







作者邮箱:634494816@qq.com
chatgpt academic能干啥?具体用法看官网

使用chatgpt academic前置条件:
①需xx上网
②有key(chatgpt官网注册账户即可免费获得)(注册教程在这,注意:无需付费,注册账号即可获得key)
1.下载所需文件
解压后打开文件夹,注意解压路径不要出现中文。
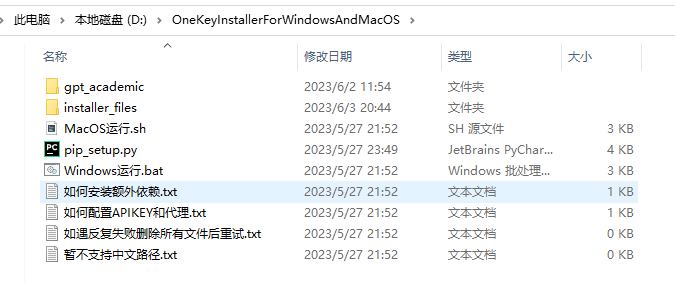
注意解压路径不要出现中文
2.填写数据
打开gpt_academic文件夹
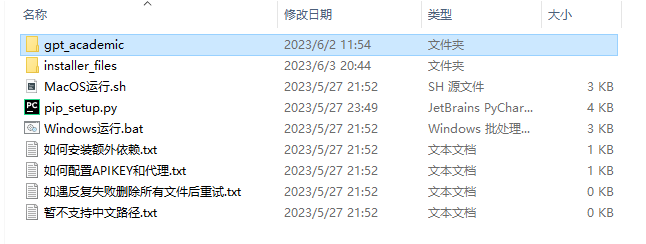
找到config.py文件夹
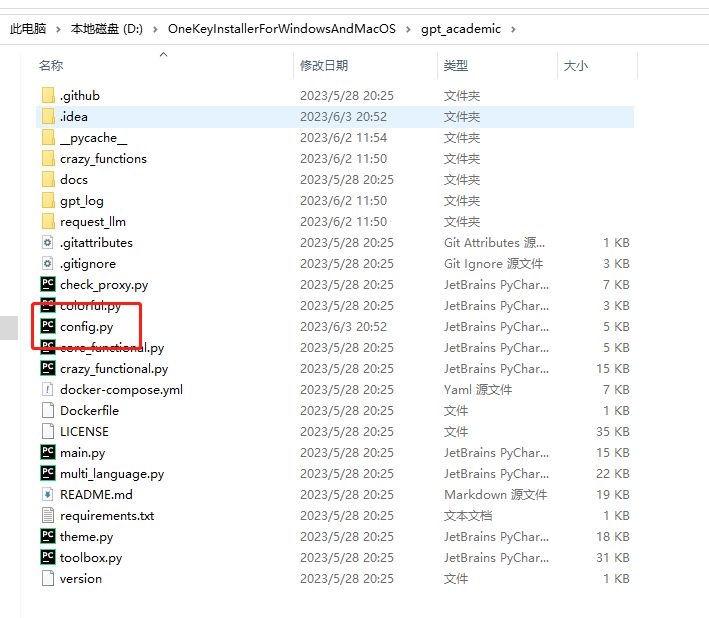
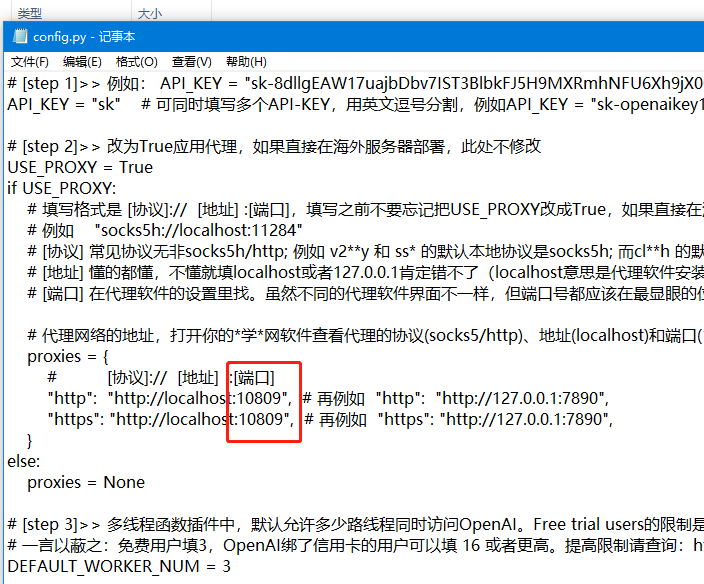
右键点击config.py,点击用记事本打开。然后找到红圈的sk,改为自己的key。

然后打开电脑的internet选项。(按电脑左下角开始键,输入internet即会出现internet选项)
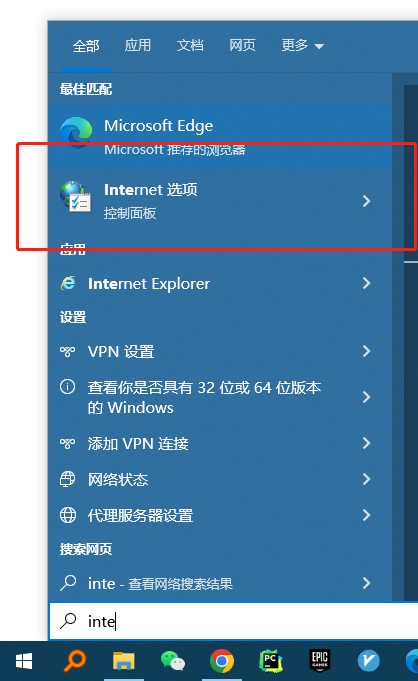
打开后点击“连接”
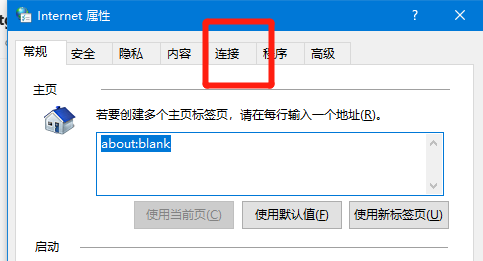
点击局域网设置
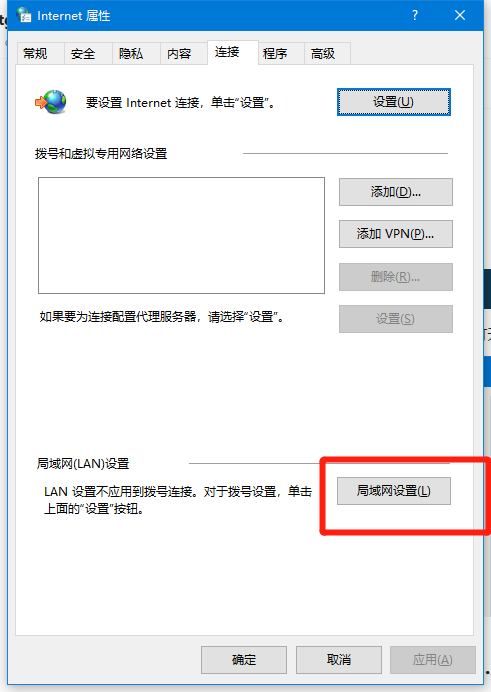
勾选“为lan使用代理服务器”,找到端口号并记住(一般为四位或者五位数字)
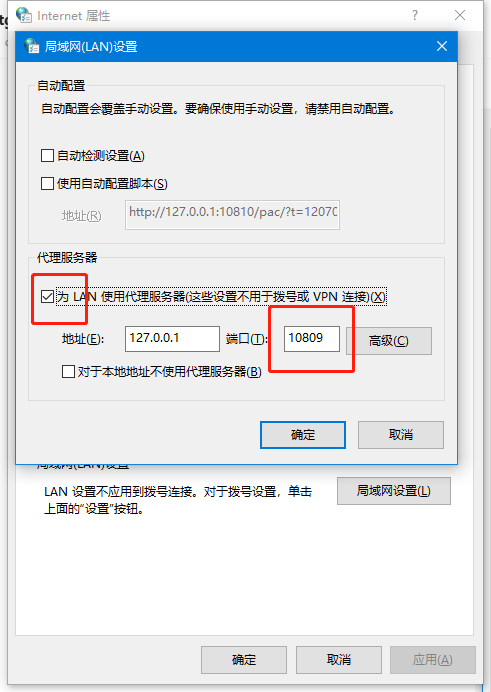
回到config.py文件。将红圈处的10809替换为自己刚刚记住的端口号。然后保存,关闭config.py。
3.安装使用
回到OneKeyInstallerForWindowsAndMacOS文件夹,找到Windows运行.bat,双击运行。
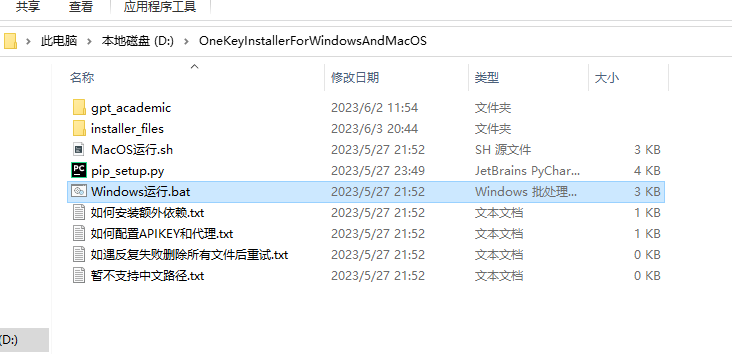
出现这个界面,输入2,然后按回车。等待安装即可。安装好后即会自己弹出chatgpt界面,即可使用。
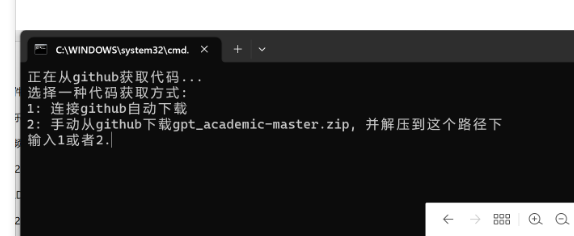
安装好后即会自己弹出chatgpt界面,即可使用。
以后每次使用都点击Windows运行.bat
4.具体使用
看官方网站即可

















 3556
3556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









