







前言:图像分类是CV领域相对比较成熟的一种技术,一般从基础开始学就是Tensorflow——>CNN——>手撸ResNet等算法——>迁移学习。
Tensorflow.keras.applications中有很多迁移学习的算法,只需要加载后下载参数,然后fine_tune稍微训练最后几层,就可以获得非常不错的效果。
本文主要是通过一系列代码指导大家如何完成迁移学习的使用。
一、导入数据,制作dataset
因为是图片,所以我们首先就是需要把图片转换成Tensorflow能理解的向量形式。另外因为图片的数量多了以后,处理效率会变慢,所以一般都要做成数据集(dataset),然后设置batch_size(32或64)。
如上,一般有2种做法:
第一种是通过tf.io.read_file(文件路径),然后tf.image.decode_jpeg解析成向量,最后通过tf.data.Datasets.from_tensor_slices()转化成dataset,这种方式比较麻烦,但是稳定;
第二种是直接使用tf.keras.preprocessing.image_dataset_from_directory加载,这种方式的好处是:如果训练集或验证集中的图片是分类存放在不同的文件夹内,且文件夹名称就是类别(或可标识),那么通过这种方式就可以直接转成dataset,非常方便。
import tensorflow as tf
from tensorflow.keras.preprocessing import image_dataset_from_directory
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
import warnings
warnings.filterwarnings('ignore')
#数据所在文件夹
base_dir = './dataset'
train_dir = os.path.join(base_dir, 'train')
valid_dir = os.path.join(base_dir, 'valid')
test_dir = os.path.join(base_dir, 'test')
test2_dir = os.path.join(base_dir, 'test2')
BATCH_SIZE = 32
IMG_SIZE = (160, 160)
#image_dataset_from_directory根据目录结构自动分类,工业上比较可以迭代
train_dataset = image_dataset_from_directory(train_dir,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
valid_dataset = image_dataset_from_directory(valid_dir,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
test_dataset = image_dataset_from_directory(test_dir,
batch_size=BATCH_SIZE,
shuffle=False, #默认是True,最后核对会比较麻烦
image_size=IMG_SIZE)
#【重要】获取分类名称,这个最后会用到
class_names = train_dataset.class_names
print(class_names)
#开辟一个固定内存,动态和batch_size一致
train_dataset = train_dataset.prefetch(buffer_size=BATCH_SIZE)
valid_dataset = valid_dataset.prefetch(buffer_size=BATCH_SIZE)
test_dataset = test_dataset.prefetch(buffer_size=BATCH_SIZE)

#实际工作中,还有一种可能性是测试集是放在一个大文件夹里的,
#这时候就没法用image_dataset_from_directory,所以就需要根据绝对路径汇总并制作dataset
test2_name_list = os.listdir('./dataset/test2/')
test2_path_list = ['./dataset/test2/'+x for x in test2_name_list]
def load_and_process_image(img_path):
'''把单个图片解析并预处理'''
img_raw = tf.io.read_file(img_path) #读文件
img_tensor = tf.image.decode_jpeg(img_raw, channels=3) #解析成向量
img_tensor = tf.image.resize(img_tensor, [160, 160]) #调整向量维度
#因为需要和image_dataset_from_directory制作的dataset维度一致,所以增加一维
img_tensor = tf.expand_dims(img_tensor, axis=0)
img_tensor = tf.cast(img_tensor, dtype=tf.float32) #转成tf格式
return img_tensor
test2_dataset = tf.data.Dataset.from_tensor_slices(test2_path_list).map(load_and_process_image)
#查看训练数据(非必须)
plt.figure(figsize=(10,10))
for images, labels in train_dataset.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i+1)
plt.imshow(images[i].numpy().astype('uint8'))
plt.title(class_names[labels[i]])
plt.axis('off')

二、数据增强
#数据增强
data_augmentation = tf.keras.Sequential([
tf.keras.layers.experimental.preprocessing.RandomFlip('horizontal'),#水平翻转
tf.keras.layers.experimental.preprocessing.RandomRotation(30), #随机旋转
])
#展示数据增强的结果(非必须)
for image, _ in train_dataset.take(1):
plt.figure(figsize=(10,10))
first_image = image[0]
for i in range(9):
ax = plt.subplot(3,3, i+1)
augmented_image = data_augmentation(tf.expand_dims(first_image, 0))
plt.imshow(augmented_image[0] / 255)
plt.axis('off')

三、使用预训练模型构建基础模型
#获取预训练模型对输入的预处理方法
preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input
#数据标准化
rescale = tf.keras.layers.experimental.preprocessing.Rescaling(1./127.5, offset=-1)
#创建预训练模型
IMG_SIZE = IMG_SIZE + (3,) #(160, 160, 3)
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SIZE,
include_top=False, #是否包含顶层的全连接层
weights='imagenet')
#迁移学习主流程代码,开始利用预训练的MobileNet创建模型
inputs = tf.keras.Input(shape=(160, 160, 3))
#数据增强
x = data_augmentation(inputs)
#数据预处理
x = preprocess_input(x)
#模型
x = base_model(x, training=False) #参数不变化
#全局池化
x = tf.keras.layers.GlobalAveragePooling2D()(x)
#Dropout
x = tf.keras.layers.Dropout(0.2)(x)
#输出层
outputs = tf.keras.layers.Dense(3)(x)
#整体封装
model = tf.keras.Model(inputs, outputs)
四、训练模型
# Fine tuning
base_model.trainable = True
#模型一共154层,对最后54层进行微调
fine_tune_at = 100
for layer in base_model.layers[:fine_tune_at]:
layer.trainable = False
model.summary()

model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(lr=0.0001),
metrics=['accuracy'])
#迭代式微调训练
history_fine = model.fit_generator(train_dataset,
epochs=20,
validation_data=valid_dataset)
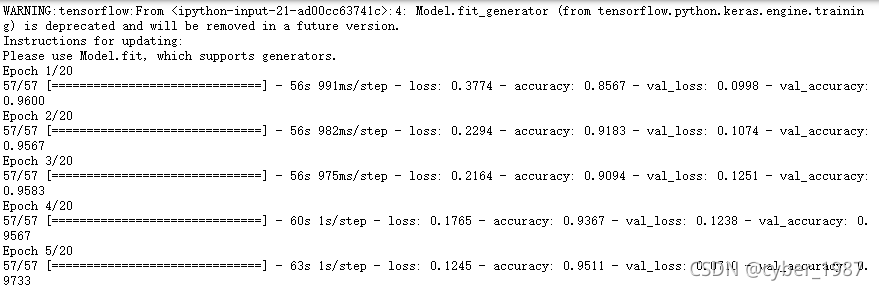
从训练第一轮开始,验证集准确率就已经达到96%,后面更多地是在提高稳定性,逐步提升效果。
我最后训练了11轮,train_accuracy是95.89%,val_accuracy是97.67%
五、查看模型效果
#查看测试集结果
loss, accuracy = model.evaluate(test_dataset)
print(loss)
print(accuracy)

测试集的效果可以直接达到97.5%,泛化性能非常不错
# 迭代式获取数据信息
image_batch, label_batch = test_dataset.as_numpy_iterator().next()
# 预测结果
predictions = model.predict_on_batch(image_batch)
# 直接argmax查看数据
predictions = tf.argmax(predictions, axis=1)
# 获取标签
print('Predictions:\n', predictions.numpy())
print('Labels:\n', label_batch)
# 画图
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].astype("uint8"))
plt.title(class_names[predictions[i]])
plt.axis("off")

六、对测试集(test2)进行预测
#对test2进行预测
test2_predict = model.predict(test2_dataset)
test2_predict2 = np.argmax(test2_predict, axis=-1)
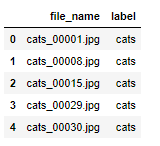
final_test2_predict = [class_names[x] for x in test2_predict2]
output_df = pd.DataFrame({'file_name':test2_name_list, 'label':final_test2_predict})
output_df.head()
output_df.to_csv('cyber_predict.csv', index=False)

















 1463
1463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









