






Qwen-VL: 大规模视觉语言模型的全面介绍
https://arxiv.org/pdf/2308.12966
简介
Qwen-VL 是一个前沿的大规模视觉语言模型(LVLM),设计用于增强视觉和语言模态之间的交互能力。基于 Qwen-LM 模型,Qwen-VL 集成了视觉编码器、位置感知的视觉语言适配器以及多阶段训练流程,扩展了从文本到图像的理解能力。
Qwen-VL 不仅支持传统的任务,如图像描述和视觉问答(VQA),还能够执行更复杂的视觉任务,例如细粒度的对象检测和图像中的文本识别。通过多阶段的训练框架和大规模数据的应用,Qwen-VL 在多个视觉语言任务中展现了出色的性能。本文将深入探讨其架构、方法论和应用场景。
模型架构
Qwen-VL 的架构由三个核心组件构成:
-
大规模语言模型 (LLM):
- Qwen-VL 使用 Qwen-7B 模型作为核心,初始化时采用来自 Qwen-LM 的预训练权重。这个大规模语言模型极大提升了模型处理复杂语言输入的能力,尤其是在与视觉数据结合时。
-
视觉编码器 (Visual Encoder):
- Qwen-VL 的视觉编码器基于 Vision Transformer (ViT),特别是来自 OpenCLIP 的 ViT-bigG 版本。编码器通过将输入图像调整大小并分割成图像块(patches),将其转换为图像特征序列,用于后续任务。
-
位置感知的视觉语言适配器 (Position-aware Vision-Language Adapter):
- 为了有效处理长序列的图像特征,Qwen-VL 采用了位置感知的适配器,使用 交叉注意力机制 (Cross-Attention Mechanism),将图像特征压缩为固定长度的表示(256个tokens)。模型还使用了二维绝对位置编码,以确保在压缩过程中不会丢失图像中的细粒度位置信息。这些压缩后的图像特征随后被传入语言模型进行进一步处理。
输入与输出
-
图像输入 (Image Input):
- 图像通过视觉编码器和适配器处理,生成固定长度的图像特征序列。为区分图像特征输入与文本特征输入,模型在图像特征序列的开头和结尾添加了特殊标记
<img>和</img>。
- 图像通过视觉编码器和适配器处理,生成固定长度的图像特征序列。为区分图像特征输入与文本特征输入,模型在图像特征序列的开头和结尾添加了特殊标记
-
边界框输入与输出 (Bounding Box Input and Output):
- Qwen-VL 的模型支持细粒度视觉理解,通过在训练过程中引入区域描述、问题和检测数据。边界框经过归一化处理并转换为特定字符串格式:
(X_{topleft}, Y_{topleft}), (X_{bottomright}, Y_{bottomright})。为确保对象检测和文本的对齐,模型使用<box>和</box>特殊标记,并通过<ref>和</ref>标记关联边界框与描述内容。
- Qwen-VL 的模型支持细粒度视觉理解,通过在训练过程中引入区域描述、问题和检测数据。边界框经过归一化处理并转换为特定字符串格式:
训练流程
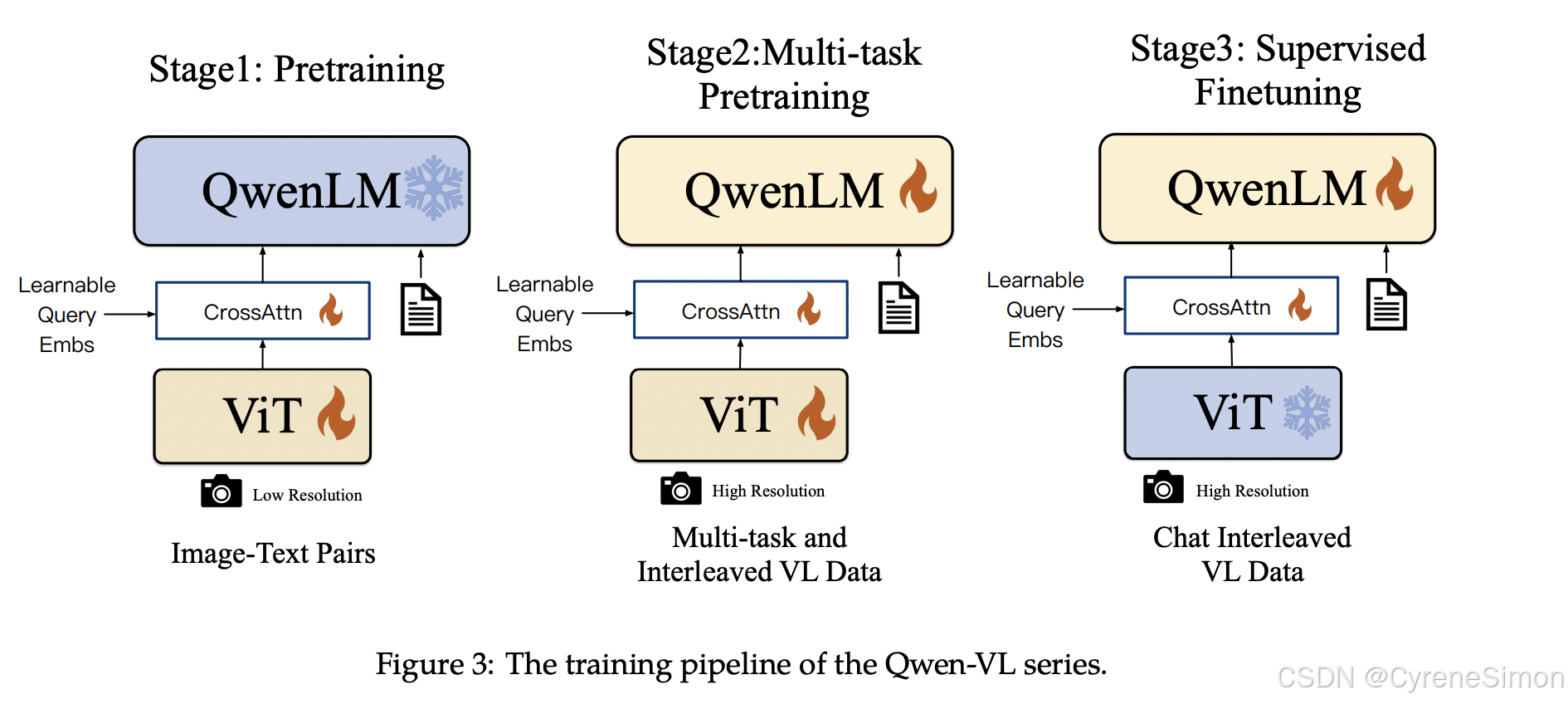
Qwen-VL 的训练流程分为三个阶段:
-
预训练阶段 (Pre-training):
- 第一阶段使用大规模的网络抓取图像-文本对数据集进行预训练。清理后,数据集包括 14 亿图像-文本对(77.3% 英文,22.7% 中文)。训练目标是通过交叉熵损失优化文本标记预测的准确性。
- 学习基础的视觉-语言对齐:预训练阶段的主要目的是通过大量的图像-文本对数据集,学习图像特征和文本特征之间的基本对齐关系
-
多任务预训练阶段 (Multi-task Pre-training):
- 在第二阶段,模型在多个任务上进行细调,例如图像描述、视觉问答(VQA)和细粒度对象检测。输入图像的分辨率提高至 448x448,模型使用高质量的标注数据进行训练,进一步提升性能。
- 提升模型的多任务能力和细粒度理解能力:通过同时训练多个视觉语言任务,进一步提升模型在不同任务(如图像描述、视觉问答、对象检测)中的表现
-
监督微调阶段 (Supervised Fine-tuning):
- 在最后的监督微调阶段,模型进行指令微调,以优化其处理多模态对话和复杂多图像输入的能力。通过高质量的数据集,Qwen-VL 在多轮对话和图像推理任务中表现卓越。
- 提升模型的指令跟随能力和多模态对话理解能力:这个阶段的训练目标是使模型能够处理更加复杂的多模态任务,例如多轮对话和多图像输入的场景
关键创新点
-
位置感知的视觉语言适配器 (Position-aware Vision-Language Adapter):
- Qwen-VL 的一大创新点是其 位置感知视觉语言适配器,该适配器能够在保留重要位置信息的前提下,压缩长序列图像特征。这样确保了即使在压缩后的数据中,模型仍然能够准确定位图像中的对象。
-
多任务和多语言支持:
- 由于训练使用了多样化的跨语言数据集,Qwen-VL 自然支持中英文任务,在多语言应用中表现出色。此外,其同时支持多个任务的能力,使其能够灵活应对不同的视觉语言问题。
-
多图像处理能力:
- Qwen-VL 具备同时处理多张图像的能力,适用于需要比较或理解多图像上下文的复杂任务。这个特性使得模型在现实场景中的应用更加广泛。
应用场景
Qwen-VL 在多个领域的任务中表现优异,包括但不限于以下应用场景:
- 图像描述 (Image Captioning):根据输入图像生成准确的描述文本。
- 视觉问答 (Visual Question Answering, VQA):根据图像内容回答复杂问题。
- 视觉定位 (Grounding):通过文本描述精确定位图像中的对象。
- 光学字符识别 (OCR):读取并理解图像中的文本信息。
- 细粒度对象检测与描述:识别并描述复杂图像中的细节对象。
结论
Qwen-VL 在大规模视觉语言模型的发展中迈出了重要的一步。通过整合复杂的组件,如视觉语言适配器,并使用多任务训练和大规模数据集,Qwen-VL 在多个视觉语言基准上达到了最先进的水平。其支持多语言任务,结合细粒度对象识别和多轮对话能力,使其成为实际应用中极具潜力的解决方案,包括交互式AI系统、图像识别和自动化系统等。
Qwen-VL 在架构设计、训练方法和多模态理解上的创新,使其在视觉语言领域中占据了领先地位。
dataset
图像-文本对 (Image-Text Pairs)
Qwen-VL 的预训练使用了大规模的网络抓取图像-文本对数据集,包含以下几个重要数据集:
LAION-en:来自 LAION 的大规模英文数据集。
LAION-zh:对应的中文数据集。
LAION-COCO:从 LAION-en 生成的合成数据。
DataComp:另一组图像-文本对数据。
Coyo:网络抓取的图像-文本对数据集。
CC12M、CC3M、SBU、COCO Caption:常用于图像描述任务的学术数据集。
为了确保数据质量,数据集经过以下清理步骤:
删除纵横比过大的图像-文本对。
过滤掉尺寸过小的图像。
应用数据集特定的 CLIP 分数,过滤低质量样本。
移除包含非英文或非中文字符的文本。
排除包含表情符号的文本。
删除长度过短或过长的文本。
清理文本中的 HTML 标签。
移除不规则文本模式。
视觉问答 (VQA)
在 VQAv2 数据集中,Qwen-VL 通过最大置信度选择答案注释。对于其他 VQA 数据集(如 GQA、VGQA 和 DocVQA),没有进行特别的修改。
定位任务 (Grounding)
定位任务的数据集包括 GRIT,该数据集包含递归的定位框标签。Qwen-VL 使用一种贪心算法清理数据,确保每张图像包含最多的非递归标签。在其他定位数据集中,边界框坐标与相应的名词或短语进行简单拼接。
OCR (光学字符识别)
Qwen-VL 使用 Synthdog 工具生成合成 OCR 数据集,特别是使用了 COCO (Lin et al., 2014) 的 train2017 和 unlabeld2017 数据集作为自然场景背景。
然后,选择了 41 种英文字体和 11 种中文字体来生成文本。模型使用 Synthdog 中的默认超参数,并跟踪生成的文本在图像中的位置,将它们转换为四边形坐标,并将这些坐标作为训练标签。
PDF 数据预处理:
对于所有 PDF 数据,使用 PyMuPDF 进行预处理,提取每个页面的渲染结果以及文本注释和其边界框。具体步骤如下:
提取每个页面的所有文本及其边界框。
渲染每个页面并保存为图像文件。
移除过小的图像。
移除字符过多或过少的图像。
移除包含“Latin Extended-A”和“Latin Extended-B”块中 Unicode 字符的图像。
移除包含“Private Use Area (PUA)”块中 Unicode 字符的图像。
HTML 数据预处理:
对于收集的所有 HTML 网页,处理方法与 PDF 类似,但使用了 Puppeteer 进行渲染,获取 HTML 页面中的地面真值注释。具体步骤包括:
提取每个网页的所有文本。
渲染每个网页并保存为图像文件。
移除过小的图像。
移除字符过多或过少的图像。
移除包含“Private Use Area (PUA)”块中 Unicode 字符的图像。

















 3229
3229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









