






本文记录自己在Win11电脑上部署fastGPT、连接本地大模型ChatGLM2-6b及其相关的工具的详细过程。最近离职在家,想跑通了一套流程后再去找工作,进程有点慢,呜呜。
首先,接上一篇在本地部署大模型chatGLM2-6B并采用各种api和网页demo进行调用,现在已过去好几天。
也是从chatGLM的社区了解到oneapi又间接了解到可以链接知识库得工具fastGPT,这必须要给他弄通啊。
直接先打开官方网址:
Docker Compose 快速部署 | FastGPT (fastai.site)
看一眼架构图:
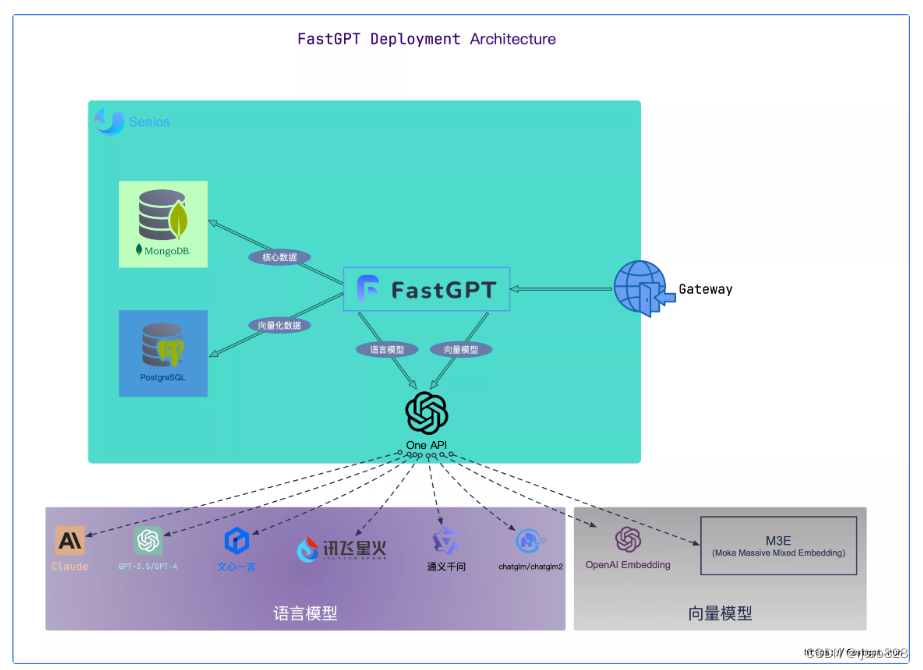
大概也能看懂,fastGPT后台采用MongoDB和PostgreSQL存储数据,提供前后端应用,在通过oneapi集成各种大模型(包括语言模型和向量模型),再外接知识库进行补充修正,真的很nice。
话不多说,开始部署:
环境:
1、安装WSL2(windows子系统)
如果电脑只用作跑模型,建议直接安装Ubuntu22.04桌面版,或者安装双系统,这样后续操作可能不会遇到那么多坑。
如果想在自己的个人电脑搞大模型,又不影响别的,只能说WSL2真的香。
安装wsl最重要的是微软官方这篇:旧版 WSL 的手动安装步骤 | Microsoft Learn
1.1 启用适用于 Linux 的 Windows 子系统
需要先启用“适用于 Linux 的 Windows 子系统”可选功能,官方命令:
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart1.2 检查运行 WSL 2 的要求
需要检查系统是否满足:

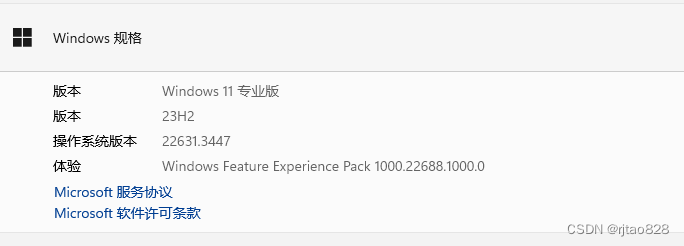
我们电脑系统我为Win11,因此可以继续。
1.3 启用虚拟机功能
官方命令:
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestartPS:可能需要在bios设置中,打开电脑的虚拟化(自行百度,开机按esc\del或者F2、F12这些进入)。
1.1和1.3可以通过启用和关闭windows功能进行设置:
也可打开启用或关闭windows功能:

 勾选以下两项:
勾选以下两项:

点击应用。
1.4下载 Linux 内核更新包
Linux 内核更新包会安装最新版本的 WSL 2 Linux 内核,以便在 Windows 操作系统映像中运行 WSL。
1.5将 WSL 2 设置为默认版本
wsl --set-default-version 21.6下载Linux发行版,并安装
推荐直接下载.appx文件再采用命令进行安装:
下载链接(网速嗖嗖快~):
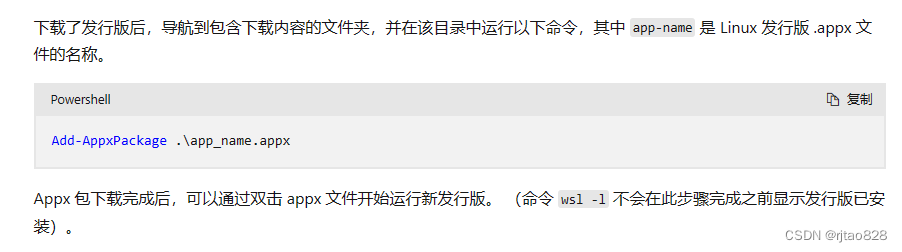
命令:
Add-AppxPackage .\app_name.appx切换到下载目录,并替换安装包名称,即可安装成功。
我这里顺带安装windows终端:
![]()
安装完成后的界面:

点击,就直接能够进入Ubuntu的终端了:
也可以通过终端那里的下三角符号进入:
2、安装docker
2.1下载docker desktop
wsl2安装成功了,docker也差不多完事了:
到网址:
Docker Desktop: The #1 Containerization Tool for Developers | Docker
下载windows安装包:

然后双击,下一步,下一步就按照好了。
2.2设置
我们可以打开:

点击设置:
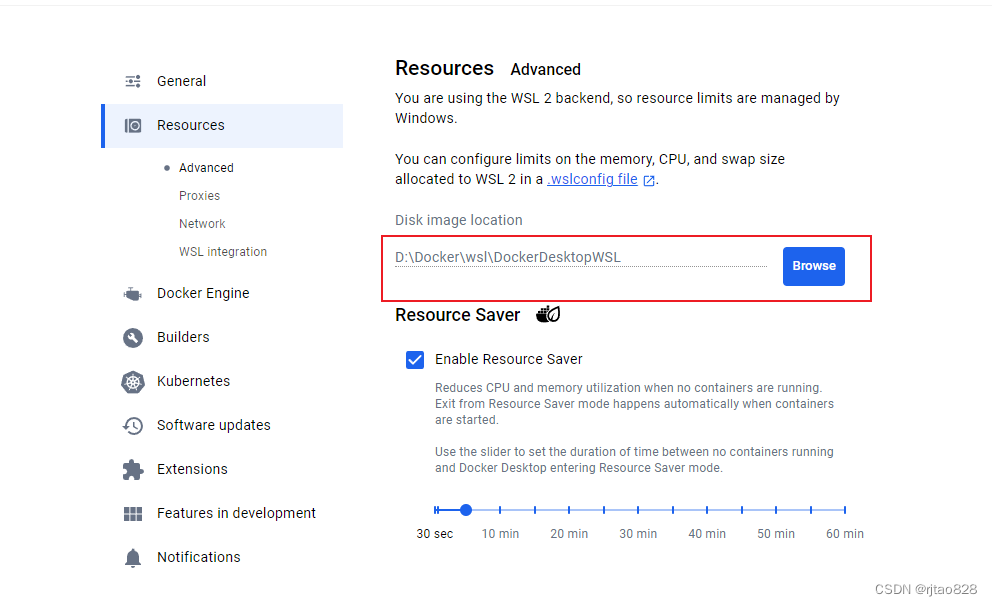
设置镜像下载位置:
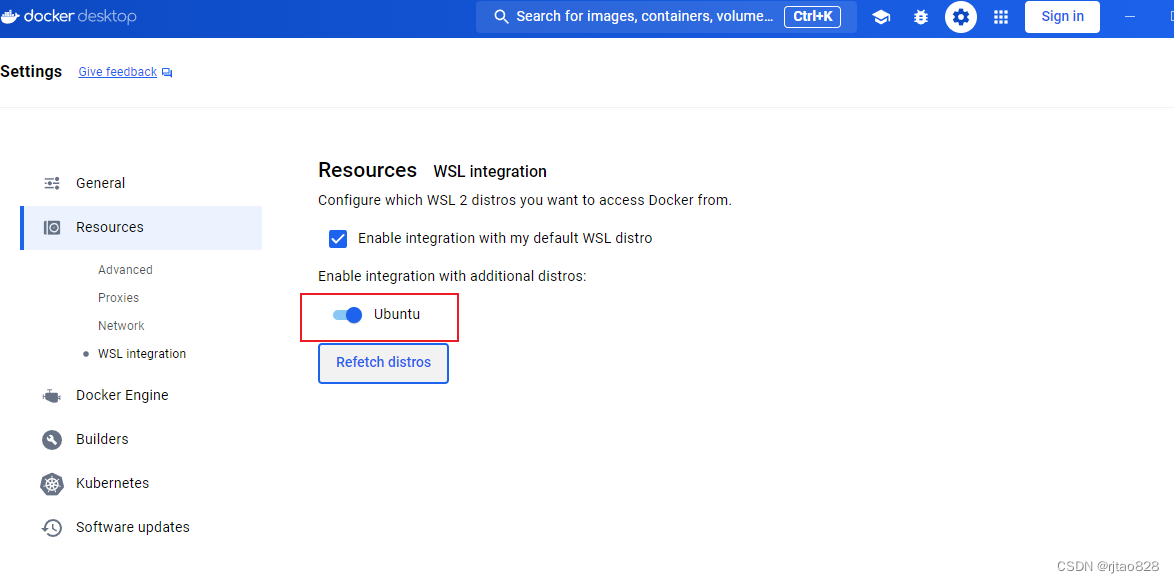
启用Ubuntu
好了,ok。
3、通过docker部署fastGPT
看这一步:
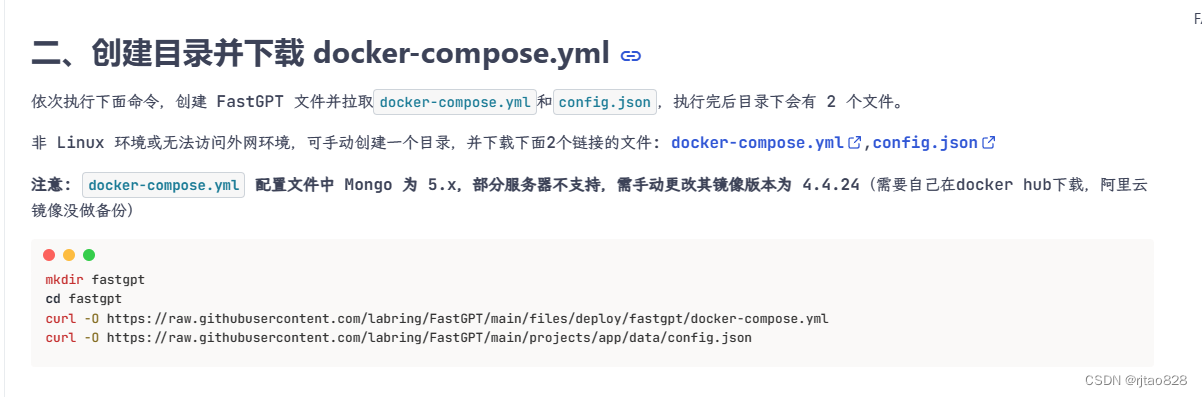
我们建立,在windows终端中建立目录,并执行:
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/files/deploy/fastgpt/docker-compose.yml
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json可以看到这两个文件:

如果因为网络不能执行成功,官方贴心的放到了文档里,点击下载:

再看下一步:
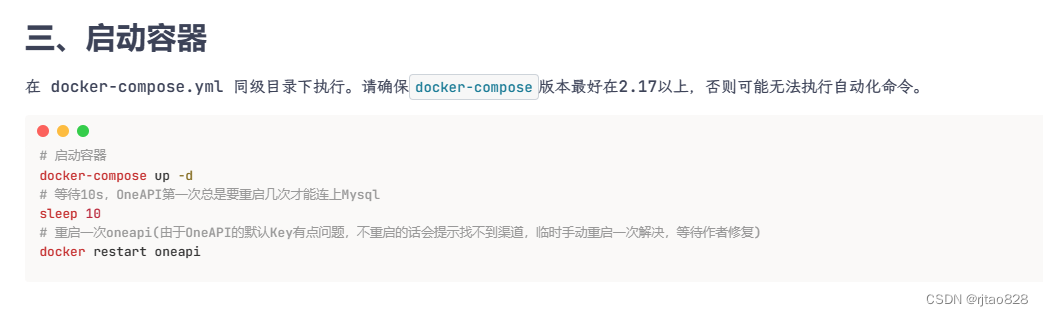
运行:
# 启动容器
docker-compose up -d
# 等待10s,OneAPI第一次总是要重启几次才能连上Mysql
sleep 10
# 重启一次oneapi(由于OneAPI的默认Key有点问题,不重启的话会提示找不到渠道,临时手动重启一次解决,等待作者修复)
docker restart oneapi运行完这里,我们可以在docker中看到容器的运行情况:
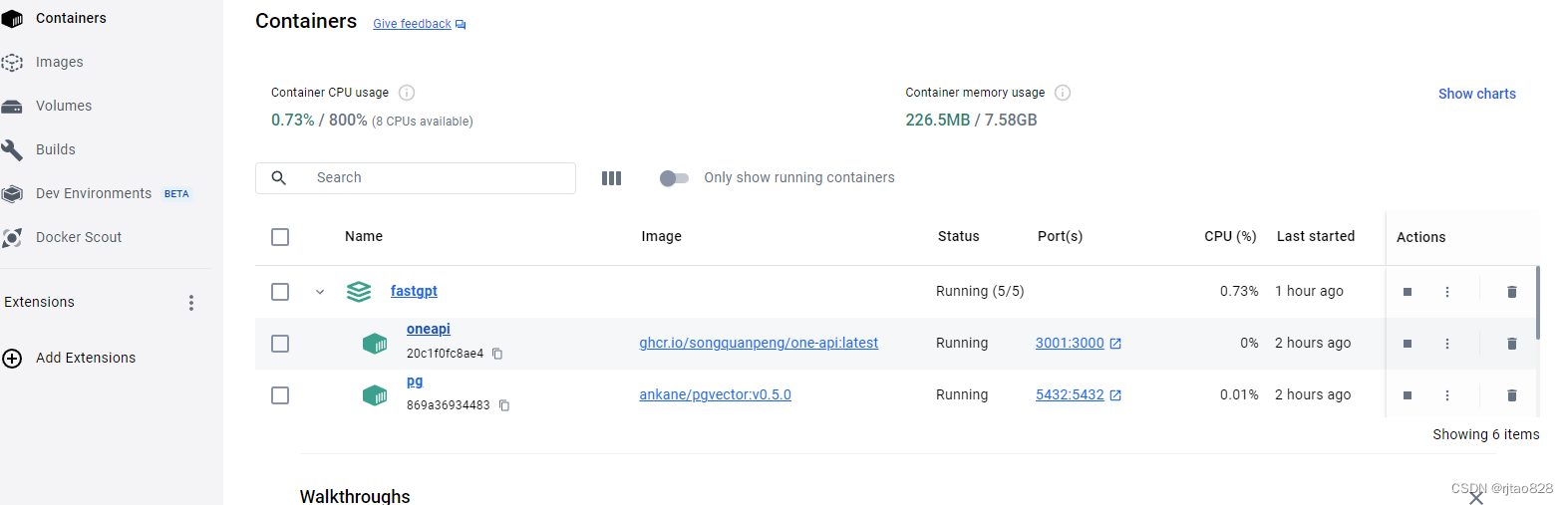
fastGPT已经在正常运行了。我们登录本地127.0.0.1:3000可以看到登录界面:

这时输入:
账号:root
密码1234,就可以登录fastGPT了。
但是我们需要先把oneapi跑通
4、调试Oneapi
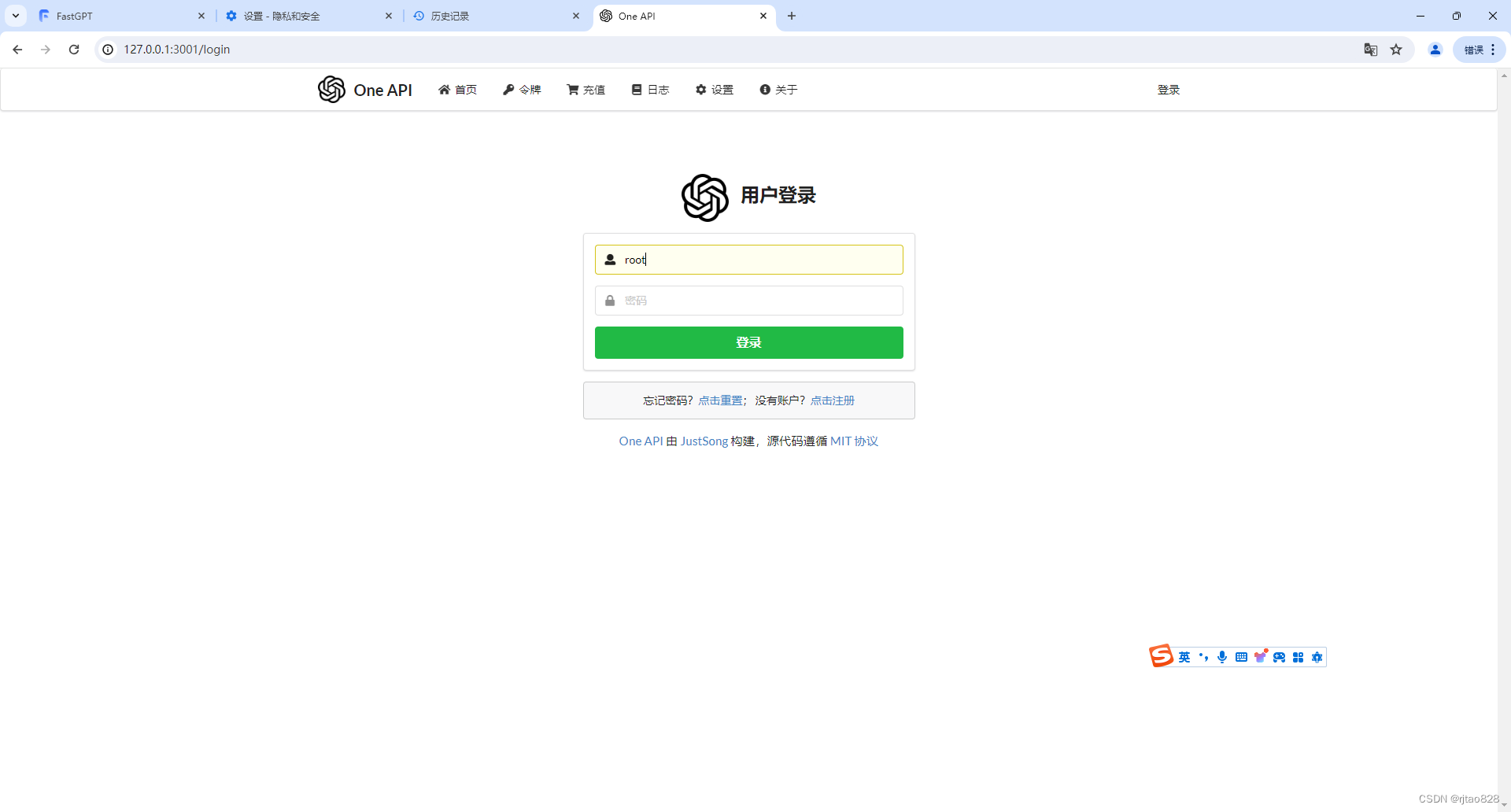
账户:root 密码:123456
登录后需要修改为8位数。
添加渠道:

设置如下:
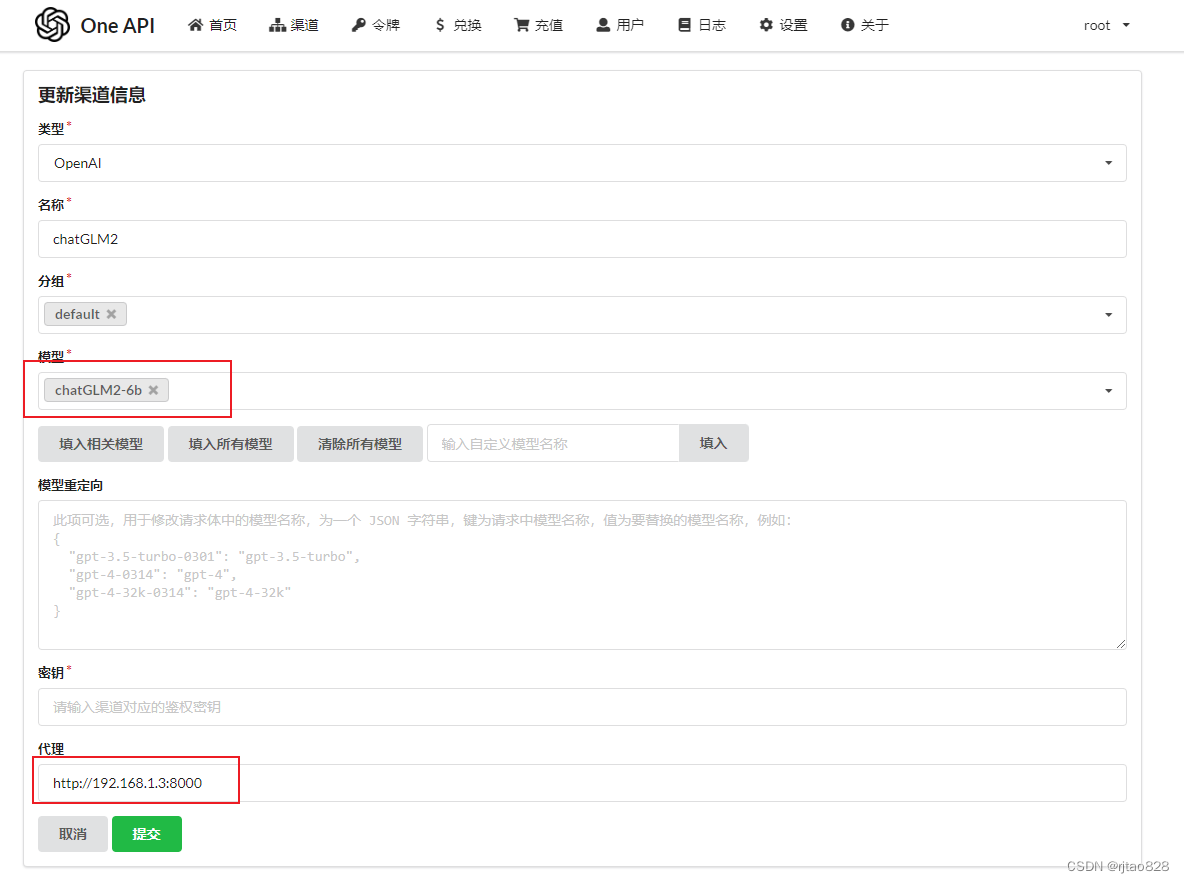
重点是模型名称和代理那里,模型名称后续需要严格一致,模型名称自定义一个,点击填入即可。
代理要设置成本地IP加8000端口,又不能带v1。
本地ip通过ipconfig进行查看。
对于本地chatGLM,密钥那里应该可以空着,没事,要么就填个none。
点击提交。
点击测试:
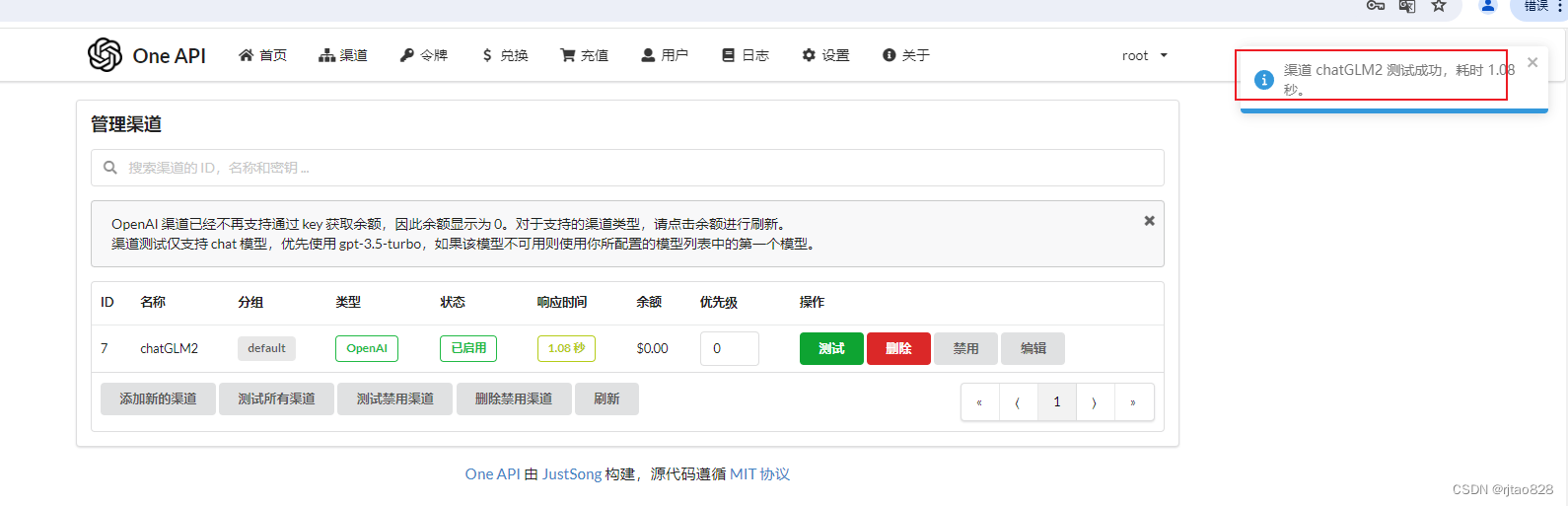
正确配置是能够测试成功的!
再建立一个令牌:
选择我们建立那个模型:
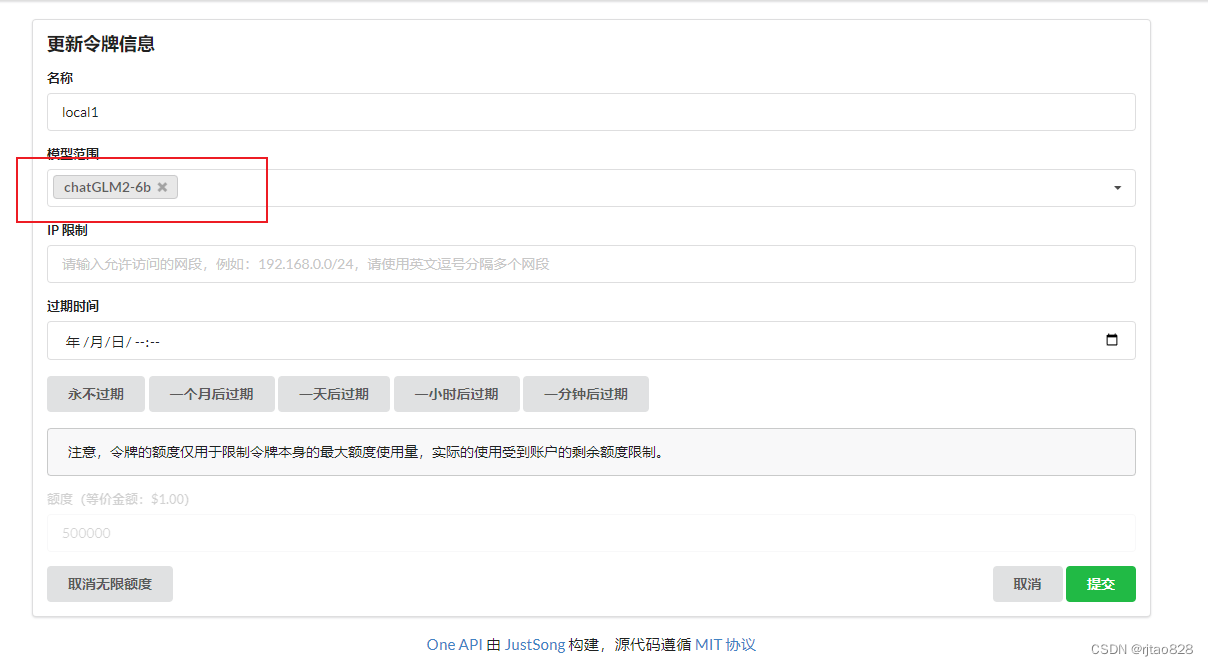
我们可以通过postman进行测试:
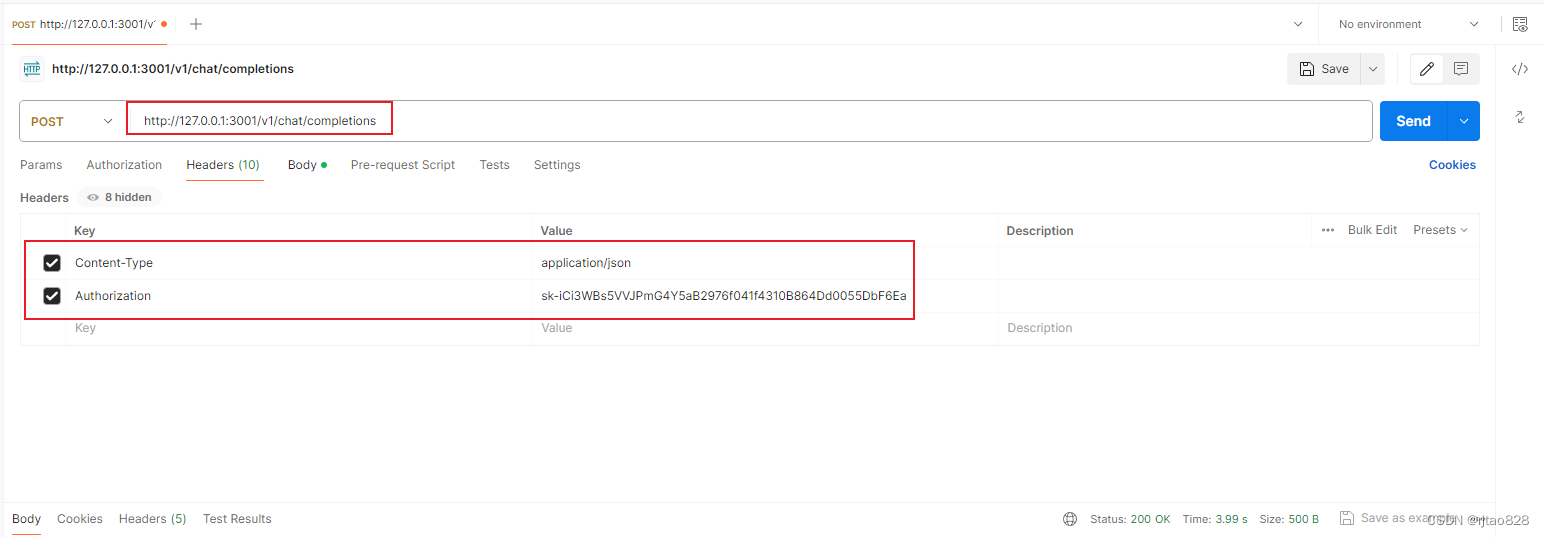
模型名称一定要严格对应:

看看回答:
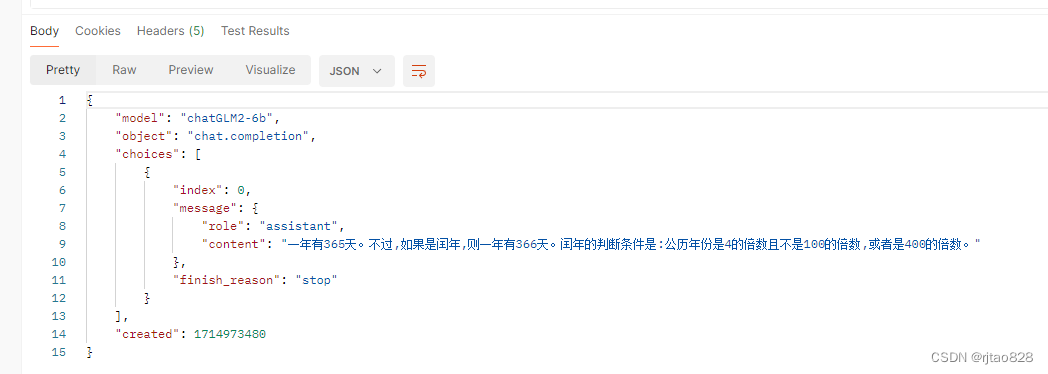
opeapi在本地是可以联通的了。
令牌这里这个聊天,可以测试对话是否能成功:
这个跟之前在本地部署的NextChat一模一样。
设置一下:

也可以测试成功:
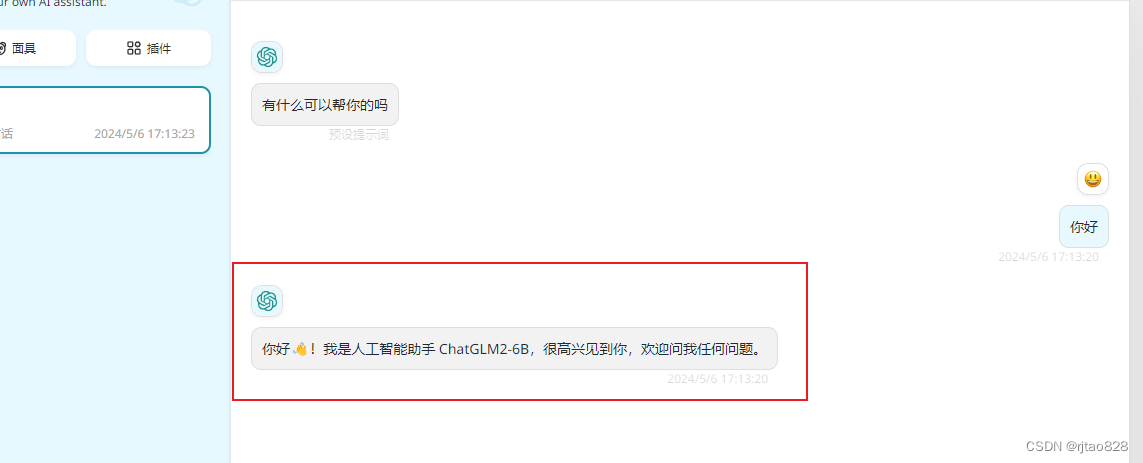
5、调试fastGPT
好了,oneapi也调试通了,可以将大模型连接到fastGPT,尝试接入知识库了吧!
网上找教程:例如这个:
全部本地化!ChatGLM+oneapi+fastgpt+微秘+微信 部署实操_fastgpt 微信-CSDN博客
以及这个搭桥!接通本地大模型+知识库,部署one api搞掂,让知识库拥有大模型能力!17/45 - 知乎 (zhihu.com)
但是主要涉及两个配置:
一是:

二是:

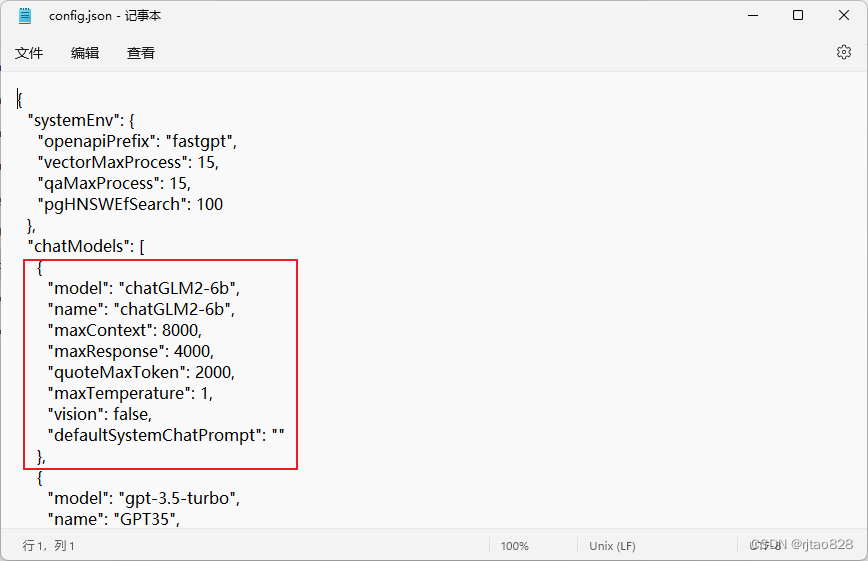
这里面有两个坑。首先这些教程中的fastGPT版本都是4.6.8以前的版本。这在config.json中体现为:

就是前面chatModels那里,需要现在改成这样了.
后边我因为没有跑通,直接进行降级了,但最终的原因不是那个。
降级操作:
调整docker-compose.yml文件中的版本号:

执行:
docker-compose pull
docker-compose up -d其实也是官方文档:

但这里有需要之前版本config.json文件,需要的进行复制-保存即可:
{
"systemEnv": {
"openapiPrefix": "fastgpt",
"vectorMaxProcess": 15,
"qaMaxProcess": 15,
"pgHNSWEfSearch": 100
},
"chatModels": [
{
"model": "chatGLM2-6b",
"name": "chatGLM2-6b",
"maxContext": 8000,
"maxResponse": 4000,
"quoteMaxToken": 2000,
"maxTemperature": 1,
"vision": false,
"defaultSystemChatPrompt": ""
},
{
"model": "gpt-3.5-turbo",
"name": "GPT35",
"inputPrice": 0,
"outputPrice": 0,
"maxContext": 4000,
"maxResponse": 4000,
"quoteMaxToken": 2000,
"maxTemperature": 1.2,
"censor": false,
"vision": false,
"defaultSystemChatPrompt": ""
},
{
"model": "gpt-3.5-turbo-16k",
"name": "GPT35-16k",
"maxContext": 16000,
"maxResponse": 16000,
"inputPrice": 0,
"outputPrice": 0,
"quoteMaxToken": 8000,
"maxTemperature": 1.2,
"censor": false,
"vision": false,
"defaultSystemChatPrompt": ""
},
{
"model": "gpt-4",
"name": "GPT4-8k",
"maxContext": 8000,
"maxResponse": 8000,
"inputPrice": 0,
"outputPrice": 0,
"quoteMaxToken": 4000,
"maxTemperature": 1.2,
"censor": false,
"vision": false,
"defaultSystemChatPrompt": ""
},
{
"model": "gpt-4-vision-preview",
"name": "GPT4-Vision",
"maxContext": 128000,
"maxResponse": 4000,
"inputPrice": 0,
"outputPrice": 0,
"quoteMaxToken": 100000,
"maxTemperature": 1.2,
"censor": false,
"vision": true,
"defaultSystemChatPrompt": ""
}
],
"qaModels": [
{
"model": "gpt-3.5-turbo-16k",
"name": "GPT35-16k",
"maxContext": 16000,
"maxResponse": 16000,
"inputPrice": 0,
"outputPrice": 0
}
],
"cqModels": [
{
"model": "gpt-3.5-turbo",
"name": "GPT35",
"maxContext": 4000,
"maxResponse": 4000,
"inputPrice": 0,
"outputPrice": 0,
"toolChoice": true,
"functionPrompt": ""
},
{
"model": "gpt-4",
"name": "GPT4-8k",
"maxContext": 8000,
"maxResponse": 8000,
"inputPrice": 0,
"outputPrice": 0,
"toolChoice": true,
"functionPrompt": ""
}
],
"extractModels": [
{
"model": "gpt-3.5-turbo-1106",
"name": "GPT35-1106",
"maxContext": 16000,
"maxResponse": 4000,
"inputPrice": 0,
"outputPrice": 0,
"toolChoice": true,
"functionPrompt": ""
}
],
"qgModels": [
{
"model": "gpt-3.5-turbo-1106",
"name": "GPT35-1106",
"maxContext": 1600,
"maxResponse": 4000,
"inputPrice": 0,
"outputPrice": 0
}
],
"vectorModels": [
{
"model": "text-embedding-ada-002",
"name": "Embedding-2",
"inputPrice": 0,
"outputPrice": 0,
"defaultToken": 700,
"maxToken": 3000,
"weight": 100
}
],
"reRankModels": [],
"audioSpeechModels": [
{
"model": "tts-1",
"name": "OpenAI TTS1",
"inputPrice": 0,
"outputPrice": 0,
"voices": [
{ "label": "Alloy", "value": "alloy", "bufferId": "openai-Alloy" },
{ "label": "Echo", "value": "echo", "bufferId": "openai-Echo" },
{ "label": "Fable", "value": "fable", "bufferId": "openai-Fable" },
{ "label": "Onyx", "value": "onyx", "bufferId": "openai-Onyx" },
{ "label": "Nova", "value": "nova", "bufferId": "openai-Nova" },
{ "label": "Shimmer", "value": "shimmer", "bufferId": "openai-Shimmer" }
]
}
],
"whisperModel": {
"model": "whisper-1",
"name": "Whisper1",
"inputPrice": 0,
"outputPrice": 0
}
}
好了,继续。开始配置:
修改docker-compose.yml:
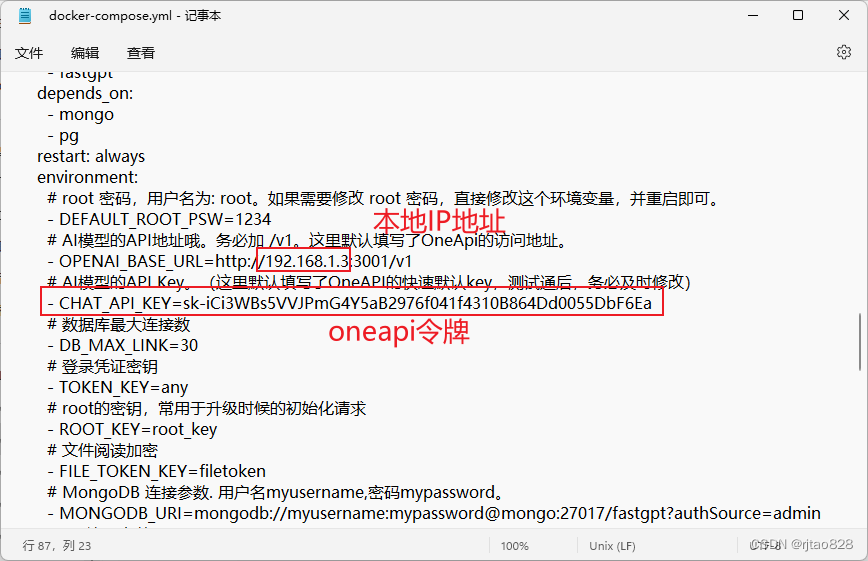
按照教程中的填写本地IP地址就可以访问成功了:

再修改config.json:
然后再执行拉取,更新操作:
docker-compose pull
docker-compose up -d
应该就能完美运行了!
但是我试试:


docker命令执行成功。
登录fastGPT,建立应用,并聊天对话:
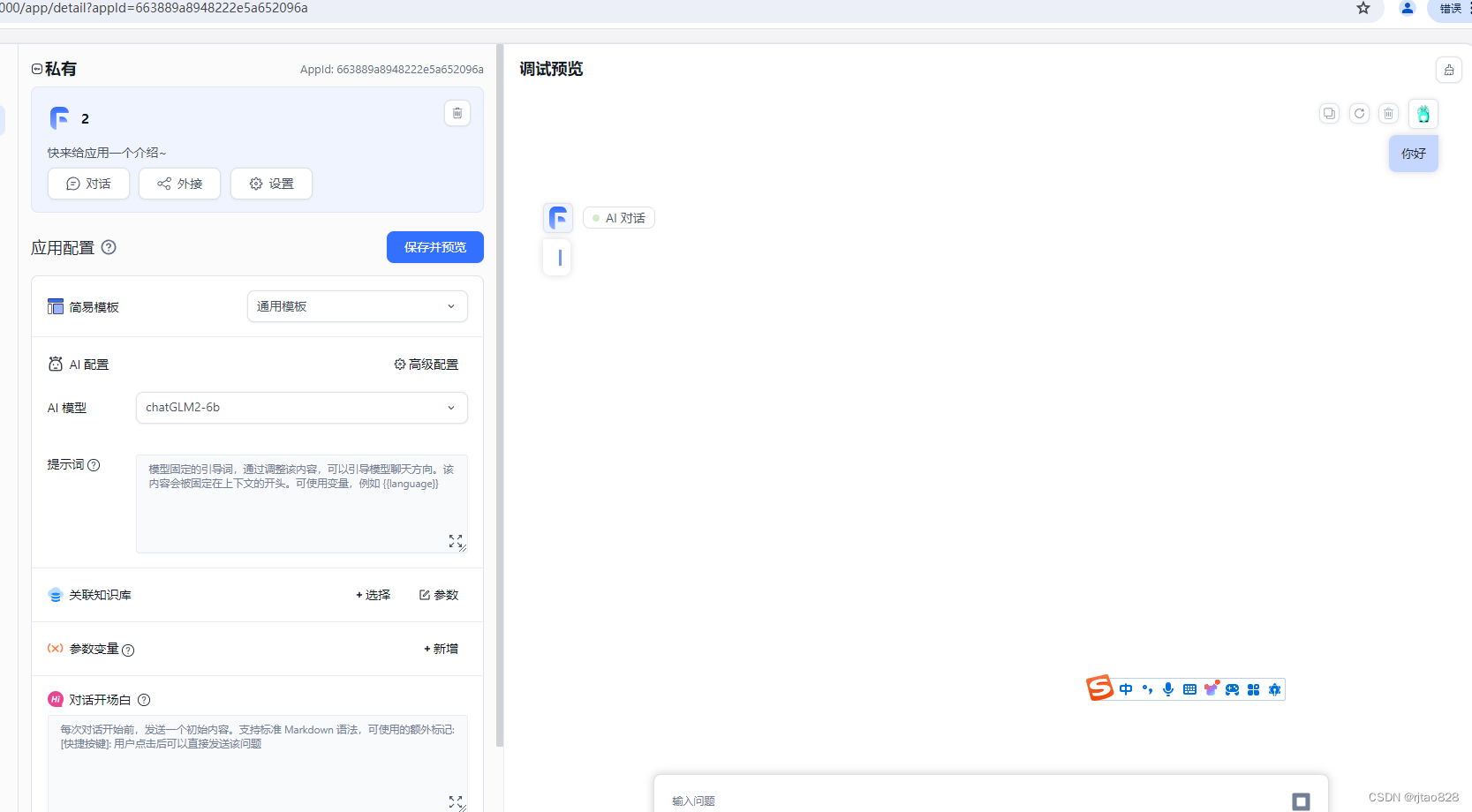
嗯?卡半天,然后不成功!
6、解决stack: 'Error: Connection error.\n'报错,成功连接本地大模型
在dockerdesktop中查看fastGPT日志:
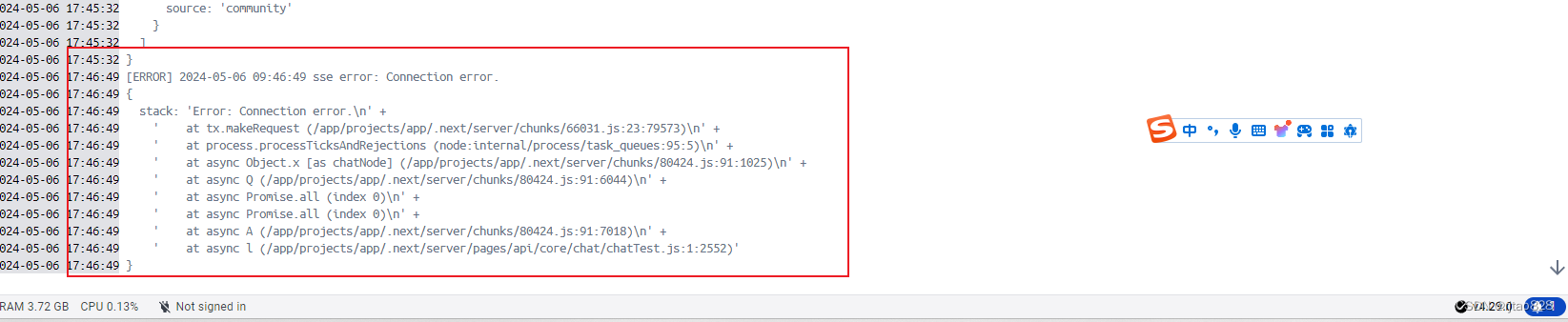
就报连接超时!
我仔细对比,没有什么不同啊啊,看社区别人提bug,都说是网络问题,但是问题出在哪里呢?我们本地调用3001端口没有问题,ping192.168.1.3也没问题。
设置防火墙、降低fastGPT版本这些都试了,但还是不行!
卡了好久!
最后、最后、最后!
还是百度好使啊!
看这个博客:
Fastgpt+oneapi均使用docker部署报错Connection error_fastgpt connection error.-CSDN博客
原来 docker-compose.yml文件配置的这地址是个巨坑!!!!
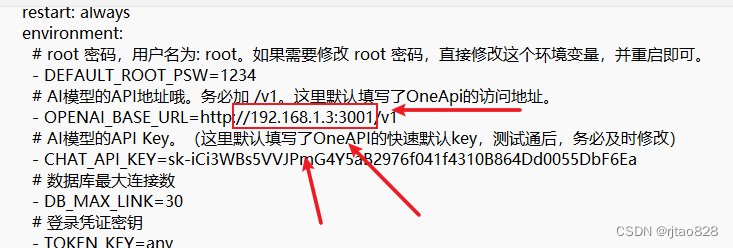
我们采用docker部署的地址不是本地IP,而是:

而是docker里面这个虚拟的IP地址:
替换:
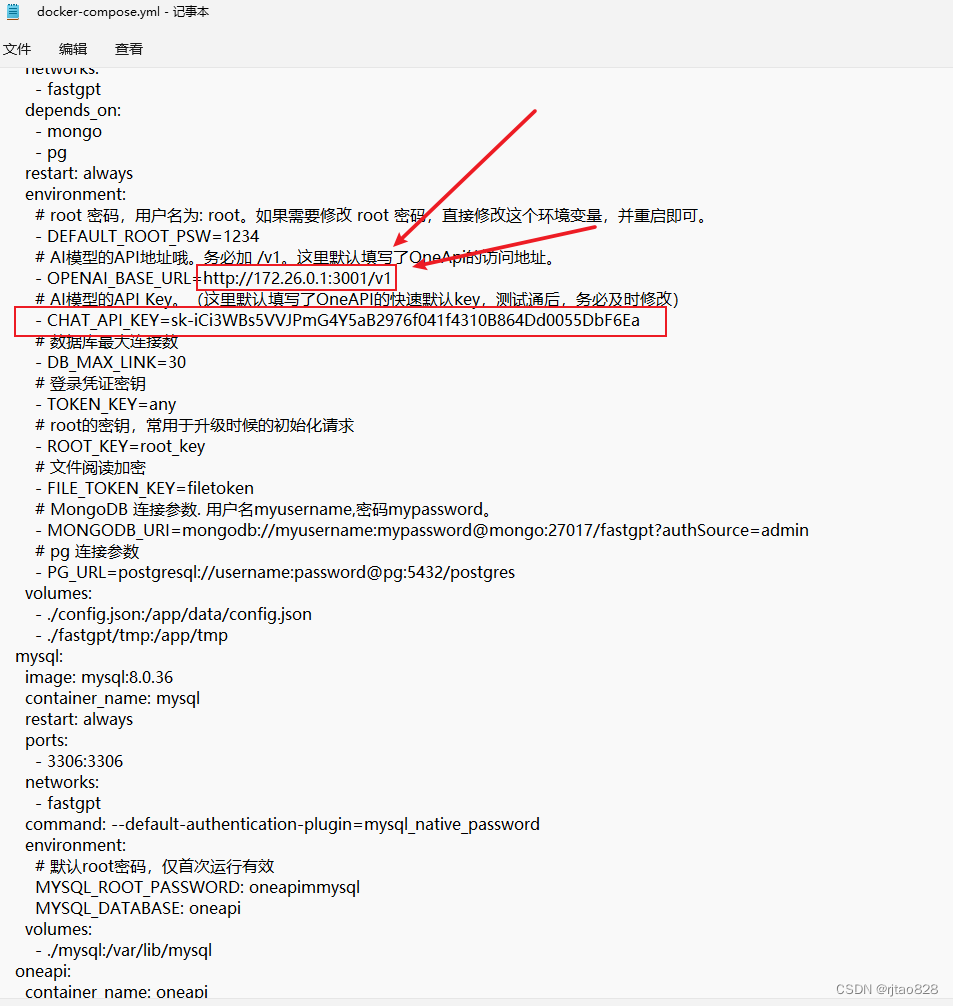
再执行:
docker-compose pull
docker-compose up -d
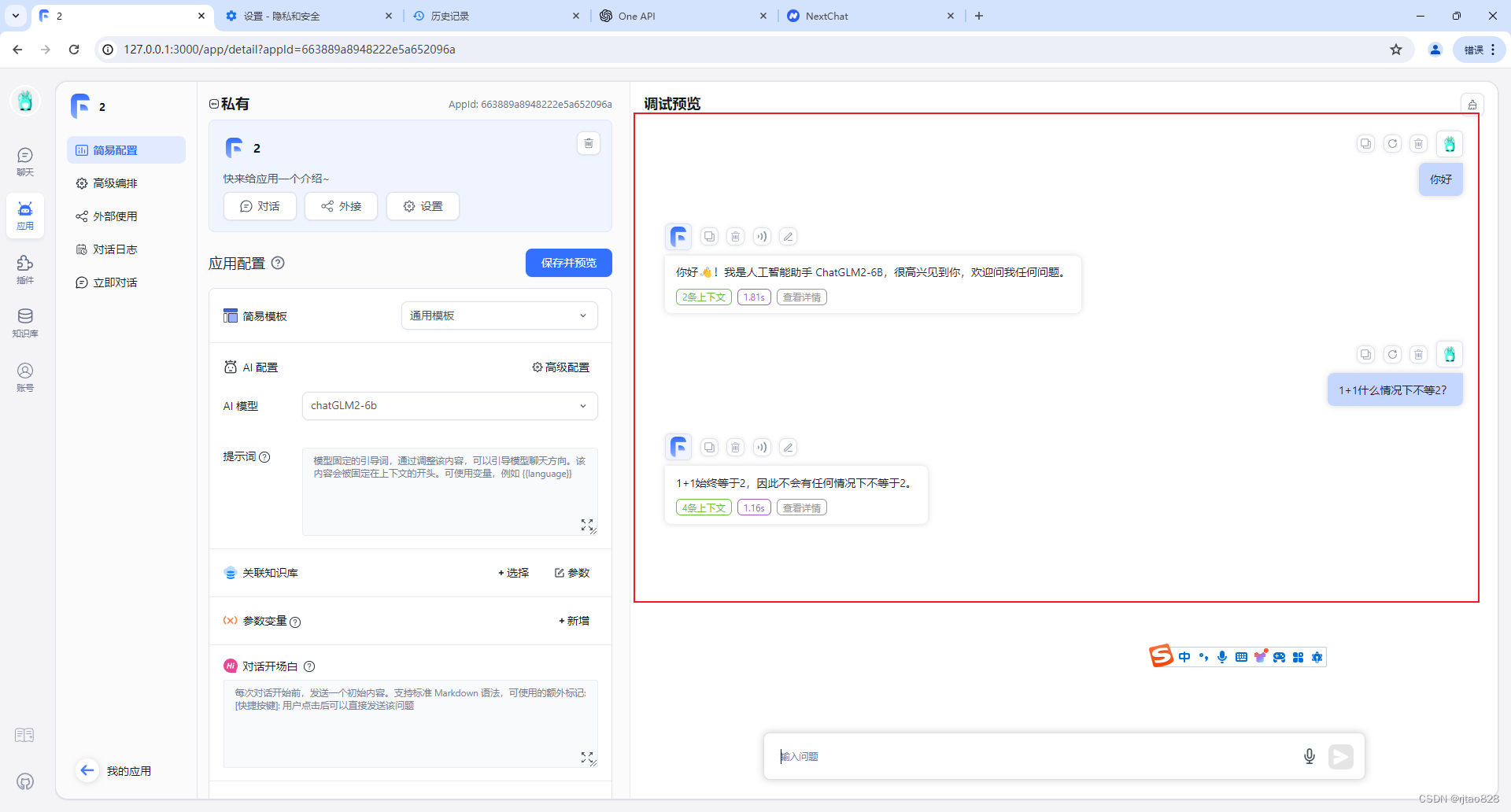
啊啊啊啊,哇哦,终于搞通了!
下一步,可以尝试再部署向量模型,或者接入知识库了!















 4624
4624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









