






 文章介绍了如何将Transformer应用于图像处理,首先通过PatchEmbedding将图像转化为一维向量,然后结合cls_token和位置嵌入进入TransformerBlock。SelfAttention模块处理注意力机制,MLPBlock进行残差连接和多层感知机操作。最后,通过ViTEncoderBlock和classification_head实现图像分类。
文章介绍了如何将Transformer应用于图像处理,首先通过PatchEmbedding将图像转化为一维向量,然后结合cls_token和位置嵌入进入TransformerBlock。SelfAttention模块处理注意力机制,MLPBlock进行残差连接和多层感知机操作。最后,通过ViTEncoderBlock和classification_head实现图像分类。

NLP中的Transformer处理输入是一维的词输入,所以如果要处理图片的话,就需要先把图片转变成一个一维向量。所以第一步应该是PatchEmbedding。
class PatchEmbedding(nn.Module):
def __init__(self, img_shape, patch_resolution, latent_space_dim):
super().__init__()
self.channel = img_shape[1]
patch_size = patch_resolution
self.num_of_patches = (img_shape[-1] * img_shape[-2]) / (patch_size[0] * patch_size[1])
self.projection = nn.Conv2d(self.channel, latent_space_dim, patch_size, patch_size)
def forward(self, input_img):
project = self.projection(input_img)
if project.dim() == 4:
patch_embedding = project.flatten(2)
else:
patch_embedding = project.flatten(1)
return patch_embedding这里的latent_space_dim=3*P*P(P是分割成的patch的分辨率,3是通道数)
Patch Embedding之后,得到了“latent vector”,给这个张量加上cls_token和postion embedding之后,就是Transfomer Block的输入了。
cls_token扩展了隐状态张量的维度,positon embedding是直接加在扩展后的隐状态张量上的。
class Embedding(nn.Module):
def __init__(self, latent_space_dim, num_of_patch, dropout):
super().__init__()
self.hidden_dim = latent_space_dim
self.patches = num_of_patch
self.cls_token = nn.Parameter(
nn.init.trunc_normal_(
torch.zeros(1, latent_space_dim, 1, dtype=torch.float32), mean=0.0
)
)
self.pos_embedding = nn.Parameter(
nn.init.trunc_normal_(
torch.zeros(1, int(latent_space_dim), int(num_of_patch + 1), dtype=torch.float32), mean=0.0
)
)
self.patch_embed = PatchEmbedding(paras.img_size, paras.patch_resolution, latent_space_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input_img, patch_embed):
batch_size = input_img.shape[0]
cls_token = self.cls_token.expand(batch_size, -1, -1)
embeddings = torch.cat((cls_token, patch_embed), dim=-1)
embeddings = embeddings + self.pos_embedding
embeddings = embeddings.permute(0, 2, 1)
return self.dropout(embeddings)可以看到,cls_token是用torch.cat()操作加上的,pos_embedding就是直接加(因为cls_token将隐状态张量的维度扩展了,所以这里创建的pos_embedding的维度是[1, latent_space_dim, num_of_patch + 1])。
然后就是普通的self attention模块,这个有很多博文讲的很清楚了,不多废话。
class SelfAttention(nn.Module):
def __init__(self, heads, hidden_size, dropout: 0.2):
super().__init__()
self.attention_heads = heads
self.hidden_size = hidden_size
self.head_size = int(hidden_size / heads)
self.query = nn.Linear(hidden_size, hidden_size, bias=True)
self.key = nn.Linear(hidden_size, hidden_size, bias=True)
self.value = nn.Linear(hidden_size, hidden_size, bias=True)
self.dropout = nn.Dropout(dropout)
def transpose_for_score(self, input_img):
new_shape = input_img.size()[:-1] + (self.attention_heads, self.head_size)
input_img = input_img.view(new_shape)
return input_img.permute(0, 2, 1, 3)
def forward(self, hidden_state):
key_matrix = self.transpose_for_score(self.key(hidden_state))
query_matrix = self.transpose_for_score(self.query(hidden_state))
value_matrix = self.transpose_for_score(self.value(hidden_state))
attention_score_ori = torch.matmul(query_matrix, key_matrix.transpose(-1, -2))
attention_score = attention_score_ori / math.sqrt(self.head_size)
# 归一化 有很多归一化的手段,这里用Softmax
attention_prob = F.softmax(attention_score, dim=-1)
attention_prob = self.dropout(attention_prob)
context_layer = torch.matmul(attention_prob, value_matrix)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_shape = context_layer.size()[:-2] + (self.hidden_size,)
context_layer = context_layer.view(new_context_shape)
return context_layer, attention_prob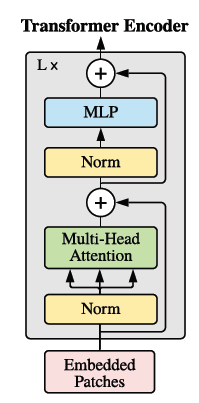
Transfomer Block的大部分都已经完成了,剩下的就是残差连接和MLP,也没什么特别需要说的。
class MLPBlock(nn.Module):
def __init__(self, hidden_size, inermidiate_size: 3072, dropout):
super().__init__()
self.fclayer1 = nn.Sequential(
nn.Linear(hidden_size, inermidiate_size),
nn.GELU()
)
self.dropout = nn.Dropout(dropout)
self.fclayer2 = nn.Sequential(
nn.Linear(inermidiate_size, hidden_size),
# nn.GELU()
)
def forward(self, hidden_state):
hidden_states = self.fclayer1(hidden_state)
hidden_states = self.dropout(hidden_states)
hidden_states = self.fclayer2(hidden_states)
mlp_output = self.dropout(hidden_states)
return mlp_outputclass ViTEncoderBlock(nn.Module):
def __init__(self, num_of_heads, hidden_size, intermidiate_size, dropout):
super().__init__()
self.dropout = nn.Dropout(dropout)
self.attetion_module = SelfAttention(num_of_heads, hidden_size, dropout)
self.mlpblock = MLPBlock(hidden_size, intermidiate_size, dropout)
self.layernorm_before = nn.LayerNorm(hidden_size)
self.layernorm_after = nn.LayerNorm(hidden_size)
def forward(self, hidden_state):
attention_output, attention_score = self.attetion_module(self.layernorm_before(hidden_state))
residual_add = self.dropout(attention_output)
mlp_input = self.layernorm_after(hidden_state + residual_add)
mlp_ouput = self.mlpblock(mlp_input)
ViTblock_output = mlp_ouput + mlp_input
return ViTblock_output
这样整个Transfomer Block就ok了。
最后就是把这些组合起来就成。
class ViT(nn.Module):
def __init__(self, num_of_class: int, num_of_layers, img_size, hidden_dim):
super().__init__()
self.num_classes = num_of_class
self.dropout = nn.Dropout(0.2)
self.patch_embedding =PatchEmbedding(img_size, paras.patch_resolution, hidden_dim)
self.embeddings = Embedding(hidden_dim, paras.num_of_patch, paras.dropout_ratio)
self.encoder_block = ViTEncoderBlock(12, hidden_dim, paras.MLP_hidden_dim, paras.dropout_ratio)
self.classification_head = nn.Sequential(
nn.Linear(hidden_dim, num_of_class),
nn.Softmax(dim=-1)
)
self.layer = nn.ModuleList(self.encoder_block for _ in range(num_of_layers))
def embed_instantiation(self, input_img):
patch_embed = self.patch_embedding(input_img)
transfomer_input = self.embeddings(input_img, patch_embed)
return transfomer_input
def forward(self, img):
transfomer_input = self.embed_instantiation(img)
for m in self.layer:
transfomer_input = m(transfomer_input)
transfomer_input = transfomer_input[:, 0]
res = self.classification_head(transfomer_input)
return res最后分类的时候,只需要cls_token,所以就只把cls_token取出来,送给classification_head。















 45
45

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









