,⋅⋅⋅,hN∈Rh
- 在时间步 t ,解码器隐藏层状态 s t ∈ R h s_t \in R^h st∈Rh
- 在这一步中,获得attention scores
e
t
e^t
et (使用点乘)
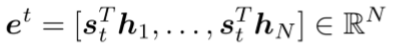
- 然后使用softmax获得attention distribution
α
t
\alpha^t
αt
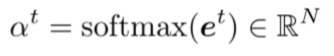
- 以
α
t
\alpha^t
αt作为权重,使用编码器隐藏状态的加权和来获得注意力输出
α
t
\alpha_t
αt
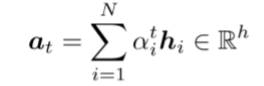
- 最后,将注意力输出
α
t
\alpha_t
αt与解码器隐藏层状态
s
t
s_t
st拼接在一起,根据无注意力机制的seq2seq模型进行处理
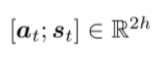
注意力机制非常棒
- 显著的提高了NMT的性能
- 让解码器关注输入的某些特定部分非常有用
- 注意力解决了瓶颈问题
- 注意力允许解码器直接查看输入;绕过了瓶颈
- 注意力有助于解决消失梯度问题
- 提供通往遥远状态的瓶颈
- 注意力提供了一些可解释性
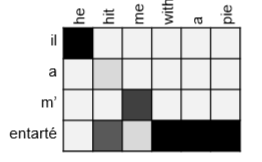
- 通过观察注意分布,我们可以看到解码器关注的是什么
- 我们免费获得(soft)对齐!
- 这很棒,因为我们从未明确训练过对齐系统,这个网络自动学习了对齐
Attention is a general Deep Learning technique
- 不仅在MT中有用,在一些其他NLP任务中也很有用。
- 注意力的更一般定义
给定一组向量值和一个查询向量,注意力是一种根据查询计算值的加权和的技术。(在MT例子中,这里的值指编码器输出,查询向量指解码器每个时间步的隐藏层状态) - 我们有时候说:query attends to the values
例如:在seq2seq + attention模型中,每一个解码器隐藏状态(query)关注所有的编码器隐藏层状态(values) - 直观上:
- 加权和是对值包含的信息的一个选择性摘要,而query决定关注哪些值
- 注意力是一种获得任意表示集(值)的固定大小表示的方法,依赖于某些其他表示(查询)。
注意力机制分为下面三个步骤

几种attention变体
上述三种方法中,第一种需要两者维度相同,直接使用点乘即可。
第二种是先使用一个权重矩阵将value维度转化成与query相同然后再做点乘。
第三种是将value和query都通过权重矩阵转化成一个特定维度(attention dimensionality是一个超参数),然后再经过一个tanh非线性函数,最后乘以一个权重矩阵。
总结
- 学习了MT的历史(SMT较难,未深入介绍)
- 自2014年以来,神经机器翻译迅速取代了复杂的统计机器翻译
- seq2seq架构
- 注意力机制是一种关注特定某部分输入的方法,对seq2seq系统提高很多















 649
649











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









