







致谢:霹雳吧啦Wz:https://space.bilibili.com/18161609
目录
致谢:霹雳吧啦Wz:https://space.bilibili.com/18161609
1 本次要点
1.1 pytorch框架语法
- nn.MaxPool2d()中参数ceil_mode=True:向上取整
- 如果要忽略pth权重文件中网络的部分参数(即网络结构中有些结构没有或不需要了,但训练得到的pth中有),则在加载pth时调用load_state_dict()时,参数 strict设为False
2 网络简介
2.1 历史意义
- GoogLeNet在2014年由Google团队提出,斩获当年ImageNet竞赛中Classification Task (分类任务) 第一名。(VGG是第2名)
2.2 网络亮点
- 引入了Inception 结构(融合不同 尺度的 特征信息)
- 使用1x1卷积核进行降维以及映射处理
- 添加两个辅助分类器帮助训练(推理时,辅助分类器会删除!)
- 增加两个辅助分类器的作用:
- 增加低层网络的分类能力
- 可阻止网络中间部分梯度消失
- 增加正则化(即网络总的损失函数有网络中层的影响,一定程度增加了正则化)
- 正则化作用:提高模型的泛化能力,避免过拟合。
- 正则化方法:在损失函数中加入正则化项(相等于加个“挂坠”,防止乱动)(如标签平滑,旨在阻止网络对某一类别过分自信)、dropout、早停、数据增强。
- 增加两个辅助分类器的作用:
- 推理阶段只使用1个全连接层(使用平均池化层代替,大大减少模型参数)
2.3 题外话
- GoogleNet参数(700万)仅VGG 的
。
- GoogleNet一共有4代,Inception v1,Inception v2,Inception v3,Inception v4,后续基本围绕Inception module结构改进。
- 当然,GoogleNet结构复杂,且有两个辅助分类器,搭建和训练麻烦,导致后续VGG被应用的更多。
2.3 网络结构
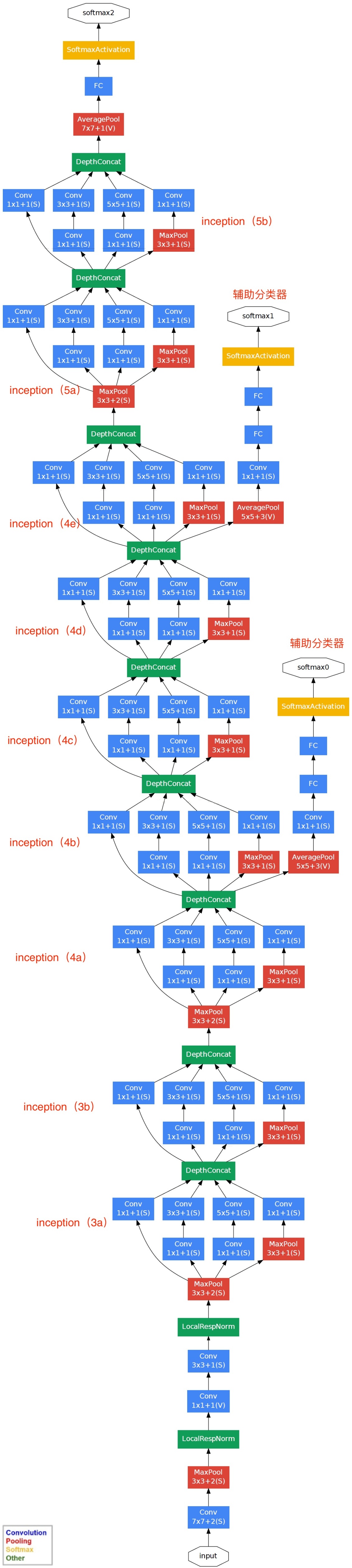

- 上图中depth值,指的是该结构连续有多个。
- reduce是降维意思,#3x3 reduce指的是3x3卷积层前的那个1x1卷积层,#5x5 reduce指的是5x5卷积层前的那个1x1卷积层。

3 代码结构
- train.py
- model.py
- predict.py
3.1 model.py
import torch.nn as nn
import torch
import torch.nn.functional as F
# aux_logits:是否适用辅助分类器
class GoogLeNet(nn.Module):
def __init__(self, num_classes=1000, aux_logits=True, init_weights=False):
super(GoogLeNet, self).__init__()
self.aux_logits = aux_logits
self.conv1 = BasicConv2d(3, 64, kersel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True) # ceil_mode=True:向上取整
# LocalRespNorm层原论文中在此有,但并没什么帮助,可以不用。
# nn.LocalResponseNorm()
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
#辅助分类器
if aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
#通过自适应平均池化,无论输入图像维度多少,都在此得到高为1宽为1的特征矩阵。
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(1024, num_classes)
if init_weights:
self._initialize_weights()
def forward(self, x):
# n x 3 x 224 x 224
x = self.conv1(x)
# n x 64 x 112 x 112
x = self.maxpool1(x)
# n x 64 x 56 x 56
x = self.conv2(x)
# n x 64 x 56 x 56
x = self.conv3(x)
# n x 192 x 56 x 56
x = self.maxpool2(x)
# n x 192 x 28 x 28
x = self.inception3a(x)
# n x 256 x 28 x 28
x = self.inception3b(x)
# n x 480 x 28 x 28
x = self.maxpool3(x)
# n x 480 x 14 x 14
x = self.inception4a(x)
# n x 512 x 14 x 14
# 在训练模式才使用辅助分类器 且 确认训练模式使用它
# 因为在测试阶段,辅助分类器并不需要使用(精度没有主分类器高)
# 注意:该变量由net.train()和net.eval()自动控制
if self.training and self.aux_logits:
aux1 = self.aux1(x)
x = self.inception4b(x)
# n x 512 x 14 x 14
x = self.inception4c(x)
# n x 512 x 14 x 14
x = self.inception4d(x)
# n x 528 x 14 x 14
if self.training and self.aux_logits:
aux2 = self.aux2(x)
x = self.inception4e(x)
# n x 832 x 14 x 14
x = self.maxpool4(x)
# n x 832 x 7 x 7
x = self.inception5a(x)
# n x 832 x 7 x 7
x = self.inception5b(x)
# n x 1024 x 7 x 7
x = self.avgpool(x)
# n x 1024 x 1 x 1
x = torch.flatten(x, 1)
# n x 1024
x = self.dropout(x)
x = self.fc(x)
# n x 1000(num_classes)
#如果使用辅助分类器,则返回3个分类器结果。
if self.training and self.aux_logits:
return x, aux2, aux1
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
#要确保每个分支的输出高宽相等,这样才能在通道方向拼接。
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj)
super(Inception, self).__init__()
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 因为kernel_size=3,所以使用padding=1,使得输出大小等于输入
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=1),
BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2) # 因为kernel_size=5,所以使用padding=2,使得输出大小等于输入
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),# 为了保证输出输出大小一致,需要设stride=1, padding=1
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1) #在channel维度合并,即outputs的第1个维度。(B,C,H,W)
#辅助分类器
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = BasicConv2d(in_channels, 128, kernel_size=1)
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x):
# aux1: N*512*14*14, aux2: N*528*14*14
x = self.averagePool(x)
# aux1: N*512*4*4, aux2: N*528*4*4
x = self.conv(x)
# N * 128 * 4 * 4
x = torch.flatten(x, 1) #展平第1维度(即Channel维度)
x = F.dropout(x, 0.5, training=self.training)
# N * 2047
x = F.relu(self.fc1(x), inplace=True)
x = F.dropout(x, 0.5, training=self.training)
# N * 1024
x = self.fc2(x)
# N * num_classes
return x
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x3.2 train.py
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import torchvision
import json
import matplotlib.pyplot as plt
import os
import torch.optim as optim
from model import GoogLeNet
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path
image_path = os.path.join(data_root, "data_set", "flower_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 32
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=nw)
print("using {} images for training, {} images fot validation.".format(train_num,
val_num))
# test_data_iter = iter(validate_loader)
# test_image, test_label = test_data_iter.next()
# net = torchvision.models.googlenet(num_classes=5)
# model_dict = net.state_dict()
# pretrain_model = torch.load("googlenet.pth")
# del_list = ["aux1.fc2.weight", "aux1.fc2.bias",
# "aux2.fc2.weight", "aux2.fc2.bias",
# "fc.weight", "fc.bias"]
# pretrain_dict = {k: v for k, v in pretrain_model.items() if k not in del_list}
# model_dict.update(pretrain_dict)
# net.load_state_dict(model_dict)
net = GoogLeNet(num_classes=5, aux_logits=True, init_weights=True)
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0003)
best_acc = 0.0
save_path = './googleNet.pth'
for epoch in range(30):
# train
net.train() #
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
images, labels = data
optimizer.zero_grad()
logits, aux_logits2, aux_logits1 = net(images.to(device))
loss0 = loss_function(logits, labels.to(device))
loss1 = loss_function(aux_logits1, labels.to(device))
loss2 = loss_function(aux_logits2, labels.to(device))
loss = loss0 + loss1 * 0.3 + loss2 * 0.3
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
# print train process
rate = (step + 1) / len(train_loader)
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.3f}".format(int(rate * 100), a, b, loss), end="")
print()
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
for val_data in validate_loader:
val_images, val_labels = val_data
outputs = net(val_images.to(device)) # eval model only have last output layer
predict_y = torch.max(outputs, dim=1)[1]
acc += (predict_y == val_labels.to(device)).sum().item()
val_accurate = acc / val_num
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, running_loss / step, val_accurate))
print('Finished Training')
if __name__ == '__main__':
main()3.3 predict.py
import torch
from model import GoogLeNet
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
import json
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# load image
img = Image.open("../tulip.jpg")
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
try:
json_file = open('./class_indices.json', 'r')
class_indict = json.load(json_file)
except Exception as e:
print(e)
exit(-1)
# create model
model = GoogLeNet(num_classes=5, aux_logits=False)
# load model weights
model_weight_path = "./googleNet.pth"
#加载模型
#辅助分类的器权重也保存在pth中,但预测时会屏蔽辅助分类器的结构,也就不需要加载这些权重。
#方法是model.load_state_dict()中参数strict设为False,即不精准匹配模型参数。
missing_keys, unexpected_keys = model.load_state_dict(torch.load(model_weight_path), strict=False)
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img))
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print(class_indict[str(predict_cla)])
plt.show()
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









