







目录
一、概述
在处理器中,除了Cache之外,另一个重要的内容就是分支预测(branch prediction),它和Cache一起决定处理器的性能。
对于超标量处理器来说,准确度高的分支预测更为重要,在取指令阶段,除了需要从 I-Cache中取出多条指令,同时还需要决定下个周期取指令的地址。如果能够在取指令阶段,就可以“预知”本周期所取出的指令中是否存在分支指令,并且可以知道它的方向(跳转或者不跳转),以及目标地址(target address)的话,那么就可以在下个周期从分支指令的目标地址开始取指令,这样就不会对流水线产生影响,也就避免了做无用功,提高了处理器的执行效率。这种不用等到分支指令的结果真的被计算出来,而是提前就预测结果的过程就是分支预测。
1、分支预测的基本要素
分支预测之所以能够实现,是由分支指令的特性决定的,因为分支预测本质上是对分支指令的结果进行预测,在一般的RISC指令集中,分支指令包含两个要素。
(1)方向:对于一个分支指令来说,它的方向只可能有两种:一种是发生跳转(这称为 taken),另一种是不发生跳转(称为not taken)。有些分支指令是无条件执行的,例如MIPS中的jump指令,它的方向总是发生跳转的,而有些分支指令则需要根据指令中携带的条件是否成立来决定是否发生跳转,例如MIPS中的BEQ指令,只有当指定的两个值相等的时候,才会发生跳转。
(2)目标地址:如果分支指令的方向是发生跳转,就需要知道它跳到哪里,也就是它跳转的目标地址,这个目标地址也是携带在指令中,对于RISC指令集来说,目标地址在指令中可以有两种存在形式:
①PC relative:直接跳转(direct)。在指令中直接以立即数的形式给出一个相对于PC的偏移值(offset),当前分支指令的PC值(或者分支指令的下一条指令的PC值)加上这个偏移值就可以得到分支指令的目标地址。指令中采用32位立即数作为相对于PC的偏移值,用以计算分支指令的目标地址。由于指令长度限制,跳转范围有限。但立即数直接携带在指令中,易于在解码阶段计算目标地址,且因立即数不变,这种类型的分支指令易于进行分支预测。
②Absolute:间接跳转(indirect)。分支指令的目标地址取决于一个通用寄存器的值,该值由其他指令的执行结果决定,因此分支预测变得困难,且预测失败时的惩罚较大。这是因为需要等待执行阶段才能确定目标地址,期间进入流水线的指令可能不正确。然而,CALL/Return类型的间接跳转指令由于具有强规律性,相对容易被预测。鉴于这种情况,除了CALL/Return指令外,处理器通常不推荐使用其他类型的间接跳转分支指令,以减少预测失败的风险和提高执行效率。
2、分支预测的常见方式
(1)简单处理器-静态分支预测
对于普通的处理器来说,由于它的流水线深度并不深,一般都是使用静态的分支预测方式,预测分支指令总是不执行,处理器总是顺序地取指令,在流水线的后续阶段,例如执行(execute)阶段,得到了分支指令实际的方向和目标地址后再进行判断。如果分支指令需要发生跳转,则抛弃在分支指令之后进入到流水线的所有指令(或者在MIPS中,在这些流水段放上不相关的指令,即branch delay slot);如果分支指令不需要发生跳转,则继续顺序地取指令来执行。
对于流水线比较短的简单处理器,分支预测失败时并不会引起流水线中过多的指令被抛弃。例如MIPSR3000使用了一个五级的流水线,在流水线的第二个阶段,即解码(decode)阶段,就可以得到分支指令的结果,此时即使分支指令需要发生跳转,流水线中只有取指令(fetch)阶段的一条指令需要被抛弃,如图1所示。
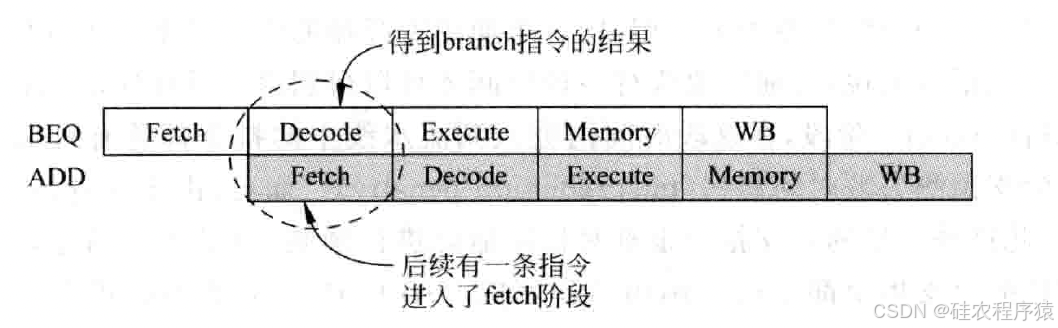
MIPS处理器为了减少这一个周期的浪费,在分支指令之后会放置一条不相关的指令,这条指令总是会被执行,而不管分支指令是否发生跳转。分支指令之后的那个位置就被MIPS称为分支延迟槽(branch delay slot),需要编译器(compiler)或者程序员从分支指令之前的程序中找到不相关的指令放到延迟槽的位置。
(2)复杂处理器-动态分支预测
随着处理器并行度的提高以及流水线的加深,这种只是预测分支指令不发生跳转的静态分支预测算法已经不能够满足复杂处理器对性能的要求,需要能够根据处理器实际的执行情况,动态地对分支指令进行预测,这就是动态的分支预测。
动态分支预测并不会简单地预测分支指令一直发生跳转或者不跳转,而是会根据分支指令在过去一段时间的执行情况来决定预测的结果。如果没有特殊说明,后文中讲述的分支预测算法都是指动态分支预测。
要进行分支预测,首先需要知道从I-Cache取出来的指令中,哪条指令是分支指令,这对于每周期取出多条指令的超标量处理器来说并不容易,需要从指令组(fetch group)中找出分支指令,如图2所示。
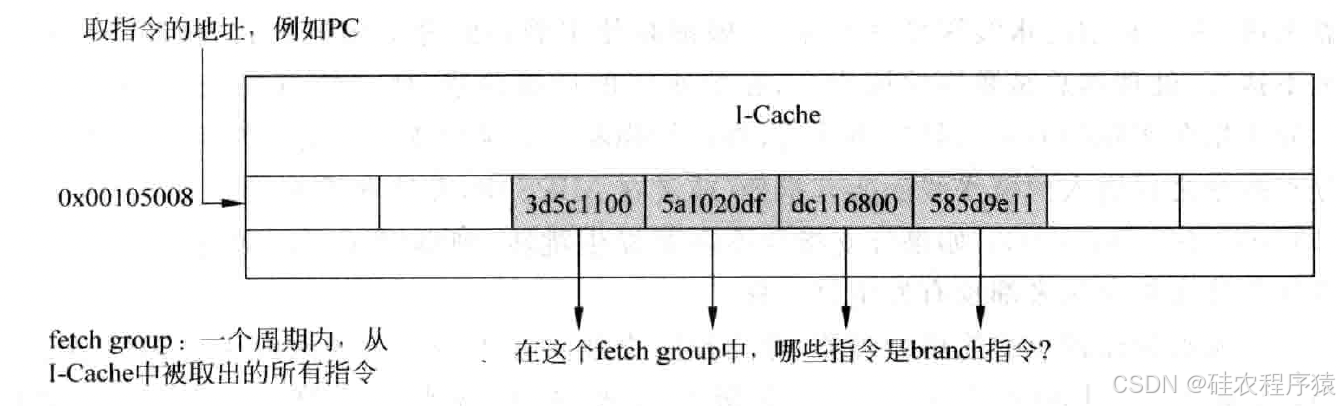
最容易想到的方法就是将指令组中的指令从I-Cache取出来之后,进行快速的解码,之所以称为快速,是因为只需要辨别解码指令是否是分支指令,然后将找到的分支指令对应的 PC值送到分支预测器(branch predictor)中。如图3表示了这个过程。
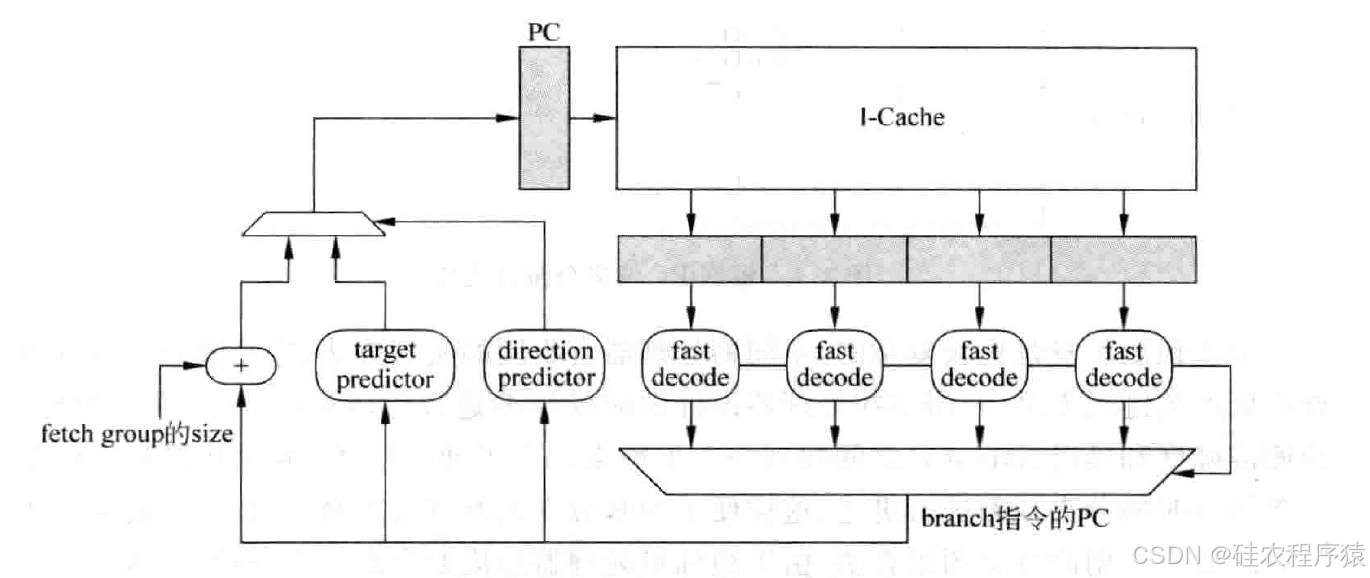
当处理器的周期时间比较小时,I-Cache的访问可能需要多个周期才可以完成,采用图3所示的方式进行分支预测,从开始取指令直到分支预测得到结果,中间需要间隔好几个周期,在这些周期内无法得到准确的预测结果,只能够顺序地取指令,降低了分支预测的准确度,造成了处理器性能的降低。
而且指令快速解码(fast decode)和分支预测的过程都放在了同一个周期,严重影响了处理器的周期时间。为了解决这个问题,可以在指令从L2Cache写入到I-Cache之前进行快速解码,这也被称为预解码(pre-decode),然后将指令是否是分支指令的信息和指令一起写到I-Cache中,这样虽然会使I-Cache占用更多的面积,但是可以省掉图3中的快速解码电路,一定程度上缓解对处理器周期时间的影响。但是,取指令直到分支预测得到结果这两个阶段的间隔时间仍然是过长的,无法得到解决。
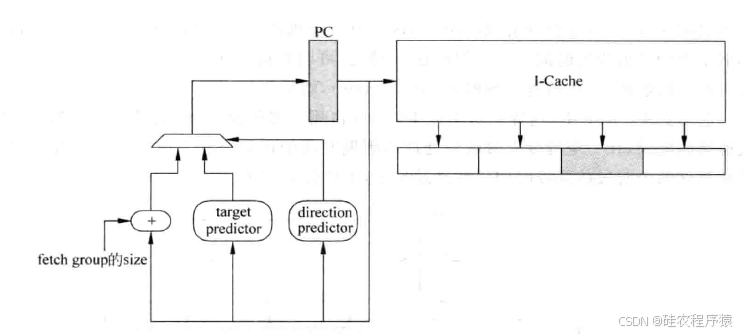
在流水线中,分支预测是越靠前越好,分支预测的最好时机就是在当前周期得到取指令地址的时候,在取指令的同时进行分支预测,这样在下个周期就可以根据预测的结果继续取令。
对于一条指令,它的物理地址是会变化的(这取决于操作系统将它放到物理内存的位置),而它的虚拟地址,也就是 PC值,是不会变化的。所以使用PC值进行分支预测,只不过在进行进程切换之后,需要将分支预测器中的内容进行清空,这样可以保证不同进程之间的分支预测不会互相干扰。如果使用了ASID,那么可以将它和PC值一起进行分支预测,此时就不需要在进程切换时清空分支预测器了。
在PC值产生的那个周期,根据这个PC值来预测本周期的指令组(fetch group)中是否存在分支指令,以及分支指令的方向和目标地址,这个过程如图4所示。
二、分支指令的方向预测
对于分支指令来说,它的方向只有两个可以用1和0来表示。而且,很多分支指令的方向是有规律可循的。
for ( i= 0; i<1000;i++)
{循环体}上面这个for 语句,会执行1000次循环体的内容,这个for语句会被编译器变成一条分支指令,这个分支指令会向同一个方向执行1000次(例如执行1000次跳转,最后一次是不跳转),因此对于这条分支指令来说,它的方向是有规律的。
动态分支预测的一个主要方面就是对分支指令的方向进行预测,最简单的动态预测方法是直接使用上次分支的结果,这种方法也称为根据最后一次的结果进行预测(last-outcome prediction),这种方法如图5所示。
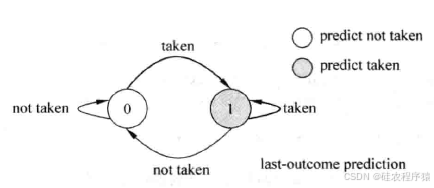
相比于静态分支预测,这种方法在很多情况下都可以获得更优的结果,但是当分支指令的方向发生变化时,仍会引起分支预测失败(mis-prediction),如图6所示。
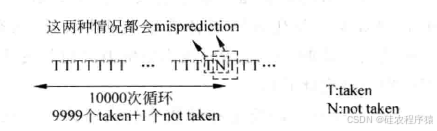
在图6中,分支指令每执行10000次,就会发生两次分支预测失败,因此分支预测的失败率是2/10000=0.002%,看起来似乎已经很不错了,但是一条分支指令有着如图7所示的执行情况时呢?
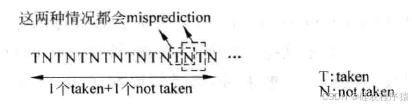
由于图7中的分支指令的方向每次都发生变化,使用最后一次执行的结果进行分支预测的方法,它的失败率将是100%!
此时预测准确度反而比不上静态分支预测的方法,因为对于图7所示的例子来说,静态分支预测的方法是50%的失败率。很显然,这种使用最后一次结果进行分支预测的方法,它的准确度是无法接受的。现代处理器中应用最广泛的分支预测方法都是基于两位饱和计数器(2-bit saturating counter),并以之为基础,引申出的各种分支预测的方法。
1、基于两位饱和计数器的分支预测
基于两位饱和计数器的分支预测方法并不会马上使用分支指令上一次的结果,而是根据一条分支指令前两次执行的结果来预测本次的方向。这种方法可以用一个有着4个状态的状态机来表示,这四个状态分别如下。
Strongly taken:计数器处于饱和状态,分支指令本次会被预测发生跳转(taken),编码为11;
Weakly taken:计数器处于不饱和状态,分支指令本次会被预测发生跳转(taken),编码为10;
Weakly not taken:计数器处于不饱和状态,分支指令本次会被预测不发生跳转(not taken),编码为01;
Strongy not taken:计数器处于饱和状态,分支指令本次会被预测不发生跳转(not taken),编码为00。
整个状态机如图8所示。
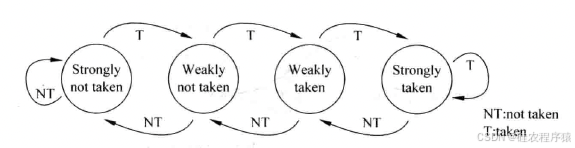
状态机处于饱和状态时,只有两次预测失败才会改变预测的结果。当分支指令的方向总是朝着同一个方向时,例如总是发生跳转或者总是不发生跳转,状态机就会处于饱和状态,此时预测的正确率就是比较高的;但是当分支指令的方向总是变化时,状态机就无法处于饱和状态,此时预测正确率就会比较低。
如图8所示的状态机只是基于两位饱和计数器的众多预测方法中的一种,这种实现方式是应用最广泛的。事实上,这个状态机有其他的很多种实现方式,下面给出其他两种可能的方式。
对于一般的基准测试(benchmark)程序,图9所示的状态机并不会取得更优的结果。而对于状态机的初始状态,其实是可以位于四个状态中的任意一个,需要根据实际的情况来决定,一般来讲,都是使用Strongly not taken或者Weakly not taken 作为初始态。
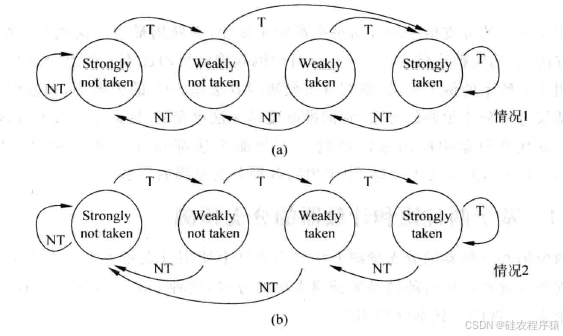
使用格雷码对状态机进行编码可以减少出错的概率,并降低功耗。在两个饱和的状态(Strongly not taken或者Strongly taken),计数器达到了最大值或最小值,此时分支指令的方向如果继续保持不变时,就会使状态停留在原地,不会再发生变化,相当于“饱和”了,这也是饱和计数器名称的由来。这种方法的正确率要优于之前讲述的基于上一次结果的分支预测方法。
考虑下面的C代码:
for ( i= 0; i<m;i++
{循环体}当这个for循环第一次执行时,状态机处于Weakly not taken状态(假设状态机复位时处于此状态),因此会预测分支指令是不发生跳转的,显然这个预测是错误的,因此for循环的第一次会发生预测失败,这会使状态机跳转到Weakly taken状态(最后会稳定在 Strongly taken状态),因此在for循环的第二次直到第m-1次,分支预测都是正确的。在 for 循环的最后一次会产生一次错误的预测,因为此时应该不发生跳转了,而状态机会预测发生跳转(此时状态机处于饱和的Strongly taken状态),这会使状态机跳转到Weakly taken状态。因此,在第一次执行整个for循环时,产生了两次预测错误,出错的概率为2/m,如果m值很大,则两次的出错是可以忍受的。
当再次执行这个for循环体时,for循环的第一次执行就会预测正确了。因为此时的状态机处于Weakly taken状态,仍旧是预测发生跳转的,这会使状态机跳转到饱和的 Strongly taken状态,故for循环体的第二次到第m-1次也仍旧是预测正确的,只有for循环的最后一次才发生了预测错误,此时出错的概率降为1/m。
由上面的执行过程可以看出,使用基于两位饱和计数器的分支预测,核心的理念就是当一条分支指令连续两次执行的方向都一样时,那么该分支指令在第三次执行时也会有同样的方向;如果一条分支指令只是偶尔发生了一次方向的改变,那么这条分支指令的预测值不会马上跟着改变,因此这种方式的分支预测就好像是有一定时间的延迟一样,分支方向偶尔的变化将会被过滤掉。
对于绝大多数程序来说,使用这种基于两位饱和计数器的分支预测方法,就已经可以获得比较高的正确率了,主流的处理器一般都是基于两位的饱和计数器来实现分支预测的。
分支预测都是以PC值为基础进行的,每一个PC值都应该对应一个两位的饱和计数器(也就是每条指令都对应一个饱和计数器)。因此,对于32位的PC值来说,共需要X2b大小的存储器来存储这些计数器的值(指令是字对齐,所以不考虑 PC值的最低两位),显然实际芯片当中无法使用这么大的存储器。考虑到并不是所有的指令都是分支指令,一般使用图10所示的方法来存储两位饱和计数器的值。
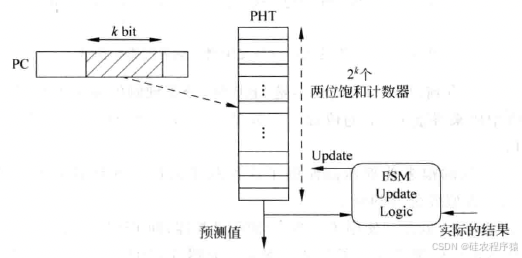
在图10中,PHT(Pattern History Table)是一个表格,其中存放着所有PC值(此处是PC值的一部分)对应的两位饱和计数器的值。这个PHT使用PC值的一部分来寻址,例如图10中使用PC值当中的k位来寻址PHT,因此PHT的大小就是X2bit。
但是,使用这种方式来寻址PHT必然就导致了k部分相同的所有PC值都使用同一个两位饱和计数器的值。如果这些PC值对应的指令中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









