






1、self-attention时,为什么要对的值进行scaled,即除以
,其中dk是词向量/隐藏层的维度。
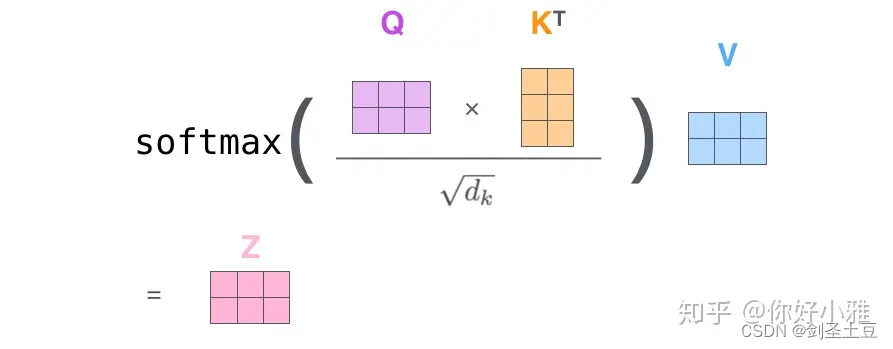
其原因有如下两点:
1、防止softmax的输入过大,导致偏导数趋近于0,除以该值可以保证梯度稳定回传
2、因为可以使得Q∗ K的结果满足期望为0,方差为1的分布,类似于归一化
2、为什么Q和K使用不同的权重矩阵生成,而非使用同一个值及逆行自身的点乘?
K和Q的点乘是为了得到一个attention score矩阵,用来对V进行提纯。使用不同的权重矩阵计算是为了在不同的空间上进行投影,增强模型表达能力,提高score矩阵的泛化性。如果使用统一矩阵生成,则会引入对称性的问题,因为QK矩阵被投影到了同一个维度空间。
3、在计算attention时为什么选择点乘而非加法?两者在复杂度和效果上有无差别?
使用加法计算attention会更快,但是作为一个整体计算attention的时候,相当于一个隐层,整体计算量与点积相似。而从效果来看,二者效果与dk
有关,dk越大加法的效果越显著
4、在计算attention score时,如何对padding做mask操作的?
由于padding都是0, 在计算时e^0 = 1使用softmax会导致padding的值也会占全局一定的概率,因此,使用mask的目的就是让这部分的值无穷小,让他在softmax之后基本为0从而保证不影响attention socre的分布。
5、如何进行mask
在计算
后,加上一个矩阵M,其元素为0或-inf(来自:Transformer结构详解 - 知乎)。还有其他实现
6、Transformer如何使用多头注意力机制的?为什么不使用一个头?

多头注意力机制从直觉上的解释其实类似于CNN中的多核,关注不同子空间的信息来捕捉更加丰富的特征信息。它扩展了模型专注于不同位置的能力,它为关注层提供了多个“表示子空间”。
有文章证明确实使用一个头的效果可能真的不够https://www.zhihu.com/question/341222779
本质就是bagging的集成思想,可以聚合更多的子空间信息
7、残差结构与LN。为什么使用LN而非BN,LN在transformer的位置时哪里,BN的使用场景与LN的区别
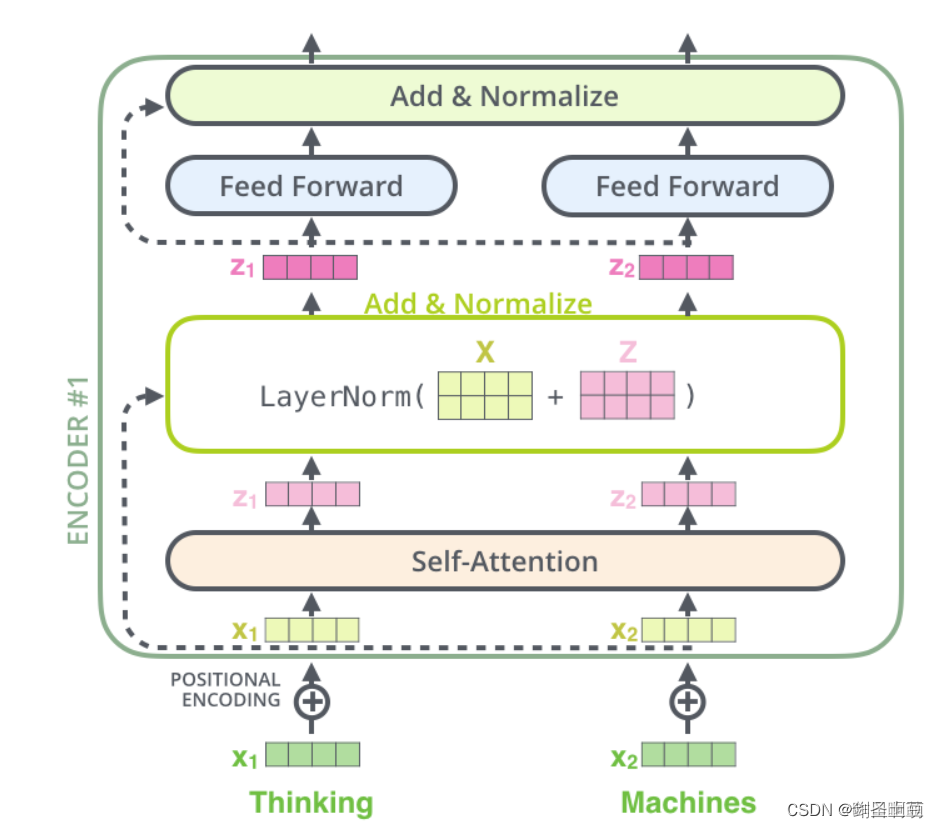
- BatchNorm是对列做操作,对每一列求均值和方差(求的是同一特征下,不同样本的统计量),然后规范化;
- LayerNorm是对行做操作,对每一行求均值和方差(求的是同一样本下,不同特征的统计量),然后规范化。
BN 一般在MLP和CNN上有较好的表现,在RNN模型中表现较差。这是因为BN时对每个特征在每个batch size上求均值和方差。而LN则是对整个文本长度求均值和方差。
而残差结构可以防止梯度消失,帮助深层网络进行训练。
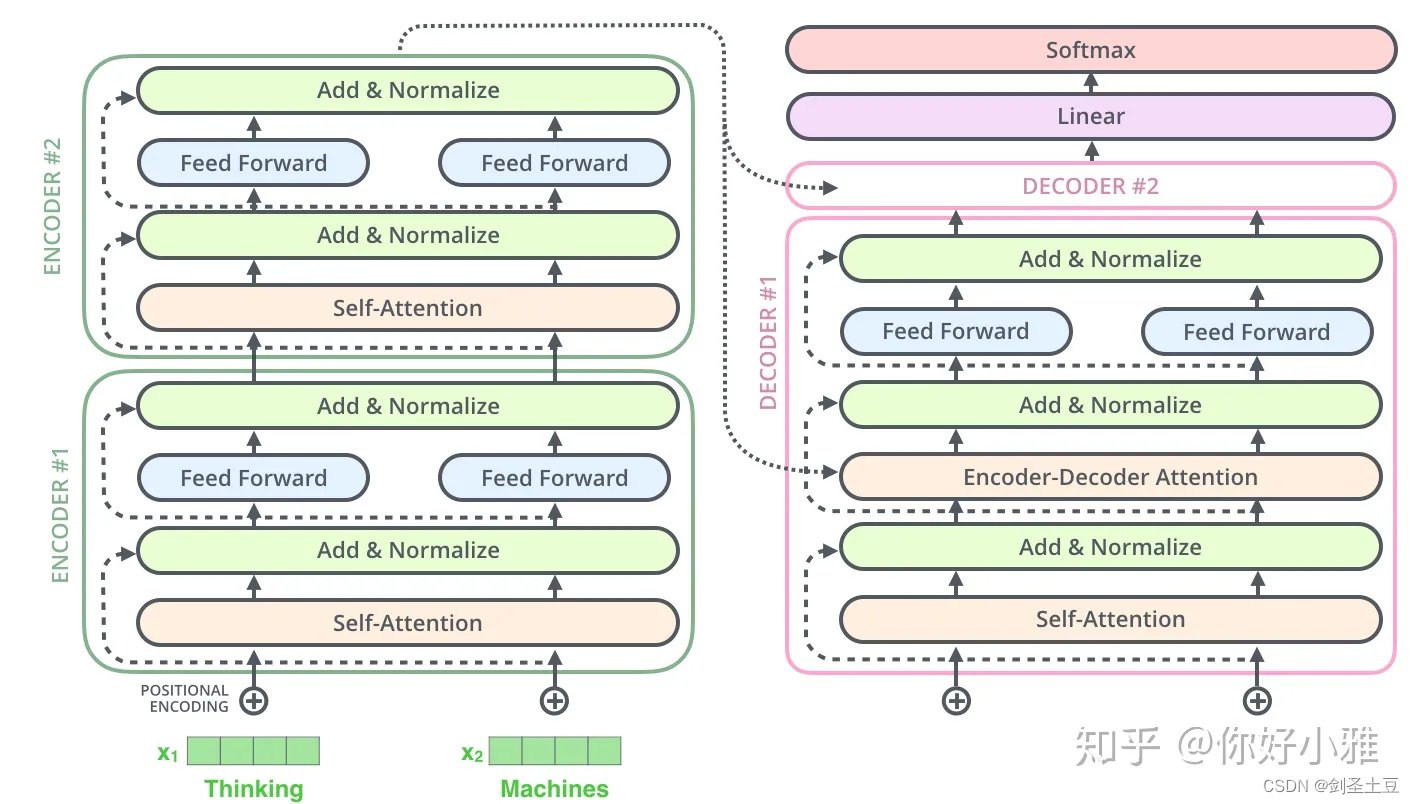
8、encoder-decoder的链接部分Q、K、V是分别来自哪里?
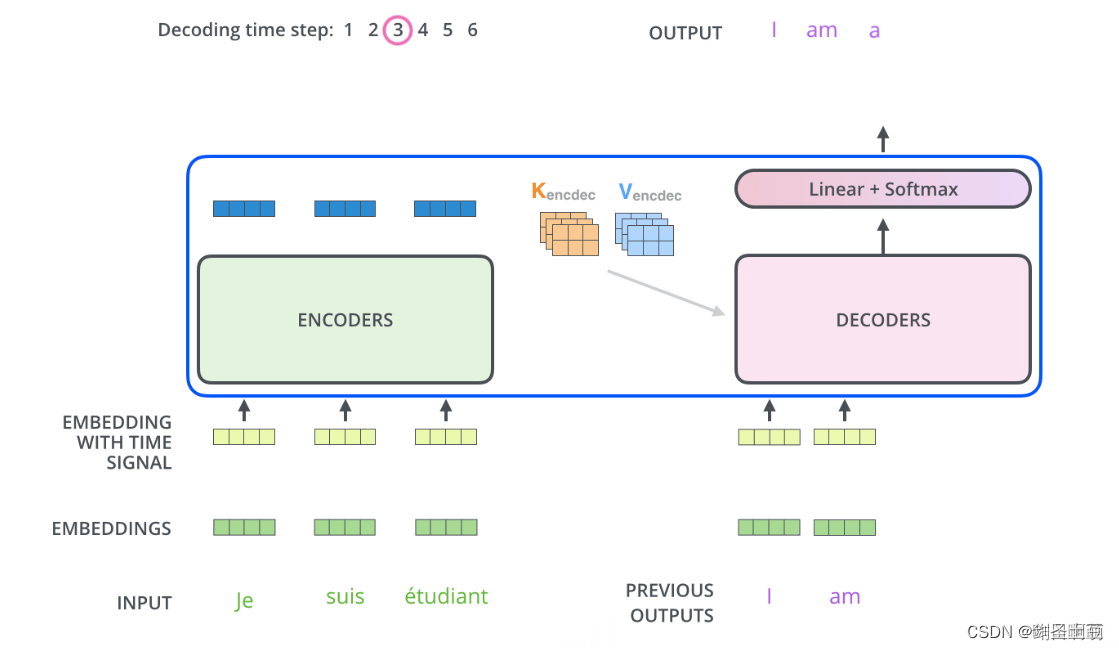
Q是来自decoder上一个block产生的矩阵结果,K和V是来自encoder
10、训练与预测
训练时:第i个decoder的输入 = encoder输出 + ground truth embeding
预测时:第i个decoder的输入 = encoder输出 + 第(i-1)个decoder输出















 2556
2556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









