






时序数据的概念和特点
时序数据是指时间序列数据,是按时间顺序记录的数据列。在同一数据列中的各个数据必须是同口径的,要求具有可比性。时序数据可以是时期数,也可以时点数。对于数据库而言,时序数据一般是一系列带有时间戳和数据值的数据点,且各列数据值类型相同、数值随时间戳递增(减)或在有限区间内波动。
时序数据常用压缩编码方式
从时序数据的特点来看,通用的压缩算法和按行压缩并不能很好的压缩时序数据,因此时序数据库大多都针对不同类型的数据按列采用不同压缩编码方式来减少数据存储的空间占用,提高存储空间利用率。
Delta
差分编码又称增量编码,编码时,第一个数据不变,其他数据转换为与上一个数据的delta。该算法应用广泛,如需要查看文件的历史更改记录(版本控制、Git等)。在时序数据库中,很少单独使用,一般搭配Simple8b或者Zig-Zag一起使用,压缩效果更好,下面举例说明delta编码:
delta 时间戳压缩
时间戳一般采用 int64 类型进行存储,需要占用 8byte(64bit) 存储空间。最直接的优化就是存储时间戳的差值,这里需要起始时间戳和 delta 的最大范围阈值。有两种常用的实现思路:
- 存储相邻两个时间戳差值 Delta(n) = T(n) - T(n-1)
| Unix时间戳 | Delta |
|---|---|
| 1571889600000 | 0 |
| 1571889600010 | 10 |
| 1571889600025 | 15 |
| 1571889600030 | 5 |
| 1571889600040 | 10 |
- 存储与起始时间戳的差值 Delta(n) = T(n) - T(0)
| Unix时间戳 | Delta |
|---|---|
| 1571889600000 | 0 |
| 1571889600010 | 10 |
| 1571889600025 | 25 |
| 1571889600030 | 30 |
| 1571889600040 | 40 |
假设起始时间戳为 1571889600000,delta 的最大范围阈值为 3600s,每个 delta 的数值需要 13bit 可以存储。因此以上时间戳数据共占用空间为 64 + 13 * 4 = 116bit。
思路 1 的优势是不需要对块内数据依次遍历,但是相比思路 2 可能需要更为频繁地更换起始时间,根据实际需求选择合适的压缩方案。
Delta of Delta
又名二阶差分编码,是在Delta编码的基础上再一次使用Delta编码,比较适合编码单调递增或者递减的序列数据。例如 2,4,4,6,8 , Delta编码后为2,2,0,2,2 ,再Delta编码后为2,0,-2,0,0。通常也会搭配Simple-8B或者Zig-Zag一起使用。
Facebook Gorilla 有详细阐述 delta-of-delta 编码的计算方式,针对不同时间跨度的数据,Facebook Gorilla 给出了一种较为通用的处理方案。
| data | 标识位 | 占用总bits |
|---|---|---|
| 0 | 0 | 1 |
| [-63, 64] | 10 | 2+7=9 |
| [-255, 256] | 110 | 3+9=12 |
| [-2047, 2048] | 1110 | 4+12=16 |
| > 2048 | 1111 | 4+32=36 |
依然通过一组时间戳数据来直观感受下 delta-of-delta 编码的压缩效果:
| Unix时间戳 | delta | delta-of-delta | 压缩后总bits |
|---|---|---|---|
| 1571889600000 | 0 | 0 | |
| 1571889600010 | 10 | 10 | 9 |
| 1571889600010 | 0 | -10 | 9 |
| 1571889600011 | 1 | 1 | 9 |
| 1571889600012 | 1 | 0 | 1 |
| 1571889600013 | 1 | 0 | 1 |
| 1571889600015 | 2 | 1 | 9 |
| 1571889600017 | 2 | 0 | 1 |
依然假设起始时间戳为 1571889600000,delta 的最大范围阈值为 3600s,占用存储空间对比如下:
delta 算法: 64 + 13 * 7 = 155bit 。
delta-of-delta 算法: 64 + 9 * 4 + 1 * 3 = 103bit 。
可以看出 delta-of-delta 算法相比 delta 算法进一步获得了更高的压缩率。在实际应用场景中,海量时序数据的时间戳都是密集且连续的,绝大部分都满足 delta-of-delta=0 的条件,这样可以大幅度降低时间戳的存储空间。
Zig-Zag
在一些情况下,我们使用到的整数,往往是比较小的。比如,我们会记录一个用户的id、一本书的id、一个回复的数量等等。在绝大多数系统里面,他们都是一个小整数,就像1234、1024、100等。
而我们在系统之间进行通讯的时候,往往又需要以整型(int)或长整型(int64)为基本的传输类型,为了传输一个整型(int)1,我们需要传输00000000_00000000_00000000_00000001 32个bits,除了一位是有价值的1,其他全是基本无价值的0。
对于正整数来讲,如果在传输的时候,我们把多余的0去掉(或者是尽可能去掉无意义的0),传输有意义的1开始的数据,那我们就可以做到数据的压缩了,比如:00000000_00000000_00000000_00000001这个数字,我们如果能只发送一位1或者一个字节00000001,就将压缩很多额外的数据。
zigzag给出了一个很巧的方法:补码的第一位是符号位,他阻碍了我们对于前导0的压缩,那么,我们就把这个符号位放到补码的最后,其他位整体前移一位:
(-1)10
= (11111111_11111111_11111111_11111111)补
= (11111111_11111111_11111111_11111111)符号后移
但是即使这样,也是很难压缩的,因为数字绝对值越小,他所含的前导1越多。于是,这个算法就把负数的所有数据位按位求反,符号位保持不变,得到了这样的整数:
(-1)10
= (11111111_11111111_11111111_11111111)补
= (11111111_11111111_11111111_11111111)符号后移
= (00000000_00000000_00000000_00000001)zigzag
而对于非负整数,同样的将符号位移动到最后,其他位往前挪一位,数据保持不变。
(1)10
= (00000000_00000000_00000000_00000001)补
= (00000000_00000000_00000000_00000010)符号后移
= (00000000_00000000_00000000_00000010)zigzag
正数、0、负数都有同样的表示方法了,我们得到了有前导0的另外一个整数。不过他还是一个4字节的整数,我们接下来就要考虑怎么样将他们表示成尽可能少的字节数,并且还能还原。
比如:我们将1转换成(00000000_00000000_00000000_00000010)zigzag这个以后,我们最好只需要发送2bits(10),或者发送8bits(00000010),把前面的0全部省掉。因为数据传输是以字节为单位,所以,我们最好保持8bits这样的单位。zigzag引入了一个方法,就是用字节自己表示自己。
举个例来讲:
(-1000)10
= (11111111_11111111_11111100_00011000)补
= (00000000_00000000_00000111_11001111)zigzag
我们先按照七位一组的方式将上面的数字划开:
(0000-0000000-0000000-0001111-1001111)zigzag
- 将它跟(~0x7f)做与操作的结果,高位还有信息,所以,我们把低7位取出来,并在倒数第八位上补一个1(0x80):11001111
- 将这个数右移七位:(0000-0000000-0000000-0000000-0001111)zigzag
- 再取出最后的七位,跟(~0x7f)做与操作,发现高位已经没有信息了(全是0),那么我们就将最后8位完整的取出来:00001111,并且跳出循环,终止算法;
- 最终,我们就得到了两个字节的数据[11001111, 00001111]
解压过程就是:对于每一个字节,先看最高一位是否有1(0x80)。如果有,就说明不是最后一个数据字节包,那取这个字节的最后七位进行拼装。否则,说明就是已经到了最后一个字节了,那直接拼装后,跳出循环,算法结束。最终得到4字节的整数。
Simple-8B
Simple-8B编码方式是2010年墨尔本大学一博士在论文中提出的,在 simple 8b 中, 一组整数会被存在一系列固定大小的数据块中。 每个数据块里, 每个整数都用固定字长来表示, 这个固定字长由数据块中最大的整数来表示。而每个数据块的第一位用来标记这个数据块字长。
使用这个技术可以让我们只需要在每个数据块中只记录一次字长, 而不是去记录每个整数的字长。 而且因为每个数据块的字长是一样的, 我们也可能推算出来数据块里中存储了多少个整数。感兴趣的读者可以参考: Index compression using 64‐bit words
Bit-Packing
这种算法是把文本用需要的最少的位来进行压缩编码。
比 如八个十六进制数:1,2,3,4,5,6,7,8。转换为二进制为:00000001,00000010,00000011,00000100, 00000101,00000110,00000111,00001000。每个数只用到了低4位,而高4位没有用到(全为0),因此对低4位进行压缩编 码后得到:0001,0010,0011,0100,0101,0110,0111,1000。然后补充为字节得到:00010010, 00110100,01010110,01111000。所以原来的八个十六进制数缩短了一半,得到4个十六进制数:12,34,56,78。
对于bool类型,占用一个字节(8bit),但其实际有效的只有最后1bit的0 或1, 因此,在对bool类型进行压缩时,使用bit-packing压缩率很高:8个bool值,原先占用8byte(64bit),使用bit-packing压缩后只需要1byte(8bit),压缩率高达12.5%。
XOR
XOR编码方式是Gorilla内存数据库一篇论文中提出的,其主要针对时序数据(时间戳+测量值的键值对),对时间戳和测量值分别编码达到压缩效果。
针对时间戳采用前述delta of delta处理,针对测量值采用如下方法进行压缩:
- 第一个测量值不压缩(64bit)。
- 对于后续的测量值,如果当前值跟前一个值的XOR结果为0,即值相等,仅存储一位‘0’。
- 如果XOR结果不是0,计算XOR中前导零和尾随零的个数,存储位’1’后接a)或b):
a). 使用‘0’作为控制位,如果有意义位块落在前一个有意义位块中,即前导零和后导零的数量至少与前一个值相同,使用该信息作为块位置,只存储有意义的XOR值。
b). 使用‘1’作为控制位,将前导零数的长度存储到下5位,然后将有意义的xor值的长度存储到下6位。最后存储XOR值的有意义的位。
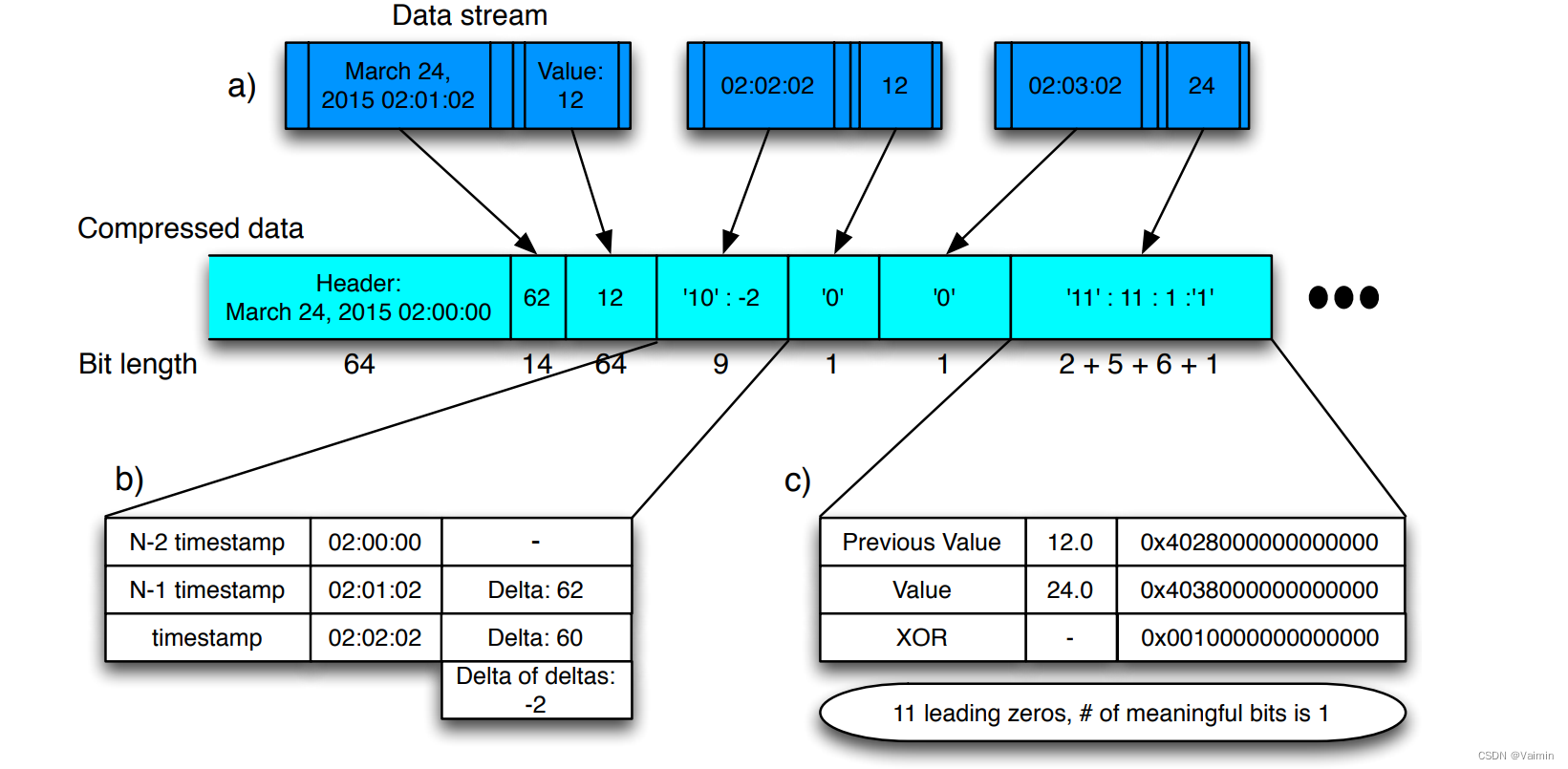
在上述图例中,块头后是第一条数据的时间戳跟块头基准时间戳的delta值,以及第一条数据的测量值(64bit),接下来是压缩后的键值对序列,第二条数据时间戳的d&d值为-2,位于‘10’标记的区间,则存储‘10’,后跟7位的‘-2’,第三条数据的时间戳d&d值为0,直接存储一位‘0’。
第一个测量值存储的是原值12(64bits),第二个测量值跟第一个测量值XOR结果为0,存储的是一位‘0’,第三个测量值跟第二个测量值XOR结果0x0010000000000000,转换为二进制有11个前导0(0x001==> 000000000001),因此使用‘11’(2bits)作为控制位,后跟5bit存储前导零个数,接下来6bit存储有意义的XOR结果值1(6bits),然后1bit存储有意义值的位数(只有一位有意义),合计64+1+2+5+6+1=79bits, 原值64*3=192bits,综合考虑原值:64x2x3=384bits,压缩后:103+64(head)=167bits, 压缩率0.435。
参考:

















 1911
1911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









