






【吴恩达机器学习笔记】第三章 Logistic回归
Logistic回归虽然叫做回归,但实际上是一种分类算法。
1、假设函数
假设:
h
θ
(
x
)
=
g
(
θ
T
x
)
h_{\theta }(x)=g(\theta ^{T}x)
hθ(x)=g(θTx)
Logistic函数(也称sigmoid函数)如下所示:
g
(
z
)
=
1
1
+
e
−
z
g\left ( z \right )= \frac{1}{1+e^{-z}}
g(z)=1+e−z1图像大致为:
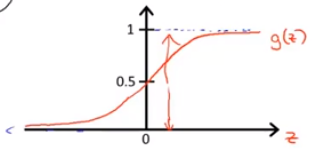
这样可以使
h
θ
(
x
)
h_{\theta }\left ( x \right )
hθ(x)的范围在0到1之间。
h θ ( x ) h_{\theta }\left ( x \right ) hθ(x)的含义用概率来解释为: h θ ( x ) = p ( y = 1 ∣ θ ; x ) h_{\theta }\left ( x \right )=p\left ( y=1|\theta ;x \right ) hθ(x)=p(y=1∣θ;x)
2、决策界限
如果我们要预测输出的值为0还是为1,我们可以假设:
如果
h
θ
(
x
)
≥
0.5
h_{\theta }\left ( x \right )\geq 0.5
hθ(x)≥0.5,那么
y
=
1
y=1
y=1;如果
h
θ
(
x
)
<
0.5
h_{\theta }\left ( x \right )< 0.5
hθ(x)<0.5,那么
y
=
0
y=0
y=0
根据Logistic函数图像可以发现, h θ ( x ) ≥ 0.5 h_{\theta }\left ( x \right )\geq 0.5 hθ(x)≥0.5 时, x ≥ 0 x\geq0 x≥0, h θ ( x ) < 0.5 h_{\theta }\left ( x \right )<0.5 hθ(x)<0.5 时, x < 0 x<0 x<0
举个例子让我们能更直观的理解,假设有一个数据集如图所示:
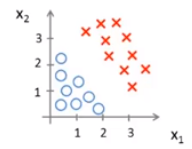
假设函数为
h
θ
(
x
)
=
g
(
θ
0
+
θ
1
x
1
+
θ
2
x
2
)
h_{\theta }\left ( x \right )=g\left ( \theta _{0}+\theta _{1}x_{1}+ \theta _{2}x_{2}\right )
hθ(x)=g(θ0+θ1x1+θ2x2),假设
θ
=
[
−
3
1
1
]
\theta =\begin{bmatrix} -3\\ 1\\ 1 \end{bmatrix}
θ=⎣⎡−311⎦⎤。
那么当
g
(
θ
0
+
θ
1
x
1
+
θ
2
x
2
)
≥
0
g\left ( \theta _{0}+\theta _{1}x_{1}+ \theta _{2}x_{2}\right )\geq0
g(θ0+θ1x1+θ2x2)≥0,即
−
3
+
x
1
+
x
2
≥
0
-3+x_{1}+x_{2}\geq0
−3+x1+x2≥0 时,可以预测
y
=
1
y=1
y=1。
x
1
+
x
2
≥
3
x_{1}+x_{2}\geq3
x1+x2≥3的意义是在图中划了一条线,将数据集进行了二分类,如下图所示:
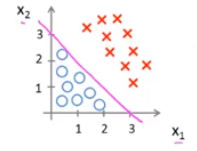
红线上面的区域为假设函数预测
y
=
1
y=1
y=1 的区域,下面为假设函数预测
y
=
0
y=0
y=0 的区域,这条红线则被成为决策边界,它对应了一系列
h
θ
(
x
)
=
0.5
h_{\theta }\left ( x \right )=0.5
hθ(x)=0.5 的点
决策边界不是数据集的属性而是假设本身及其参数的属性
如果
θ
\theta
θ 参数比较复杂,决策边界也会变得更复杂,而不一定是一条直线。
3、代价函数
因为 Logistic函数
g
(
z
)
=
1
1
+
e
−
z
g\left ( z \right )= \frac{1}{1+e^{-z}}
g(z)=1+e−z1 是非常非线性的,如果将线性回归的代价函数:
J
(
θ
)
=
1
m
∑
i
=
1
m
C
o
s
t
(
h
θ
(
x
(
i
)
)
,
y
(
i
)
)
J\left ( \theta \right )=\frac{1}{m}\sum_{i=1}^{m}Cost(h_{\theta }(x^{(i)}),y^{(i)})
J(θ)=m1i=1∑mCost(hθ(x(i)),y(i))
C
o
s
t
(
h
θ
(
x
(
i
)
)
,
y
(
i
)
)
=
1
2
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
Cost(h_{\theta }(x^{(i)}),y^{(i)})=\frac{1}{2}(h_{\theta }(x^{(i)})-y^{(i)})^{2}
Cost(hθ(x(i)),y(i))=21(hθ(x(i))−y(i))2来作为 Logistic回归的代价函数,画出的代价函数图像是非凸函数,如下图所示:
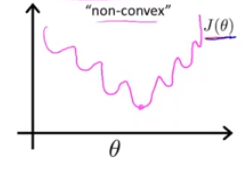
它有多个局部最优点,如果用梯度下降算法会很容易陷入局部最优解,为了使代价函数能够为凸函数,我们定义 Logistic回归的代价函数如下:
C
o
s
t
(
h
θ
(
x
)
,
y
)
=
{
−
l
o
g
(
h
θ
(
x
)
)
i
f
y
=
1
−
l
o
g
(
1
−
h
θ
(
x
)
)
i
f
y
=
0
Cost(h_{\theta }(x),y)=\left\{\begin{matrix} -log(h_{\theta }(x))\quad if \quad y=1\\ -log(1-h_{\theta }(x))\quad if \quad y=0 \end{matrix}\right.
Cost(hθ(x),y)={−log(hθ(x))ify=1−log(1−hθ(x))ify=0我们画出代价函数图像如下所示:
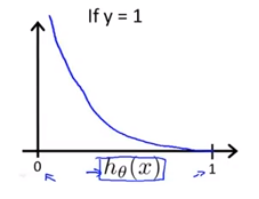
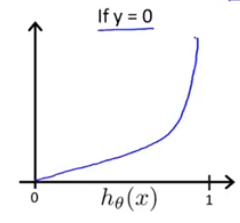
为了使代价函数不分段,我们做了简化后得到新的代价函数:
C
o
s
t
(
h
θ
(
x
)
,
y
)
=
−
y
l
o
g
(
h
θ
(
x
)
)
−
(
1
−
y
)
l
o
g
(
1
−
h
θ
(
x
)
)
Cost(h_{\theta }(x),y)=-ylog(h_{\theta }(x))-(1-y)log(1-h_{\theta }(x))
Cost(hθ(x),y)=−ylog(hθ(x))−(1−y)log(1−hθ(x))
4、梯度下降算法
我们已经得到 Logistic回归的代价函数如下所示: J ( θ ) = − 1 m [ ∑ i = 1 m y ( i ) l o g ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) l o g ( 1 − h θ ( x ( i ) ) ) ] J(\theta )=-\frac{1}{m}[\sum_{i=1}^{m}y^{(i)}log(h_{\theta }(x^{(i)}))+(1-y^{(i)})log(1-h_{\theta }(x^{(i)}))] J(θ)=−m1[i=1∑my(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]我们按照前面所学的梯度下降算法的模板:
repeat: θ j : = θ j − α ∂ ∂ θ j J ( θ ) \quad\theta _{j}:=\theta _{j}-\alpha \frac{\partial }{\partial \theta _{j}}J(\theta ) θj:=θj−α∂θj∂J(θ)
带入Logistic回归的代价函数后发现与线性回归的梯度下降算法几乎一样:
repeat: θ j : = θ j − α ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) \quad\theta _{j}:=\theta _{j}-\alpha \sum_{i=1}^{m}(h_{\theta }(x^{(i)})-y^{(i)})x_{j}^{(i)} θj:=θj−α∑i=1m(hθ(x(i))−y(i))xj(i)
不同之处在于:线性回归的 h θ ( x ) h_{\theta }(x) hθ(x) 是 θ T X \theta ^{T}X θTX,而Logistic回归的 h θ ( x ) h_{\theta }(x) hθ(x) 是 1 1 + e − θ T X \frac{1}{1+e^{-\theta ^{T}X}} 1+e−θTX1
同样,在线性回归中的特征缩放在Logistic回归中也同样适用。
5、高级优化算法
举个栗子:假设有
θ
=
[
θ
1
θ
2
]
\theta =\begin{bmatrix} \theta _{1}\\ \theta _{2} \end{bmatrix}
θ=[θ1θ2]
J
(
θ
)
=
(
θ
1
−
5
)
2
+
(
θ
2
−
5
)
2
J(\theta )=(\theta _{1}-5)^{2}+(\theta _{2}-5)^{2}
J(θ)=(θ1−5)2+(θ2−5)2
∂
∂
θ
1
J
(
θ
)
=
2
(
θ
1
−
5
)
\frac{\partial }{\partial \theta _{1}}J(\theta )=2(\theta _{1}-5)
∂θ1∂J(θ)=2(θ1−5)
∂
∂
θ
2
J
(
θ
)
=
2
(
θ
2
−
5
)
\frac{\partial }{\partial \theta _{2}}J(\theta )=2(\theta _{2}-5)
∂θ2∂J(θ)=2(θ2−5)
则用高级优化算法的MATLAB代码如下所示:
costFunction.m
function [jVal,gradient] = costFunction(theta)
jVal = (theta(1)-5)^2 + (theta(1)-5)^2;
gradient = zeros(2,1);
gradient(1) = 2*(theta(1)-5);
gradient(2) = 2*(theta(2)-5);
main.m
options = optimset('GradObj','on','MaxIter',100);
initialTheta = zeros(2,1);
[optTheta,functionVal,exitFlag]=fminunc(@costFunction,initialTheta,options);
6、多元分类
假设我们有训练集
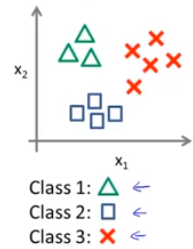
我们可以分别拟合出三个分类器如下所示:
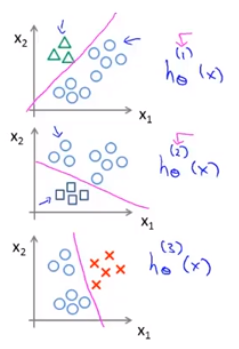
我们得到一个拟合分类器:
h
θ
(
i
)
(
x
)
=
P
(
y
=
i
∣
x
;
θ
)
h_{\theta }^{(i)}(x)=P(y=i|x;\theta )
hθ(i)(x)=P(y=i∣x;θ)
总结:
如果要进行多元分类,我们可以训练一个逻辑回归分类器
h
θ
(
i
)
(
x
)
h_{\theta }^{(i)}(x)
hθ(i)(x) 预测 i 类别
y
=
i
y=i
y=i的概率。
最后为了做出预测,我们给定一个新的输入值 x, 我们要做的就是,在每个分类器运行输入x,然后选择
h
h
h 最大的类别,也就是要选择分类器。















 282
282











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









