






1、引言
机器学习算法在最近几年的热度一直居高不下,尤其当Transformer架构的大模型出来以后,机器学习、人工智能有关的算法热度又上升了一个台阶。在机器学习的世界中有一定理:没有免费的午餐[1],该定理说的是在众多机器学习的算法中,没有普遍优越的机器学习算法。简言之,当我们拿到了一份数据时,是应该选择随机森林、还是人工神经网络或深度学习,亦或是支持向量机,这些并非是在拿到数据前就已经确定了的,而是通过算法在数据上的反馈,让我们最终决定到底选择哪个算法完成最终建模。
既然如此,在进行一个机器学习模型的构建时,研究某种算法是否适用本次建模的意义或许并不大,因为我们完全可以将多种算法均应用到当前数据集,选择效果最好的算法继续深入建模。反而一些算法之外的处理流程往往能够决定建模效果,是我们需要注意的。本次就来讨论关于机器学习建模的流程及其用DMSAS (下载地址:www.dmsas.cn) 该如何实现。
2、数据集准备
机器学习的建模目的与经典统计分析不同,前者是用来对研究者手中的数据做出判断或预测的,而后者一般是用来解释变量之间相互关系,或通过抽样数据揭示某种总体分布规律的。尽管当前已有学者开始对机器学习的可解释性做出研究[2],但尚未完全普及。既然如此,若训练一个监督分类模型,其目的不是为了对手中的未知样本做预测而是为了探讨特征向量对结果的影响程度就有些“南辕北辙”了 (这个并非绝对的,也要依据研究目的而定)。
因此,在建模前一定要准备如下三份数据集:
训练集:输入给模型,让其通过学习这份数据集完成建模;
验证集(测试集):当模型“自认为”已经完成了训练集的学习后,在此数据集上运行,测试建模效果,通过效果评估,研究者可以观察当前的模型是否已达要求;
预测集:完成整个训练后,将模型应用在该份数据集,完成模型预测。
2.1 拆分训练集与预测集
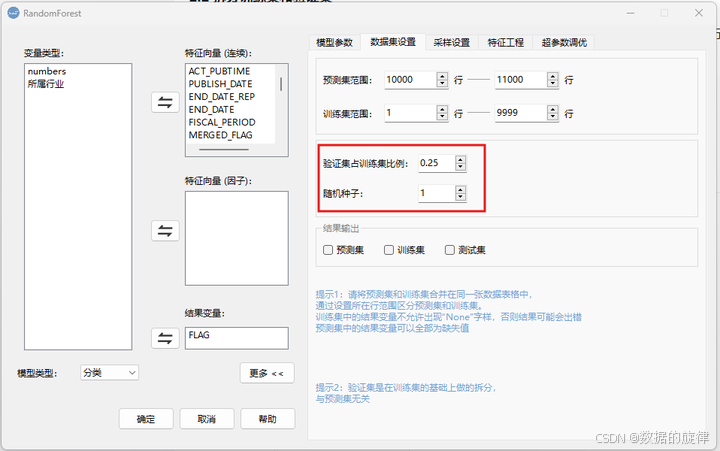
Step1:分析 → 机器学习 → 随机森林 → 更多 → 数据集设置
Step2:在当前页面选择预测集占据的行范围和训练集占据的行范围即可完成拆分
 将预测集放置在整份数据集的10000-11000行,训练集为1-9999行
将预测集放置在整份数据集的10000-11000行,训练集为1-9999行
2.2 拆分训练集和验证集
完成预测集的拆分后,再将训练集提出一部分做为测试集,例如下图的设定表示在1-9999行中,有25%的数据会被随机组合成测试集,另外的75%则被组合成训练集,该部分训练集才是真正训练模型建模的数据。
3、类别不平衡问题
在一些现实的分类任务中,不同类型的训练样例数据可能差别很大。例如:一所医院构建了一个模型用来预测谁是癌症患者,这个案例可能取得的有效训练样例中,有99%的人并非得了癌症(反例),只有1%的人患癌(正例)。那么该医院建立的机器学习模型只需将所有病人都预测为非癌症患者,模型的准确率即可达到99%。然而这样的学习器往往没有任何价值,因为它不能预测出任何正例。
假如我们使用了一个线性分类学习器,我们用如下公式对未知样本 x 进行分类时,实际是用一个阈值与预测出的 y 值做比较,若 y 大于该阈值则预测为正例,小于则为反例。
y
=
w
T
×
x
+
b
y = w^{T}\times x + b
y=wT×x+b
通常情况下,分类器都遵循如下的判断规则:
若 y 1 − y > 1 \frac{y}{1-y} > 1 1−yy>1 判断为正例,否则为反例
这一规则默认将阈值设置为了0.5,当数据集中的样本类别不平衡时,阈值为0.5来做判断就变得极不科学。换言之,假设有m个正例和n个反例,则当
y
1
−
y
>
m
n
\frac{y}{1-y} > \frac{m}{n}
1−yy>nm 时,即可将本次预测判断为正,不需要大于1。要做到这一点,我们需对分类器的判断规则做出适当调整:
y
′
1
−
y
′
=
y
1
−
y
×
n
m
\frac{y^{'}}{1-y^{'}} = \frac{y}{1-y} \times \frac{n}{m}
1−y′y′=1−yy×mn
这一调整的基本策略被称为“再缩放”(rescaling)[3],当前再缩放技术大体上有三种:欠采样 (undersampling)、过采样 (oversampling) 和阈值移动 (threshold-moving)。
欠采样技术:通过某些算法去除一些多数类样本,让正、反例的样本量趋于平衡,其中代表性算法是随机欠采样 (RandomUnderSampler);
过采样技术:通过某些算法增加一些少数类样本,让正、反例的样本量趋于平衡,其中代表性算法是SMOTE过采样法;
阈值移动:直接基于原始训练集学习,在训练好了的分类器进行预测时,通过研究者手动判断修改阈值,得到分类结果。
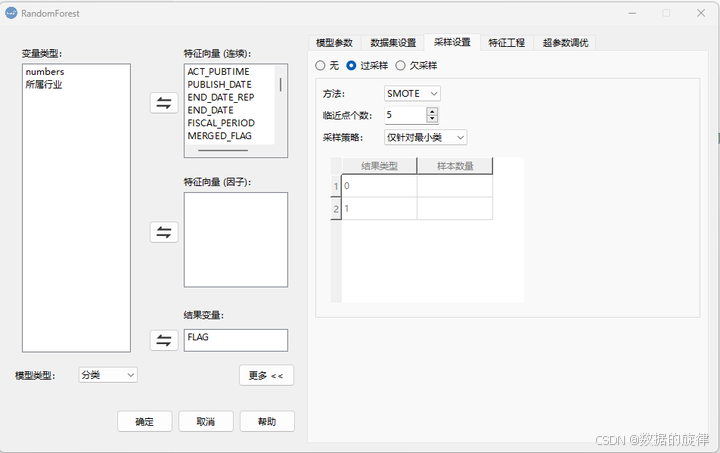
DMSAS中提供了前两种缩放方式,操作流程如下 (以随机森林为例):
Step1:分析 → 机器学习 → 随机森林 → 更多 → 采样设置
Step2:选择对应的再缩放技术及对应的采样算法
4、特征工程
一些机器学习的任务中有时会收集很多变量,其中可能存在冗余变量,它们与当前要解决的学习任务无关,这将严重影响建模效率和性能。例如我们这篇文章使用到的数据集:《企业诚信纳税调查》。该数据集调查了近1万家企业,共计86项指标 (特征),最终给出该企业是否真实纳税这一结果变量。
这里的问题是,在随机森林这种集成学习算法上运行86个特征指标,可能会严重影响建模速度,更不用谈后面的超参数调优 (若您的计算机性能异常高那另当别论)。因此对86个指标做一些数据预处理工作看起来是必不可少了。
4.1 降维技术
顾名思义,“降维”就是压缩特征数量,让特征向量的“维数约简”,一般的做法是,我们可以将86个指标看成一个86维的高维空间,通过一系列数学变换将高维空间压缩成一个低维“子空间“。其中主成分分析 (PCA) 是常用的一种降维技术。
主成分分析
它的核心思想是:在一个正交属性的空间中,找到一个超平面能够对所有的样本进行恰当表达 [3]。假设投影变换后的新坐标系为
{
w
1
,
w
2
,
.
.
.
,
w
d
}
\left\{ w_{1}, w_{2}, ..., w_{d} \right\}
{w1,w2,...,wd},其中 wi 为标准正交基向量,若现在我们要进行降维,就要丢弃新坐标系中的部分坐标,丢弃后的维度为 d’,则原始样本 xi 在低维坐标系中的投影是
z
i
=
(
z
i
1
;
z
i
2
;
z
i
3
;
.
.
.
;
z
i
d
′
)
z_{i} = (z_{i1}; z_{i2}; z_{i3}; ... ;z_{id'})
zi=(zi1;zi2;zi3;...;zid′)若zi来重构xi,会得到如下公式:
x
i
~
=
∑
j
=
1
d
′
z
i
j
w
j
\tilde{x_{i}} = \sum_{j=1}^{d'}{z_{ij}w_{j}}
xi~=j=1∑d′zijwj推演至整个训练集,主成分分析的优化目标则为:
m
i
n
(
∑
1
m
(
∑
j
=
1
d
′
z
i
j
w
j
−
x
i
)
2
)
min(\sum_{1}^{m}{(\sum_{j=1}^{d'}{z_{ij}w_{j}} - x_{i}})^{2})
min(1∑m(j=1∑d′zijwj−xi)2)
s
.
t
.
W
T
W
=
I
.
s.t. W^{T}W = I.
s.t.WTW=I.降维后的维度 d′ 一般是由研究者自行指定的,而指定的参照依据往往是对原始数据方差的解释比例,一般认为降维后的数据应能解释原始数据方差比例的90%以上 (当然这个不是固定的,也根据个人需要而变)。
以下是《企业诚信纳税调查》数据集在进行了PCA降维后的碎石图展示,结果显示前20维主成分累积解释了超过92%方差比例,因此对于此份数据集来说,可以将一个86维特征的数据集降维成20维:
 前20个主成分累计解释比例超过92%
前20个主成分累计解释比例超过92%
其他降维方法
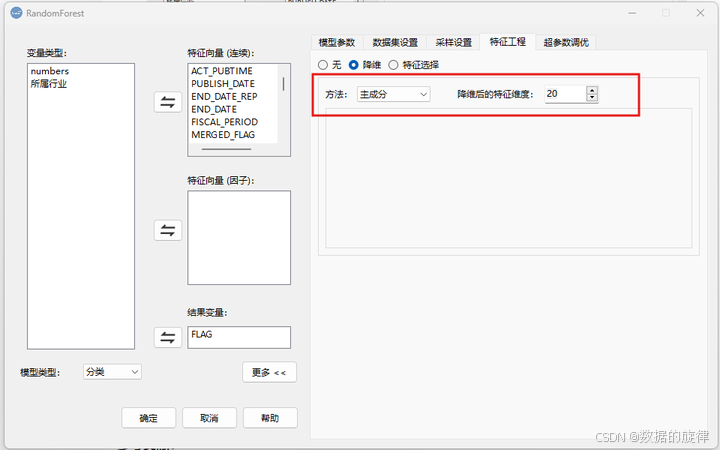
其他常用的降维算法还有多维缩放 (MDS),等度量映射 (Isomap),核主成分分析 (Kernelized PCA) 等,可以根据具体需求在DMSAS中选择使用。DMSAS中进行降维的操作步骤:
流程:分析 → 机器学习 → 随机森林 → 更多 → 特征工程 → 降维
4.2 特征选择
除了降维可以压缩特征之外,通过特征选择去除一些无用特征同样可以提升模型的运算效率,常用的特征选择手段大致可分为:过滤式、包裹式和嵌入式。
过滤式:
顾名思义就是利用规则将某些特征“过滤”掉,Relief是一个著名的过滤式特征选择方法,其核心思想就是构建一个统计量度量每个特征的重要性,通过重要性的值截取前k个特征实现过滤。
包裹式:
与过滤式不同,该种算法会直接把最终将要使用的学习器性能做为特征评价的准则。这是一种对本次学习“量身定制”的特征选择方式。所以往往包裹式特征选择的效果会优于过滤式。然而这一算法的代价为,当不断提取子集进行建模时,势必会大幅增加计算开销,事实上这种计算开销甚至比不做特征选择直接建模还要大上数倍,因此包裹式特征选择一般仅用在探索性建模阶段,DMSAS种提供了前向消元、后向消元和递归消元三种包裹式特征选择方法
嵌入式:
一些模型在建模运算时,本身也是一个特征选择的过程,我们以线性回归模型为例,其损失函数的方程式为:
m
i
n
(
∑
i
=
1
m
(
y
i
−
W
T
x
i
)
)
2
min(\sum_{i=1}^{m}{(y_{i} - W^{T}x_{i})})^{2}
min(i=1∑m(yi−WTxi))2
若特征数量过多,该模型很容易陷入过拟合,有时为了防止过拟合的出现,我们会在模型中加入正则化项,若正则化项为 λ||W||,称为L1正则化;若为 λ||W||^2,称为L2正则化。加入L1正则化后的损失函数公式为:
m
i
n
(
∑
i
=
1
m
(
y
i
−
W
T
x
i
)
)
2
+
λ
∣
∣
x
∣
∣
1
min(\sum_{i=1}^{m}{(y_{i} - W^{T}x_{i})})^{2} + \lambda \left| \left| x \right| \right|_{1}
min(i=1∑m(yi−WTxi))2+λ∣∣x∣∣1 这种方式相比L2正则化的优点在于,它更容易求得 W 为零的分量,当某一特征被计算得到的系数为0时,该特征自然就被模型剔除了,如此也可以达到特征选择的效果。
然而,该方法在一些具备正则化的算法中可以使用,但倘若遇到了无法进行正则化的算法 (例如随机森林),通过L1正则化达到特征选择的目的将无法实现,此时我们可以先将模型做为线性回归 (或逻辑斯蒂回归) 加入L1正则化,再将非零特征提取出来放入待构建的模型中,这一过程在DMSAS中,当用户将特征选择的方式调整为“L1正则化”时自动实现。
流程:分析 → 机器学习 → 随机森林 → 更多 → 特征工程 → 特征选择

5、超参数调整
超参数调整是模型建模中最重要的环节,在机器学习算法中往往存在很多需要自定义的参数,这些参数既无严格的范围约定,又深刻影响着建模的准确性。在进行建模时,这些参数往往令科研工作者头痛不已。这里以随机森林为例,它的基学习器是一棵决策树,在此基础上随机森林利用Bagging思想,从属性集合中随机选择k个属性做为子集构建决策树,随机n次就会得到n棵决策树,如此一来形成了一个“决策树森林”,再通过投票的方式最终确定其分类或回归结果。
那么:应该选择几棵树构建森林?每棵树分叉的规则应该用什么?每个树构建的深度应该是多少?每棵树的叶子节点能包括的最小样本量是多少?这些问题就变成了随机森林的超参数,我们在建模前并不清楚这些问题的具体答案,只能通过一次次的猜测,建模,评估效果,修改参数,再建模,再评估的方式,通过一次次试验最终得到最优模型。
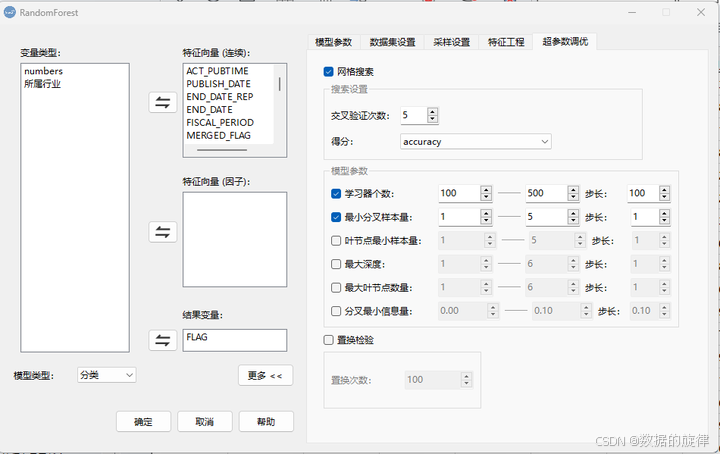
假设我们希望固定其他参数不变,让随机森林生成100、200、300…1000棵树来观察效果,此时相当于在一条直线上探索超参数的最佳方案。若变换的参数提升至两个,穷举就变成了“跳网格”,在一张网格上搜寻两个参数变换的最优组合确定建模参数。变化的参数继续增加,网格从二维平面进入到一个“超平面”,继续搜索多个参数最优组合,这就是网格搜索法设置超参数的原理。通过网格搜索,我们能够方便的确定最优参数组合,完成模型构建。
DMSAS中通过网格搜索设置超参数的步骤如下:
流程:分析 → 机器学习 → 随机森林 → 更多 → 特征工程 → 超参数调优
结束语
在机器学习的世界里,能被成为“定理”的很少。因此“没有免费的午餐”就显得格外的重要。机器学习由于其算法灵活 ,因此能够处理的数据种类繁多 (数字、文字、图片、音视频等均可),从而导致遇到的状况也格外复杂。我们在进行建模时,不仅要关注使用了哪些算法,更要关注我们手中的数据状况:它是否是一个平衡数据?它是否存在大量的噪声?它是否需要数据清洗?建模过程中应该使用怎样的超参数组合?这些问题都将严重干扰建模效果。因此,大家不仅要重视算法原理,更要重视建模的流程和数据处理,在很多场景下,后者比前者甚至更重要 !
参考文献:
[1] 伊恩·古德费洛; 约书亚·本吉奥; 亚伦·库维尔. 深度学习[M] . 北京: 人民邮电出版社. 2016: p161.
[2] Christoph Molnar. Interpretable Machine Learning: A Guide for Making Black Box Models Explainable[M]. 2023.
[3] 周志华. 机器学习[M]. 北京: 清华大学出版社. 2016.

















 3254
3254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









