






Transformer 学习总结
总体介绍
论文链接
https://arxiv.org/pdf/1706.03762.pdf
Transformer其实就是由融合了注意力机制的编码器和解码器组成,如下图Transformer的总体模型框架。
编码器将输入的句子变成机器学习可以理解的特征向量,并输入到解码器中作为 Keys 和 Values(解码器就直接根据输入获取query,然后输出结果),而解码器则是通过自回归的方式进行输出结果,自回归就是 t 时刻生成一个结果后,将 t 时刻的输出作为 t+1 时刻输入的一部分放进模型,整个 Transformer 输出就是一个单词一个单词这样输出。
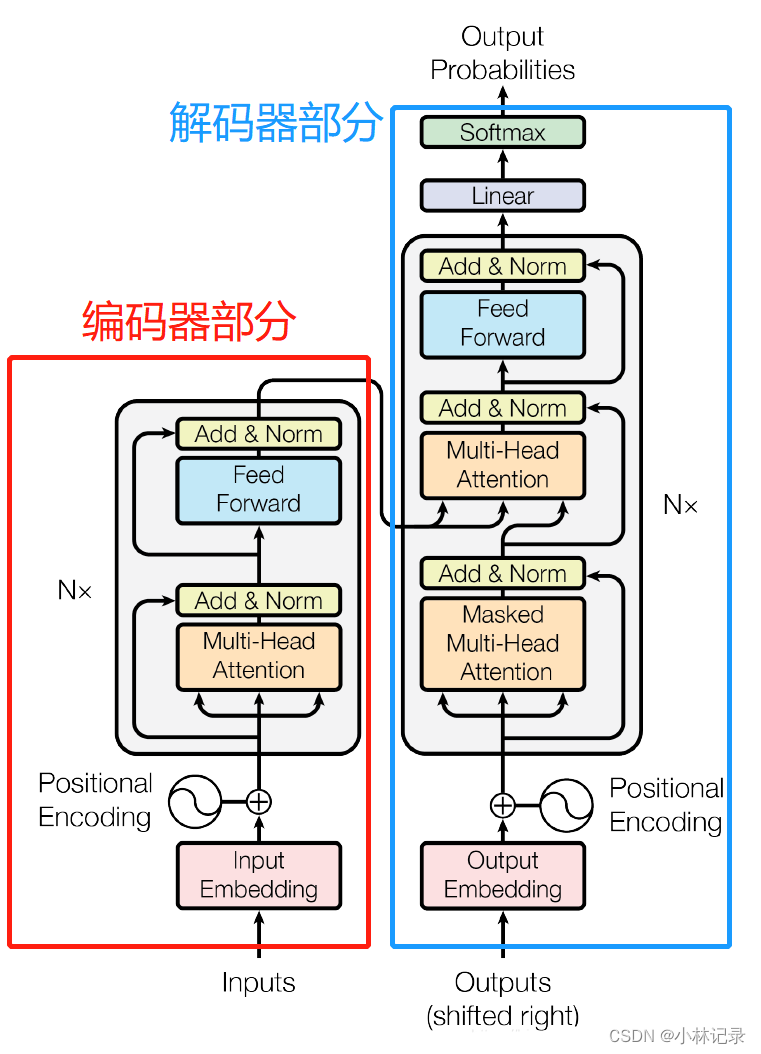
接下来将按顺序分析各部分内容。
编码器部分
编码器和解码器有相当一些结构是一样的,我就放一起介绍。
Input Embedding
(1)位置
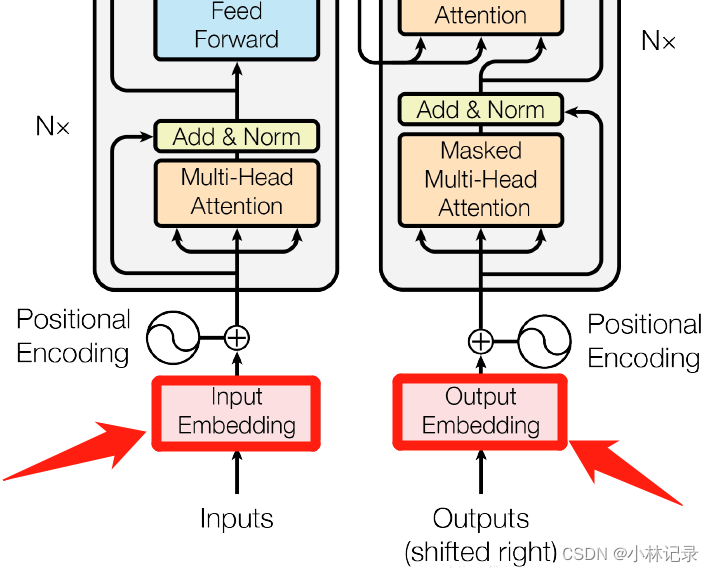
(2)作用
为了将输入的n维信息(如n个字符的中文、n个单词的英文等信息)转换成 n*d 的特征向量进行处理,即将输入的信息映射到一个特征空间。其中,d 为固定的维度(可自己设定),将n个输入信息均分别映射到d维的空间。
(3)组成与原理
其实就是用了线性层(Linear,这里的线性层是在最后一个维度做计算,用pytorch实现的话,直接用Linear就行了,因为pytorch是默认在最后一个维度计算的)和SoftMax。
同时由于SoftMax后的特征向量总和为1,若特征向量维度过多(也就是输入的句子太长的时候)的时候,各维度的数值较小,在与后续的Positional Encoding 相加时难以突出Input Embedding特征信息。因此,论文在SoftMax后乘上了 √d,通过这种方式让Input Embedding 的信息不会在后续计算中被淹没掉。
Positional Encoding
(1)位置

(2)作用
这里我们可以跟RNN做对比,RNN是将 t-1 时刻的输出与 t 时刻的输入融合并输入到网络中,因此 t 时刻输入到网络中的特征是肯定有了 t-1 时刻的信息,即有时序相关,也就是若打乱 Inputs 的顺序,t 时刻输入到网络中的特征信息是不一样的。
而在Transformer中,若没有positional encoding,输入的信息之间没有时序相关,也就是若打乱 Inputs 的顺序在网络后面的Multi-Head Attention 和 Feed Forward(线性层+SoftMax,后面会介绍)部分看来都是一样的。因此,我们需要加入Positional Encoding,来让Input Embedding输出的特征信息之间产生时序相关。
(3)组成与原理
原文中是通过 sin 和 cos 函数直接对每个维度产生位置相关的特征信息并加到原来的特征上。

Multi-Head Attention
(1)位置
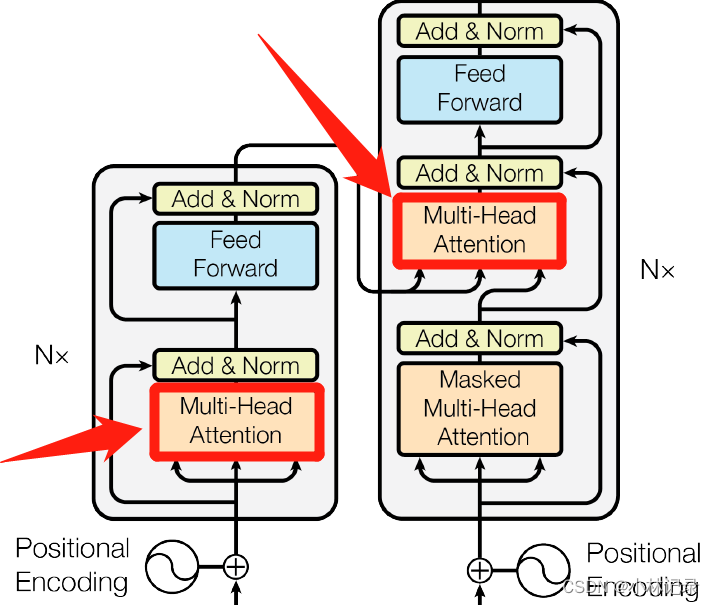
(2)作用
分别增强各个维度的信息,这样就能让输入到 Feed Forward 的各个维度的特征,都融合了整个句子的信息。RNN则是直接把 t-1 时刻的信息与 t 时刻的输入融合,来在 t 时刻的输入中加入 t 时刻以前的信息。
(3)组成与原理
Multi-Head Attention顾名思义可分为Multi-Head和Attention两部分。
①Attention (Scaled Dot-Product Attention)
首先,基础的Attention采用的是Dot-Product Attention,即点乘的Attention方法通过计算Query和Key的相似性来判断Value的权重有多大,每个单词特征通过这样自注意力的方式生成的特征就包含了句子其他的信息,公式可以表示如下:
Attention(Q,K,V) = SoftMax(Q·K^T)·V
其中添加了一个Scaled方法,引入了一个参数 dk 即
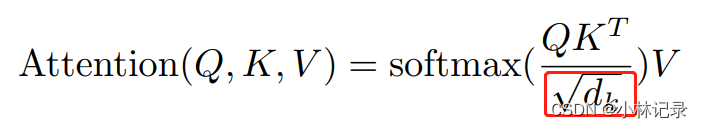
公式中引入dk的作用:
由于某些样本长度太长,直接进行SoftMax的话,会让特征的信息太极端(即靠近1的更逼近1,靠近0的更逼近0),从而导致在训练的过程中,梯度变化太小。因此,论文中说引入这个dk,dk其实就是样本的长度。
②Multi-Head
由于只用一个Attention的话,只能处理较单一的场景数据,比如鸡这个词,在大部分场景中都是肉鸡,鸡肉的鸡,通过单一的注意力机制映射就可以让跟鸡相关的特征数值更大,但是在鸡你太美这句话中,鸡可能就不是指通常意义上的鸡,我们就需要另外一种映射方式来让代表另一些词语的数值更大。但是若直接用多个注意力机制进行计算,计算量又太大。
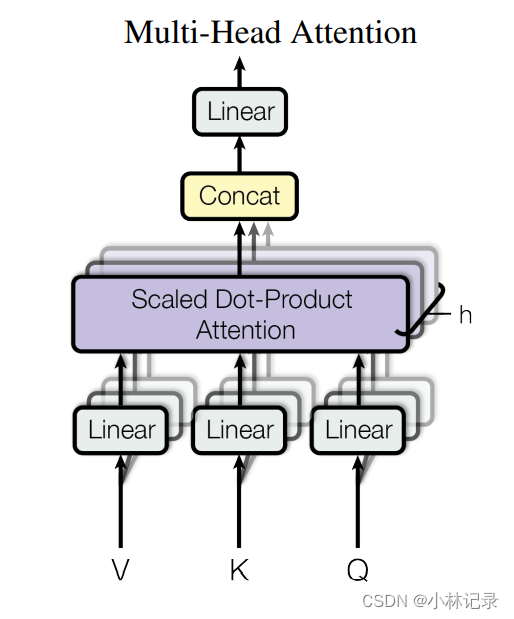
因此,论文提出通过降维来让特征数据量减少,同时增加注意力机制映射,即论文中提出的 Multi-Head,论文中的公式如下,从公式就可以看出通过一个线性层权重W,来进行降维,并将Q、K、V分别映射到不同的特征空间中,然后通过concat拼接起来。同时由于输入是512维,后面需要进行残差相加,所以再通过线性层权重Wo映射回512维。

Add & Norm
(1)位置
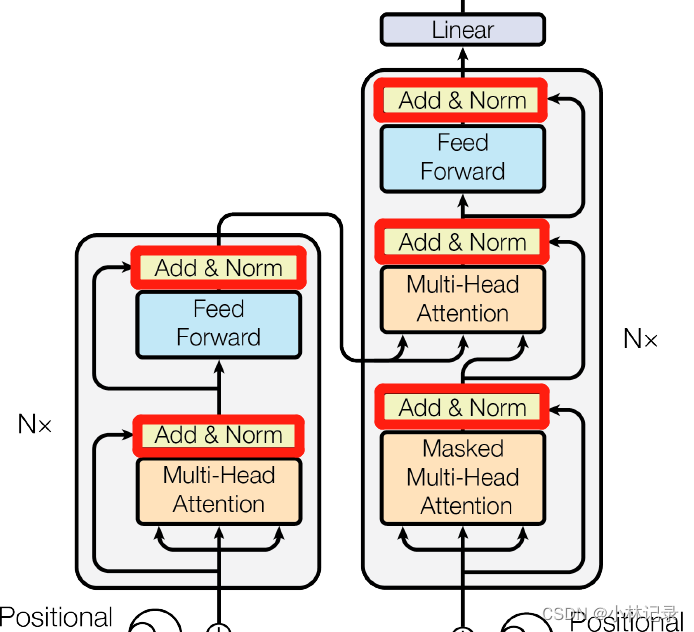
(2)原理
Add也就是残差连接,将输入与输出直接相加。
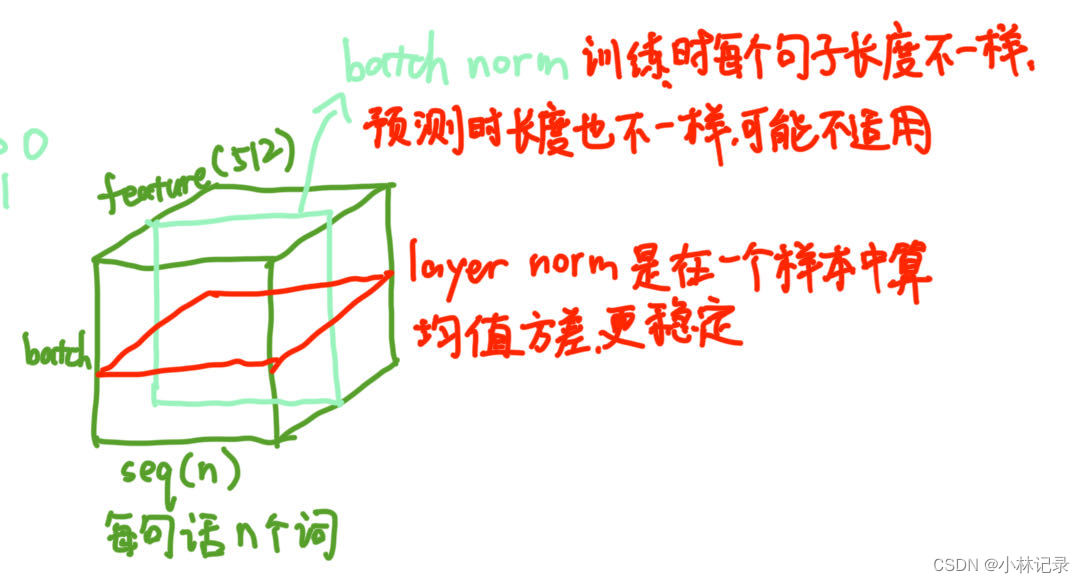
Norm用的是Layer Norm。为什么用Layer Norm而不用Batch Norm呢,因为句子的处理中,每个句子的长短是不一样的。Batch Norm是在同一个Batch中的一个特征维度上进行Normalization,而Layer Norm是对每一个样本的所有特征维度进行Normalization,画了个图如下。
Feed Forward
(1)位置
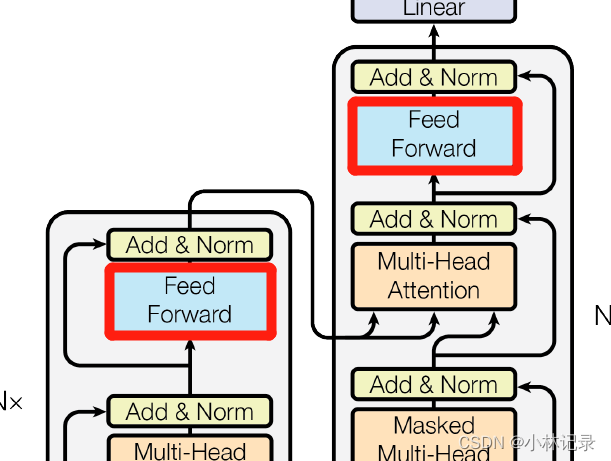
(2)作用
个人理解这部分的MLP是起到了信息处理的作用,即将信息转换成另一种信息的部分,在RNN中对应的就是MLP部分。RNN的MLP就是循环神经网络的循环部分,其输入是 t 时刻的信息和 t-1 时刻的输出的融合信息,与RNN不同的是,由于Transformer的每个单词的特征信息通过Attention已经融合了整个句子的信息,因此这部分不需要输入上一时刻的信息,而是直接对一个句子中每个单词生成的特征信息分别进行处理。
(3)组成与原理
直接上公式,从公式可以看出,他的结构很朴素简单,其实就是:线性层 → ReLU → 线性层。

解码器部分
解码器的Output Embedding 、Positional Encoding 、Add & Norm 、Feed Forward 都与编码器的相应部分相同,可参考上述介绍。
Masked Multi-Head Attention
(1)位置
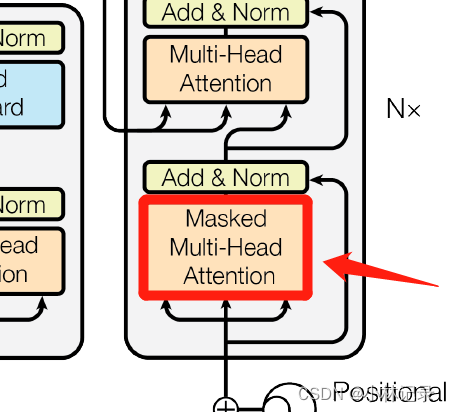
(2)作用
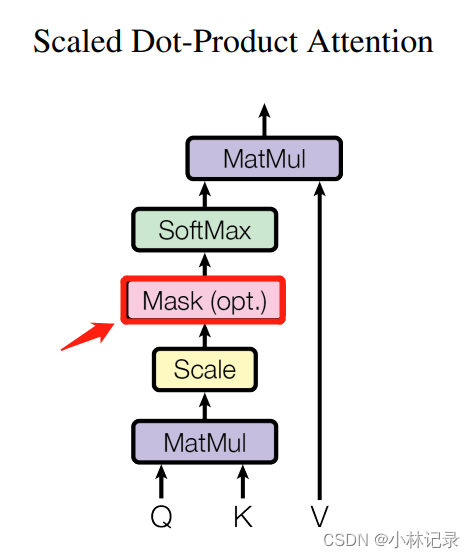
Mask 其实就是由于时序信息输入的时候,我们不可能提前知道后面的信息,只能获取前面的信息和当前的信息,所以这里就加入了一个Mask来把后面的信息盖住。
(3)原理
这部分没啥结构,其实就是将当前单词后的Q*K^T用一个很大的负数代替,如-1e10。这样在通过SoftMax后,它就会被处理成0,这样后面的时序信息就消失了。















 1447
1447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









