







1. 爬取+展示的实时项目
1.1 核心技术
- myqls + maxwell + redis+django 实现读写分离,实时项目,主从复制,读写分离,顺写日志。
maxwell将自己伪装成为slave,就可以从Mysql的集群中获取顺写日志Binlog

- maxwell取得的数据格式json

1.2 流程

1.3优化查询
- 下面的查询,笛卡尔积,性能差

- 下面,先查到张三,在进行计算,没有笛卡尔积,性能好

2. dbt airflow jenkins k8s ek2 部署
3. 别人的简历
camel:
- 使用 ec2 jenkins eks airflow dbt在aws平台设计和部署了datapipeline,优化了旧pipeline的并行效率,将data processing的效率提高了 2倍。
- 整合了airflow 和dbt,让airflow支持了dbt的原生语法,极大的提高了开发的效率。
4.Deployed ETL infrastructure using Azure DevOps and Terraform, and created and maintained data pipelines in Azure Data Factory and Azure Synapse.
{%- macro regex_match(model, column_name, regex_pattern) -%}
{{ return(adapter.dispatch('test_regex_match', 'dbt_utils')(model, column_name, regex_pattern)) }}
{%- endmacro %}
{%- macro default__test_regex_match(model, column_name, regex_pattern) -%}
select *
from {{ model }}
where {{ column_name }} !~* {{ regex_pattern }}
{%- endmacro %}
{#
-- Snowflake supports regex using `RLIKE`:
-- https://docs.snowflake.com/en/sql-reference/functions/rlike.html
#}
{%- macro snowflake__test_regex_match(model, column_name, regex_pattern) -%}
select *
from {{ model }}
where {{ column_name }} not rlike {{ regex_pattern }}
{%- endmacro %}
{#
-- PostgreSQL supports regex using `!~`:
-- https://www.postgresql.org/docs/current/functions-matching.html
#}
{%- macro postgres__test_regex_match(model, column_name, regex_pattern) -%}
select *
from {{ model }}
where {{ column_name }} !~ {{ regex_pattern }}
{%- endmacro %}
{#
-- Redshift does not support regex directly, but you can use `REGEXP`:
-- https://docs.aws.amazon.com/redshift/latest/dg/pattern-matching-conditions.html
#}
{%- macro redshift__test_regex_match(model, column_name, regex_pattern) -%}
select *
from {{ model }}
where {{ column_name }} !~ {{ regex_pattern }}
{%- endmacro %}
{#
-- BigQuery supports regex using `NOT REGEXP_CONTAINS`:
-- https://cloud.google.com/bigquery/docs/reference/standard-sql/functions-and-operators#regexp_contains
#}
{%- macro bigquery__test_regex_match(model, column_name, regex_pattern) -%}
select *
from {{ model }}
where not regexp_contains({{ column_name }}, {{ regex_pattern }})
{%- endmacro %}
{#
-- For other databases that do not support regex in a similar manner,
-- you may choose to implement a fallback mechanism or log an error.
#}



Developed and optimized data streaming pipelines using Apache Flink and Kafka for real-time data 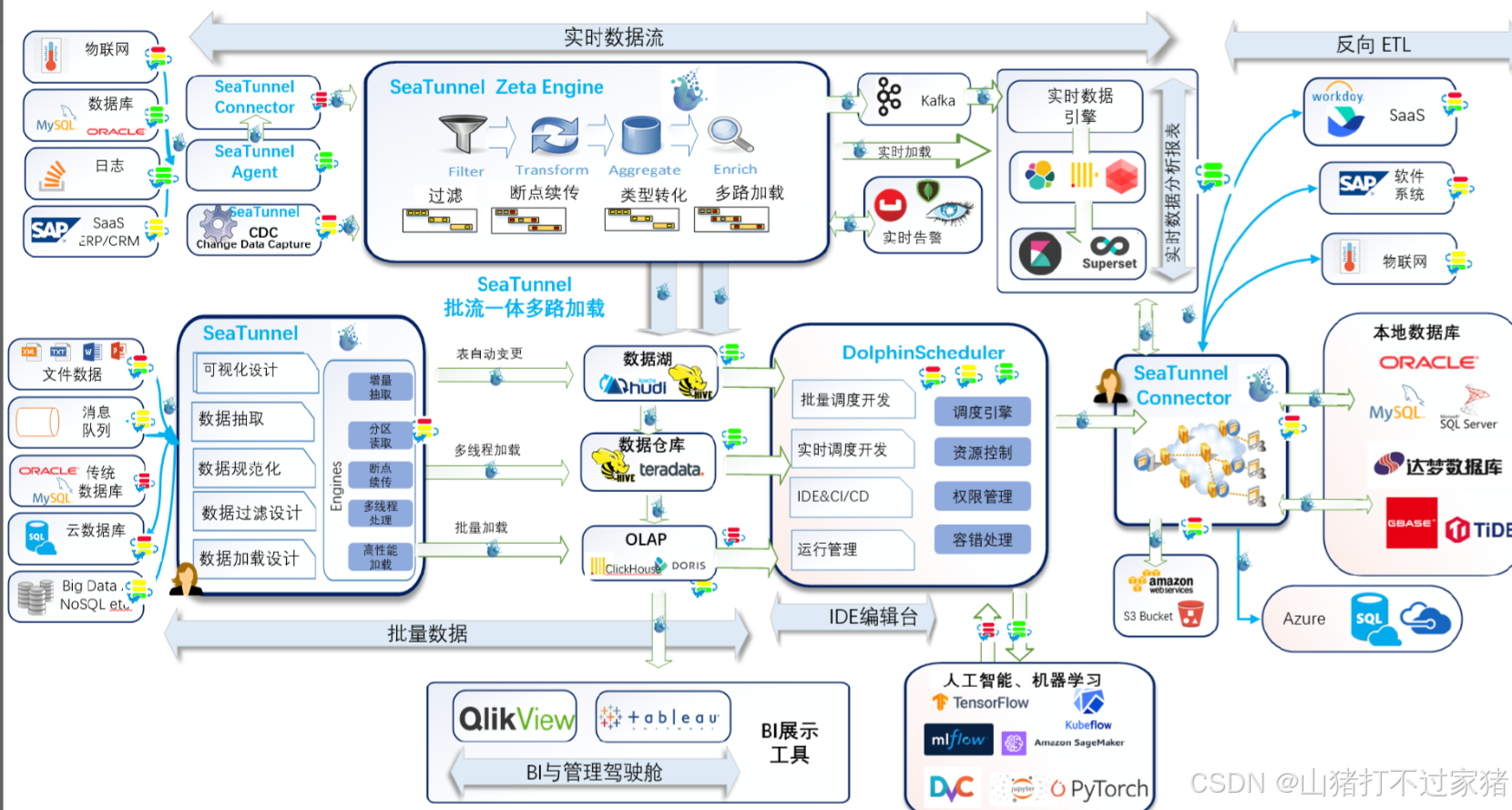

3. 电商项目数据流转
3.1 etl
3.2 反向etl
电商促销洞察回流项目(etl, reverse etl)
- 场景
反向ETL 数据流的场景
个性化推荐
数据仓库中的推荐模型将用户可能喜欢的商品列表推送到电商平台系统,通过反向ETL工具更新电商平台数据库或缓存。
当用户登录平台时,即时提供个性化推荐,提升转化率。
客户分级和激活
在数据仓库中分析并得出客户的活跃度等级和忠诚度评分,将评分推送到CRM系统。
客服团队接收到用户评分后,优先跟进高价值客户,通过邮件或电话沟通来提高客户留存。
营销活动推送
数据仓库分析出某类用户可能对新产品感兴趣,并将用户列表和活动链接推送至营销自动化平台。
营销系统根据推送的数据自动发送邮件或短信,进行定向推广,提升活动参与度。
库存优化和订单促销
将产品的销售趋势和库存情况传回电商平台,平台在库存不足时自动生成促销优惠,并推荐给适合的客户群体。
在订单系统中,推荐合适的优惠券或搭配商品,提升订单金额。
- 双十一特卖的反向etl
- 用户分群表users_segments,data anylists团队分析到的用户画像表。存放在gloden 或者curated层
user_id:用户唯一标识
segment_name:分群名称(如“高价值用户”、“潜在流失用户”)
segment_score:分群得分,衡量用户价值或活跃度
created_at:分群生成时间
last_updated_at:上次分群更新的时间
- 产品推荐表product_recommendations,存储针对每个用户的个性化推荐产品,确保活动推送信息具有个性化。也是data anylists团队,生成的gloden表
user_id:用户唯一标识
recommended_product_id:推荐商品ID
recommendation_score:推荐分数(根据推荐模型计算的优先级)
created_at:推荐生成时间
source:推荐来源(如“历史购买推荐”或“浏览记录推荐”)
- 营销活动表(marketing_campaigns)
campaign_id:活动唯一标识
campaign_name:活动名称(如“双十一特卖”)
start_date:活动开始日期
end_date:活动结束日期
target_segment:目标用户分群(如“高价值用户”)
discount_details:优惠信息(如“满100减10”)
channel:推送渠道(如“邮件”、“短信”)
4.活动用户匹配表(campaign_user_matches)
user_id:用户ID
campaign_id:活动ID
matched_at:匹配时间
5.发送日志表(campaign_delivery_log)
delivery_id:发送日志ID
user_id:用户ID
campaign_id:活动ID
delivery_channel:发送渠道(如短信、邮件)
status:发送状态(如成功、失败)
sent_at:发送时间
舆情与客户反馈分析系统
- 数据来源:
-
社媒监控系统,收集和监控,社交媒体上的监控品牌和品类的高点赞,高评论,高分享的话题,示例系统:Brandwatch、Hootsuite Insights、Sprout Social。
-
客户支持系统,功能:记录和管理来自不同渠道(网站、应用、邮件、电话)的客户服务请求、投诉和评价。
-
app和网站行为数据,用户行为数据,用户行为日志
-
用户行为和偏好,crm以及购买记录
-
物流管理系统,物流时效和配送反馈
3.2.1 反向etl的流程
在这个电商场景中,假设我们有一个反向 ETL 的三层架构,包括数据提取、处理/转化、数据推送到前线系统。以下将以实际业务为例,描述反向 ETL 的具体流程、涉及的表、系统及各层级的数据流。
系统架构背景
- 数据仓库:使用 AWS Redshift 或 Snowflake 作为中心数据仓库。
- CRM 系统:使用 Salesforce CRM 作为营销自动化平台。
- BI 系统:使用 Tableau 进行数据可视化和报告。
- 电商平台:使用 Magento 和 Shopify,作为订单和用户数据的来源。
- 支付和物流:整合 Stripe(支付)和 ShipStation(物流)等第三方系统。
三层架构反向 ETL 流程
1. 数据提取层(Extraction Layer)
- 目标:从业务系统中提取核心用户和订单数据,包括用户标签、消费记录、产品数据等。
- 数据来源系统:
- Magento 和 Shopify(电商平台):获取
customer_info、order_history表数据,包括用户基本信息、订单明细。 - Stripe(支付系统):获取
payment_transactions表数据,包含每笔支付的金额、支付方式、支付状态等。 - ShipStation(物流系统):获取
shipping_info表,包含物流状态、物流时效、物流费用等信息。
- Magento 和 Shopify(电商平台):获取
- 常用数据表:
customer_info:记录用户的基本信息,包含字段user_id,name,email,location。order_history:记录用户的订单明细,包含order_id,user_id,product_id,quantity,order_date,status。payment_transactions:包含支付相关信息,包含transaction_id,order_id,amount,payment_method,status。shipping_info:记录物流状态,包含shipment_id,order_id,carrier,shipping_cost,status。
2. 数据转换层(Transformation Layer)
- 目标:通过聚合、清洗和筛选,将原始数据转化为适合营销和推荐的目标数据格式。
- 聚合与转换:
- 用户行为标签表
user_behavior_tags:基于customer_info和order_history表,提取并生成用户购买频次、产品偏好、平均订单金额等标签。 - 用户价值分数表
user_lifetime_value:基于order_history和payment_transactions表,计算用户生命周期价值(LTV)、高价值客户分层(如“高价值”“活跃用户”“沉睡用户”)。 - 物流体验评分表
shipping_experience_score:基于shipping_info表,计算用户在各个物流渠道的平均时效、物流满意度评分。
- 用户行为标签表
- 生成的中间表:
user_behavior_tags:包括用户偏好标签,包含user_id,favorite_category,purchase_frequency,avg_order_value。user_lifetime_value:包含用户价值分数,包含user_id,ltv_score,tier。shipping_experience_score:包含物流体验评分,包含user_id,avg_delivery_time,satisfaction_score。
3. 数据加载层(Loading Layer)
- 目标:将转换后的数据推送到前线系统,用于用户个性化推荐和营销活动。
- 推送流程:
- CRM 系统(Salesforce CRM):
- 推送 用户标签和行为数据
user_behavior_tags表,结合用户价值分数,为 CRM 创建精准客户画像,用于营销细分(如针对高价值客户的活动推送)。 - 表示例:
crm_user_profiles,包含user_id,crm_tag,marketing_score,last_interaction。
- 推送 用户标签和行为数据
- 推荐引擎系统:
- 推送 推荐标签数据
user_behavior_tags表数据,供实时推荐使用。 - 表示例:
recommendation_data,包含user_id,recommended_category,recommended_product.
- 推送 推荐标签数据
- 物流分析系统:
- 推送 物流体验评分数据
shipping_experience_score表,支持客服团队识别物流问题,并优化物流策略。 - 表示例:
logistics_feedback,包含user_id,shipping_score,frequent_issues。
- 推送 物流体验评分数据
- CRM 系统(Salesforce CRM):
数据同步和分批处理
- 同步工具:在本地数据库使用 Python 或 Airflow 进行定期分批同步,避免大批量同步造成系统负载。
- 日志与监控:设置
etl_log表记录推送进程,字段包括user_id,sync_status,sync_timestamp,并通过 Prometheus 等监控推送任务健康状态。
示例数据量和分批处理
- 数据量:
- 日均订单数据量约为数十万条,用户标签数十万至上百万。
- 物流数据量较小,每天几万条左右。
- 分批方式:
- 用户行为和价值标签:每 6 小时同步一次。
- 推荐数据和物流评分:每日同步,以减少负载。
这种反向 ETL 的三层架构流程确保用户标签和行为数据能够高效进入 CRM 系统和推荐引擎,帮助电商平台更好地进行客户关系管理和个性化推荐。
4. 面试问题
Azure Data Engineer Mock Interview -First Round
1.tell me about yourself
2. your current projects
3. tell me more detials about your projects which technology has been used?
4. where you migerated you data to azure? cloud or on prem? pulling the data from ?
- you can not migrated sql database by adf, because adf can only transform data not the schema, instead you should use data migration service
- which tool you use to migrate on prem sql data base to azure sql
- how many copy activities you have used in your project
- if you have 100 copy activities how you solve your probelm?
- Most frequecy type of scheduler you use in your project
- if i have 10 pipeline run hourly, how many tumbling trigger should i create
- how do you identify the fail of pipeline and if you wanna restart the pipeline ,what should you do ?
- how you take your pipeline to the development environment ?
12.how to migrate data from onprem 1 to onprem 2 using adf? - design a pipeline running last working day of every month
- why tumbling window
- hanlding multy line in one line in csv in spark
- dealing with complex json in spark
- when files are arrived trigger the pipeline


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









