





还是个人收藏啊
在训练 coco 数据集时,训练集就有 11 万张,训练一个 epoch 就要将近 100 分钟,训练 100 个 epoch,就需要 7 天!这实在是太慢了。
经过观察,发现训练时 GPU 利用率不是很稳定,每训练 5 秒,利用率都要从 100% 掉到 0% 一两秒,初步判断是数据读取那块出现了瓶颈。于是经过调研和实验,制定了下列解决方案。
解决方案
(1)prefetch_generator
使用 prefetch_generator 库在后台加载下一 batch 的数据。
安装:
使用:
然后用 DataLoaderX 替换原本的 DataLoader。
提速原因:
原本 PyTorch 默认的 DataLoader 会创建一些 worker 线程来预读取新的数据,但是除非这些线程的数据全部都被清空,这些线程才会读下一批数据。
使用 prefetch_generator,我们可以保证线程不会等待,每个线程都总有至少一个数据在加载。
(2)data_prefetcher
更新:经评论区提醒,有同学在用这个技术的时候遇到显存溢出的问题,见 apex issues ,大家用的时候注意一下。
使用 data_prefetcher 新开 cuda stream 来拷贝 tensor 到 gpu。
使用:
然后对训练代码做改造:
(3)把内存当硬盘
把数据放内存里,降低 io 延迟。
使用:
然后把数据放挂载的目录下,即可。
- size 指定的是 tmpfs 动态大小的上限,实际大小根据实际使用情况而定;
- 数据不一定放在物理内存中,系统根据情况,有可能放在 swap 的页面,swap 一般是在系统盘;
- 重启或者断电后数据全部清空。
如果想系统启动时自动挂载,可以编辑 /etc/fstab,在最后添加如下内容:
(4)设置num_worker
DataLoader 的 num_worker 如果设置太小,则不能充分利用多线程提速,如果设置太大,会造成线程阻塞,或者撑爆内存,反而导致训练变慢甚至程序崩溃。
他的大小和具体的硬件和软件都有关系,所以没有一个统一的标准,可以通过一些简单的实验来确定。
我的经验是设置成 cpu 的核心数或者 gpu 的数量比较合适。
(5)优化数据预处理
主要有两个方面:
- 尽量简化预处理的操作,使用 numpy、opencv 等优化过的库,多多利用向量化代码,提升代码运行效率;
- 尽量缩减数据大小,不要传输无用信息。
(6)其他
- 使用 TFRecord 或者 LMDB 等,减少小文件的读写;
- 使用 apex.DistributedDataParallel 替代 torch.DataParallel,使用 apex 进行加速;
- 使用 dali 库,在 gpu 上直接进行数据预处理。
实验
分别用不同的提速方法做实验,来定量地分析提速的效果。为了快速实验,采用了 5000 张的小批量训练集,确保一次 epoch 的训练时间很短。
实验一:
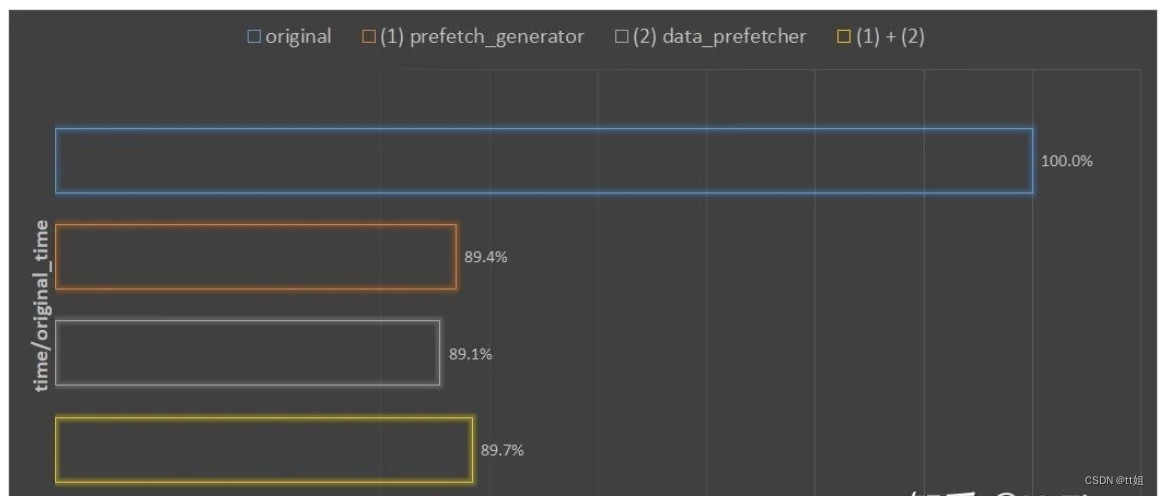
在 hdd 硬盘上,用同样的参数、同样的数据,分别用不同的优化方法,训练两个 epoch,记录训练的时间。
优化方法分别是:
- original:默认 dataloader,不优化
- (1)prefetcher_generator:只用 prefetcher_generator 库优化
- (2)data_prefetcher:只用 data_prefetcher 优化
- (1)+(2):同时用 prefetcher_generator 和 data_prefetcher 优化
最后将得到的时间,除以不优化时的训练时间。
从图中可以观察到:
- (1) 和 (2) 两种优化方法都差不多有 10% 左右的训练时间的缩短;
- (1) (2) 同时使用,并没有进一步缩短训练时间,反而不如只使用一种优化方法。
实验二:
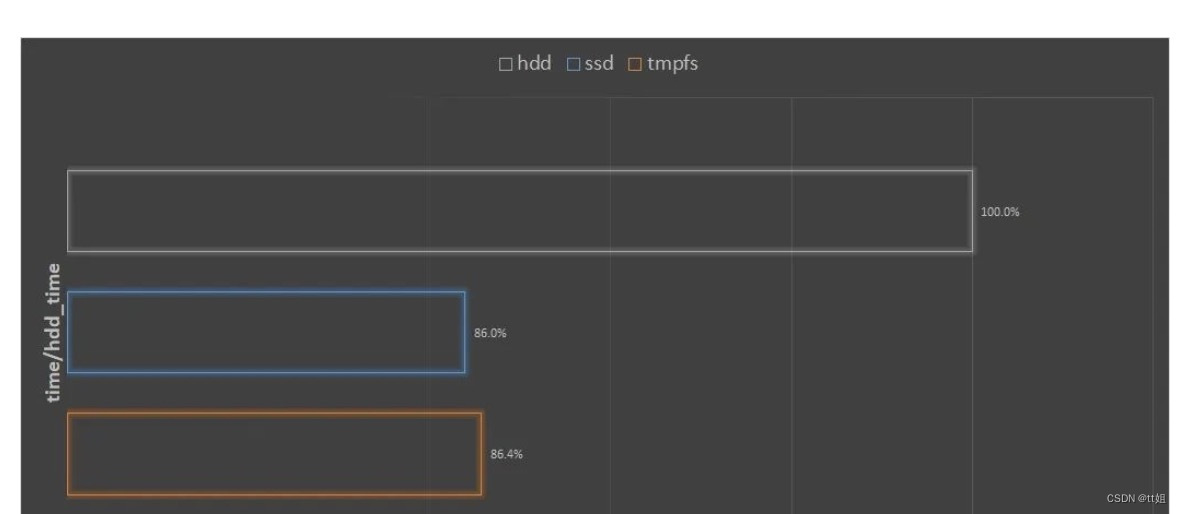
用同样的参数、同样的数据,用默认的 dataloader,数据分别在 hdd、ssd 和 tmpfs 内存上进行训练两个 epoch,记录训练时间。
最后时间统一除以在 hdd 上的训练时间。
从图中可以观察到:
- 将数据从 hdd 挪到 ssd 或者内存上,训练时间都有 14% 左右的缩短;
- 在 tmpfs 上训练并不比在 ssd 上快,可能的原因是数据太大,训练时并没有放在物理内存上,而是放在 swap 上,而这台机器 swap 也是在ssd上,所以速度差不多。
实验三:
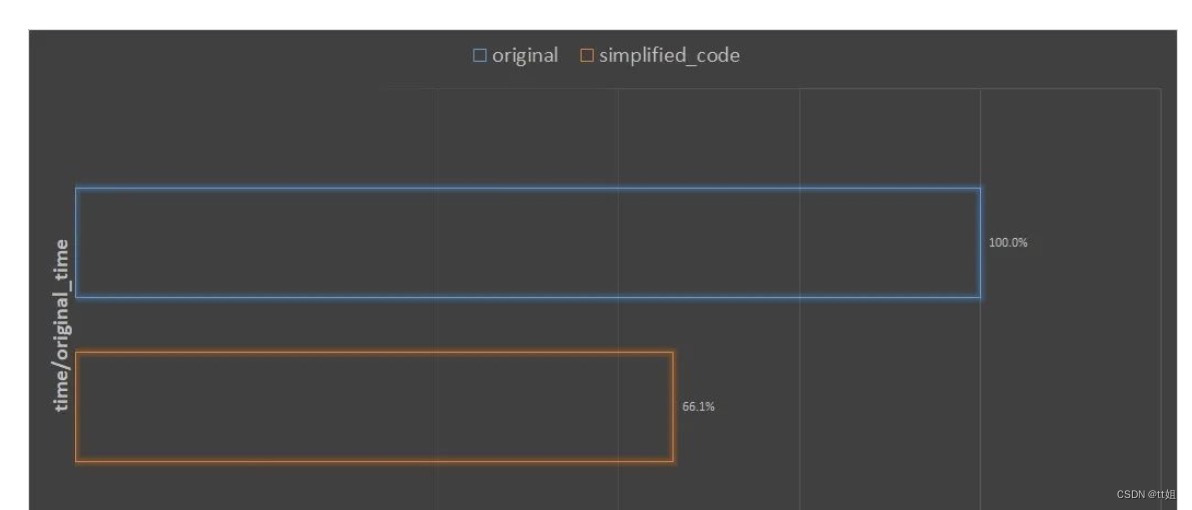
优化数据预处理代码,尽量用向量化代码,缩减数据传输大小,分别在 hdd 上,用默认 dataloader 训练。 whaosoft aiot http://143ai.com
如图,训练时间缩短了接近 34%!可见,在之前的代码中,主要是预处理部分拖慢了整体的训练速度。
总结
以上定量地分析了各加速方法的效果,当然如果各方法都用上,最后的加速比例不是简单叠加的。
最后,我将数据放在 ssd 上、用了 (1) 或者 (2) 的优化方法、优化了数据预处理代码后,最后使得训练时间缩短了 39%!也就是说,如果原来训练一个模型需要 7 天,现在需要 4 天半,节省了 2 天半的时间。
所谓磨刀不误砍柴工,建议大家在正式训练前,花一点时间排查一下训练的瓶颈,尽量提升训练的速度,这是一劳永逸的,将在后面节省大量的时间,是非常值得的。
参考
- Should we use BackgroundGenerator when we’ve had DataLoader?
- Dose data_prefetcher() really speed up training?
- 如何给你PyTorch里的Dataloader打鸡血
- 把内存当硬盘,提速你的linux系统
- Guidelines for assigning num_workers to DataLoader
- How to prefetch data when processing with GPU?















 113
113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









